kakfa专题

Kakfa的核心概念-Replica副本(kafka创建topic并指定分区和副本的两种方式)
Kakfa的核心概念-Replica副本(kafka创建topic并指定分区和副本的两种方式) 1、kafka命令行脚本创建topic并指定分区和副本2、springboot集成kafka创建topic并指定分区和副本2.1、springboot集成kafka2.1.1、springboot集成kafka创建topic并指定5个分区和1个副本2.1.2、往分区中发送消息2.1.3、sprin
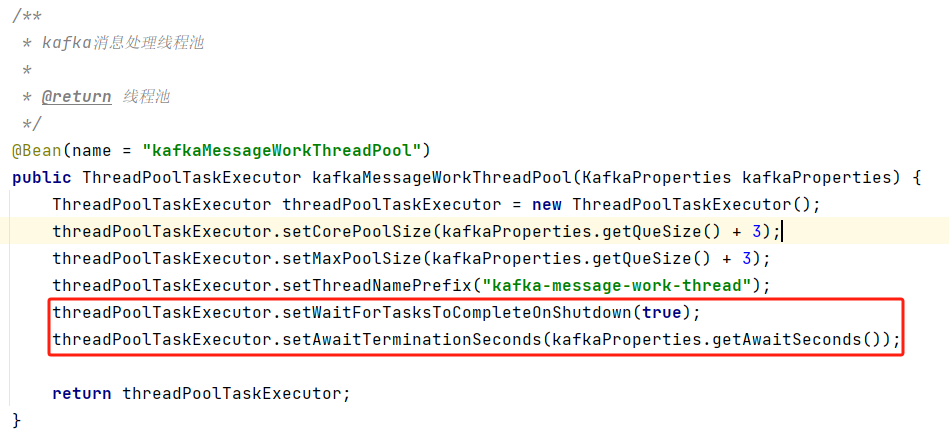
kakfa发版丢消息事件分析
背景 其他部门同事反馈在项目发版/重启(kill -15)的那段时间,经常会出现导致 C 端业务出现问题,从而产生资损 一听资损,赶紧应答下来,了解了下具体情况,然后立马去排查了 问题分析 结合同事的描述以及对业务的了解,很快就定位到是 kafka 消息丢失导致 C 端业务出现问题 业务当前消费架构图 从上图可以了解到几个点会导致目前这个场景消息丢失 kafka 一秒一次的位

zookeeper、kakfa添加用户加密
背景 zookeeper无权限访问到根目录 步骤 在kafka/config 目录中创建 vi config/zookeeper_jaas.conf 在zookeeper_jaas.conf中添加 Server {org.apache.kafka.common.security.plain.PlainLoginModule requiredusername="admin"pass

Apache Kafka(一)- Kakfa 简介与术语
Apache Kafka 1. Kafka简介、优势、以及使用场景 Kafka的优势: 开源分布式,弹性架构,fault tolerant水平扩展: 可以扩展到100个brokers可以扩展到每秒百万级条消息高性能(延迟少于10ms)-- 实时 使用场景: 消息系统活动追踪(Activity Tracking)从各个不同的地点收集指标信息(IOT)应用日志收集流处理(使用Kafka Stre

Kafka【问题 01】kill -9 导致 Kakfa 重启失败问题处理(doesn‘t match stored clusterId xxx in meta.properties)
1.报错信息 The Cluster ID xxx doesn't match stored clusterId Some(yyy) in meta.properties 2.问题处理 通过查询 server.properties 的 log.dirs 配置找到 meta.properties。 cat ./server.propertieslog.dirs=/xxx 或使用 fi

kakfa模拟仿真篇之spark-submit在linux运行 (更贴近真实场景)
源码在上篇 地址在这 :Kafka模拟器产生数据仿真-集成StructuredStreaming做到”毫秒“级实时响应StreamData落地到mysql-CSDN博客 这里分享一下一些新朋友不知道spark-submit 指令后 的参数怎么写 看这篇绝对包会 声明: 此项目是基于 maven 打包的说明,不是SBT哦 先分享一下我的原指令吧: bin/spark-submit --
