本文主要是介绍Flink Keyed State的优化与实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本期作者

1.背景
Flink SQL在业务使用中有较多的双流join场景,当左右流的流量都较大,Join的等待时间即使为1小时,Flink Keyed State(Flink State分Operator State和Keyed State,后文所有State均代表后者)的存储大小也很容易达到TB级(内部默认使用的是RocksDBStateBackend)。
在State我们内部[1]之前就做了RT和长度的metric,当State的存储达到TB级别后,会发现State的scan/next/readNull请求RT会变得较高,另外双流Join不仅流量大,Join query的字段也较多,导致State的Value长度也较大,从而使得任务在流量高峰期CPU存在明显的周期性毛刺,根因是RocksDB的compaction引发。我们下面的内容主要是从业务场景跟进到RocksDB的读写行为,来优化RT耗时高的问题,并使用优化方案缓解compaction的压力。
2.Flink Keyed State诊断
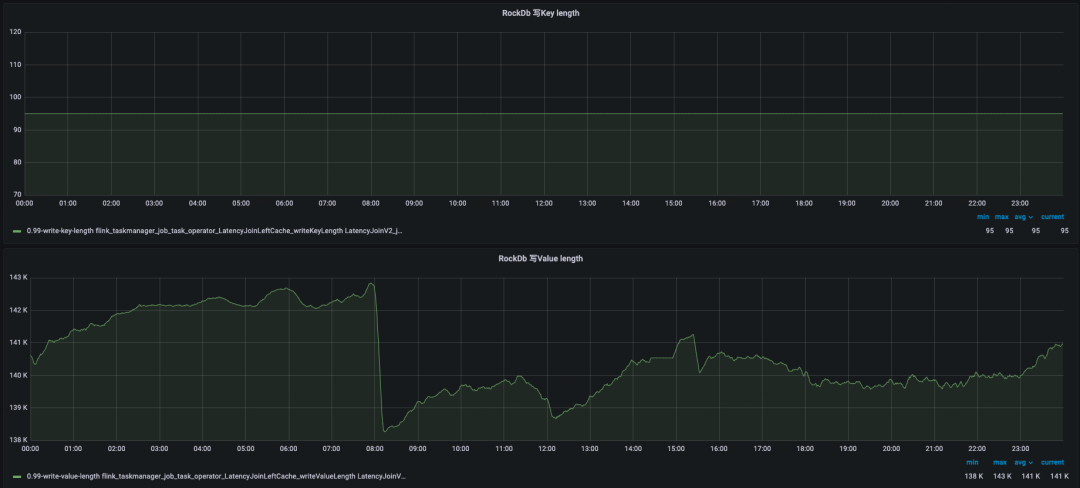
我们统计了内部的TB级别大State任务,其State均由双流Join Operator产生。Flink的双流Join有两类,一类是无时间区间限制的Regular Join,其左右流的State Key在Inner和Outer Join下均会存放单条RowData数据,在监控中会发现Key length普遍较大,这类作业在内部使用数量以及State大小均相对较小。另一类是有时间区间限制的Interval Join,以及内部基于Interval Join实现的延迟弹出数据的Latency Join,其左右流的State在大State任务中Key很小,而Value较大,如下图所示是大State任务LatencyJoin的写KV长度监控。
2.1 双流Join特性
第二类双流Join在内部使用数量和State存储大小均很大,内部的商业和AI这两个业务线中使用得最多,我们着重看一下这类Join在Flink的实现。
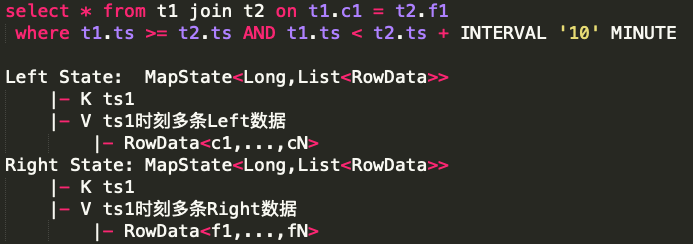
这类双流Join Operator,在Flink中会使用两个State,分别缓存左流和右流的数据,其结构为MapState<long,list>,Key存放的是毫秒时间戳,Value存放的是当前毫秒时刻相同On表达式列下的所有RowData记录,一个RowData就是当前流在Join后需要被Project的所有字段合集。当左右流的一条记录被Project的字段越多,单个RowData存储的字段也就越多,一个RowData的长度由所有Project字段的长度之和决定,大State任务中一般左右流的Project数量和长度均较大,所以也就导致了一个时间戳下即使只有一条RowData,写入RocksDB的List序列化结果也会较长。
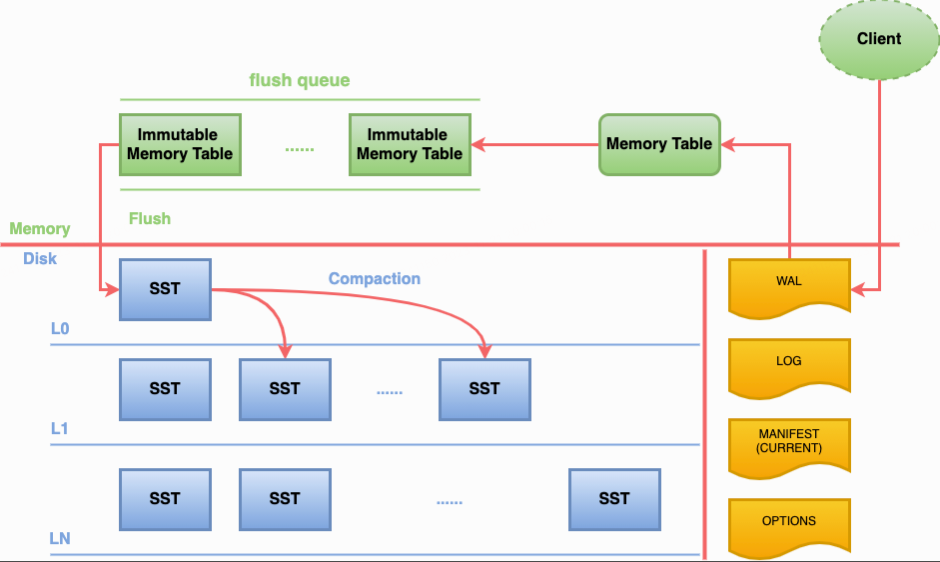
RocksDB的写流程示意图[2]如下,一对KV从client写入RocksDB中,会先写入WAL中(Flink中已关闭WAL),然后写入Memory table中,当Memory Table写满(阈值write_buffer_size=64MB)或主动触发flush(Flink checkpoint触发RocksDB的snapshot)后,会将数据刷入磁盘写入L0层的SST中,当L0层的文件数达到阈值(level0_file_num_compaction_trigger=4)会触发compaction操作,将L0层的所有数据和L1的数据合并并写入到L1中;当L1的存储大小达到阈值(max_bytes_for_level_base=256MB)后会触发compaction,将L1的文件和L2的若干个文件合并并写入L2;在L2及其以后,LN+1的存储大小为LN的10(max_bytes_for_level_multiplier)倍时均会触发compaction向LN+1合并数据。
将任务添加state.backend.rocksdb.log.level=DEBUG_LEVEL配置后会发现,TB级别的双流Join大State任务,RocksDB的SST层级会变成[2,4,41,98,0,0,0],代表着L0至L7中SST文件个数,L3的文件数会十分多,这也是由于双流Join的两个特性决定的,一个是流量特别大,需要记录的KV数量庞大,另一个是前面提到的Value较长,导致整体的存储消耗也会较大,而RocksDB的层级分布,导致较多的数据存储到了L3,层级变多会导致compaction整体耗时变得较高。
2.2 RocksDB读RT高
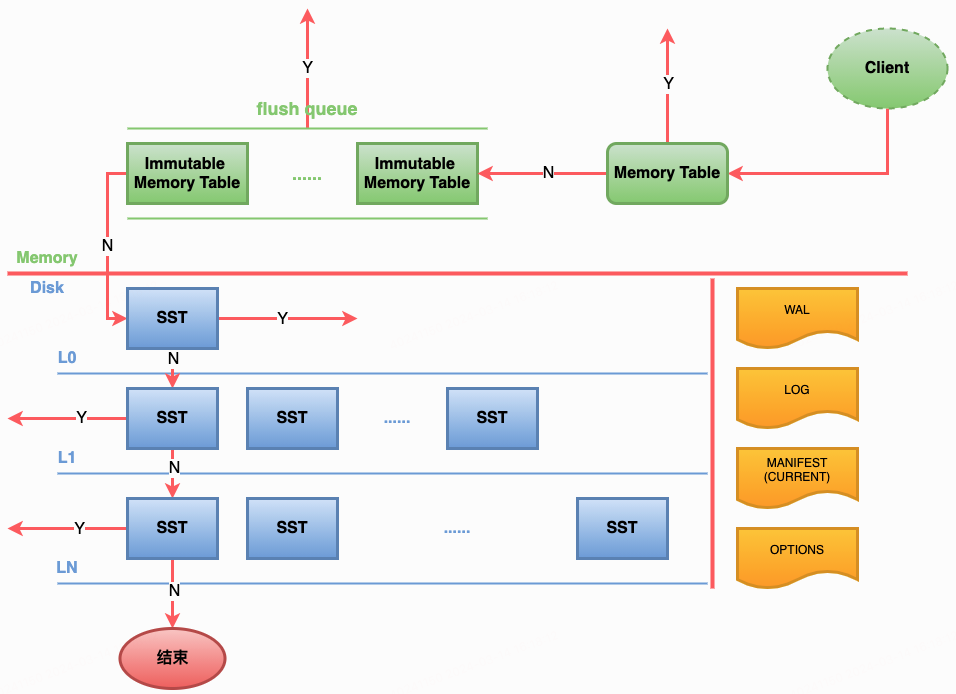
RocksDB的读流程示意图[2]如下,Client读取数据会先从Memory Table中查询,如果没有找到则在磁盘的L0层读取数据,由于在L0层的数据不是全局有序的,所以会依次读取L0层的所有文件。RocksDB的L1至LN每层数据在当前Level内是全局排序的,所有L1至LN中的一个K只会在一个SST文件中,如果L0层未查询到数据,则会依次在L1至LN中每层只查询一个SST文件,直到查询到数据结束。
在前文中我们提到过,双流Join的Key是时间戳,Value存放的是当前时间戳的数据集合List,左右流数据进入到Join Operator会在对应State中做一个Get请求,再将当前RowDate放入List中,随着时间的推移,会存在大量的Get请求击穿RocksDB,我们标记其为ReadNull,与此同时上文中提到双流Join大State的RocksDB L3层的文件数是比较多的,所有的ReadNull请求均会从L0访问至L3结束,整体读耗时是比较高的。
另外这类Join的State是MapState<long,list>结构,会有两个地方调用Map的iterator。一个是对流数据Join当前State的RowData集合,另一个是由Timer State定时触发清理当前State的时间窗口外的数据,否则State会越来越大。而State中Map的iterator调用的是RocksDB的seek和next来查询数据,seek和next操作会将所有满足currentKey的数据遍历出来,同样会读到RocksDB的最底层Level的SST文件。
我们通过监控发现大State的seek、next、readnull等读RT耗时99线比较高,达到了两位数的毫秒级,这对实时流计算来说是不期望看到的结果。
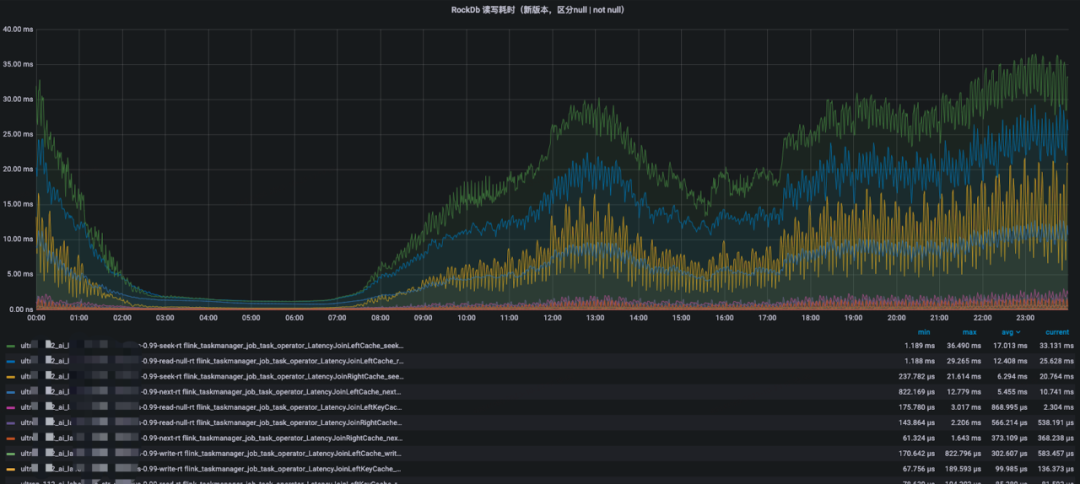
3.State优化
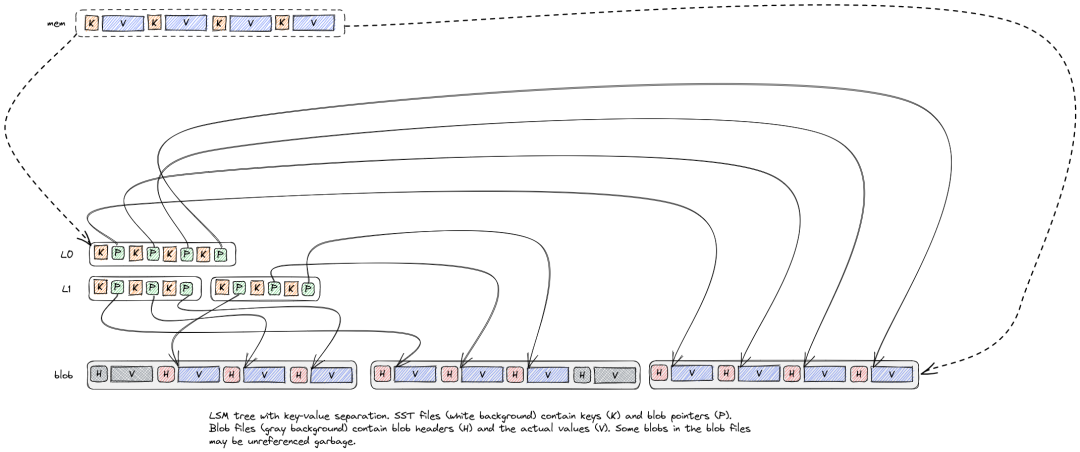
无论是读RT耗时变高,还是compaction导致CPU毛刺,都是因为State中的Value过大,导致SST的层级变多,扫描过多SST文件,读性能也就会有所下降。一条State记录,从L0到LN的过程,不仅会在跨层中被读写,而且在同层中,因其他数据compaction到当层,也会被多次读写,在高level的compaction中会发现磁盘的读写IO之和会达到400MB/s,读写中占比较大的数据是State的Value,如果Value在compaction中不被搬迁移动,那么可以大大降低IO和CPU毛刺,在做调研中发现了RocksDB社区的BlobDB[3]方案。
RocksDB的BlobDB方案来自Wisckey[4]的KV分离,当一对KV被flush落盘时,如果Value长度大于阈值,会将Value写入Blob文件中,SST文件中仅记录Value在Blob的index,在大Value场景下,使用KV分离后SST文件的总大小和层级将会大大的降低。
Flink社区中RocksDB最高版本[5]在去年调研时仅为RocksDB对应的6.20版本,而此版本还无法通过Java调用开启BlobDB,在与内部分布式存储团队沟通后,决定使用他们已线上运行的7.8.3版本来构建Flink的RocksDB,从而来使用BlobDB特性,于是我们将Flink原有的CompactionFilter等实现合并到了7.8.3的release中。
经过适配并在大State中开启KV分离后,观察RocksDB日志发现SST的文件大小急剧下降,State Key也全聚集在了L0和L1这两层中。由于SST层级的降低,ReadNull请求访问到L1层就结束了,而seek和next请求在有数据的情况下,只需要额外访问一次对应的blob文件即可,若没有数据,对blob的IO读操作也可省略。最后的效果是ReadNull耗时全降到了百微妙左右,scan和next的RT 99线也降到了1毫秒左右。
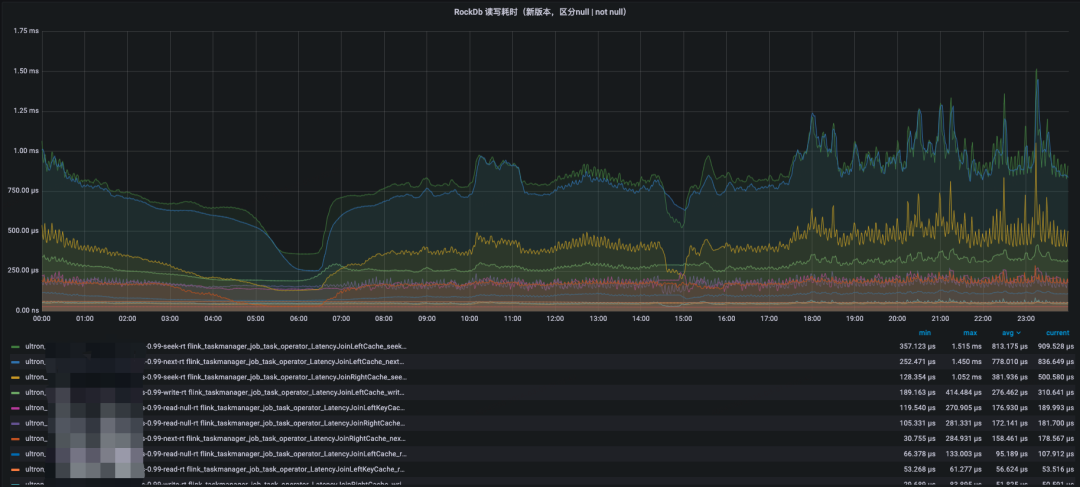
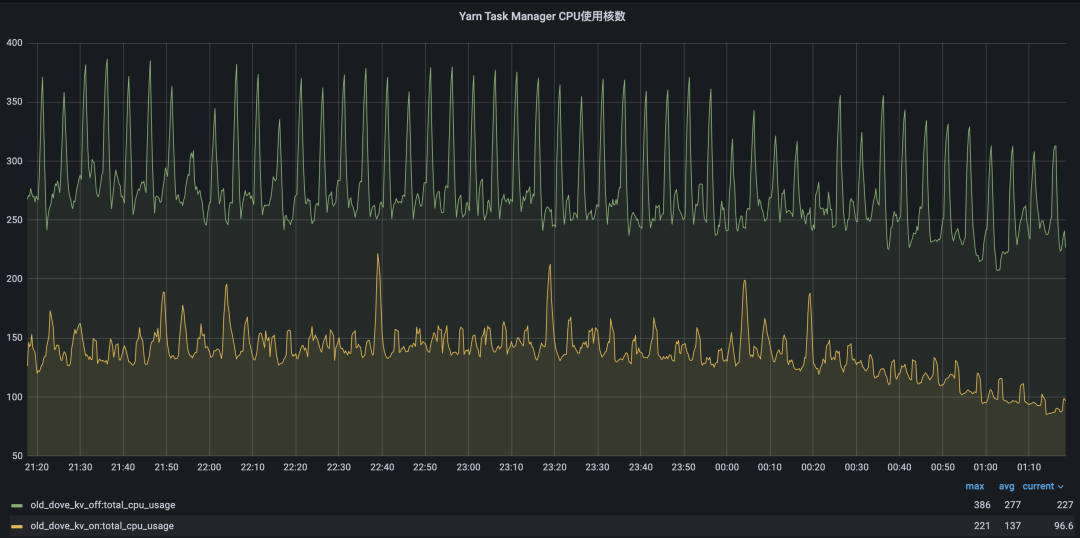
另外我们通过用户Case的双跑任务对比发现,开启KV分离的任务CPU毛刺有所弱化,CPU整体使用降低了50%。任务依旧存在少量的CPU毛刺高峰现象,通过RocksDB日志分析毛刺依旧来源于compaction,虽然SST的层级降低了,但是blob文件的GC还是存在,GC会将blob文件数据做搬迁工作,整合新文件和删除老blob文件,其工作会比较消耗磁盘IO和CPU资源,而blob的GC在现实中是无法关闭的,关闭blob GC会导致存储层文件只增不减。即使compaction依旧存在,我们也是享受到了升级RocksDB版本带来的优化的,高毛刺的频率相比老版本来说少了很多了。
4.总结与展望
除了对大State做了KV分离外,小State的有一些任务会存在20min一次周期性毛刺现象,我们引用了分布式存储团队的InnerCompaction[6]补丁,KV长度均很小,L1层存储大小接近max_bytes_for_level_base,四次Checkpoint生成的4个L0层SST向L1层compaction会导致CPU毛刺现象产生,而InnerCompaction的优化原理是L0层的小文件在同层预先做compaction,避免频繁的与L1的数据做合并,防止IO放大。
去年下半年在内部给用户推进Flink State的KV分离功能后,线上所有大State任务的CPU使用率都减少了20-50%。未来可能有如下几个方面会继续推进优化。
a) 将内部高版本Flink中的RocksDB完成升级。
b) Flink做Checkpoint执行到RocksDB层的snapshot是比较轻的,和compaction不强关联的,后续可以考虑降低compaction的速率来达到进一步弱化CPU毛刺现象。
c) 目前内部的KV分离还需要使用一个参数控制开启,后期期望能默认全局开启,KV分离对Value长度大小的阈值也期望能自适应,无需用户感知。
参考:
[1]https://mp.weixin.qq.com/s/E23JO7YvzJrocbOIGO5X-Q
[2]https://blog.csdn.net/microGP/article/details/120416193
[3]https://github.com/facebook/rocksdb/wiki/BlobDB
[4]https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
[5]https://github.com/ververica/frocksdb
[6] https://github.com/bilibili/rocksdb
这篇关于Flink Keyed State的优化与实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






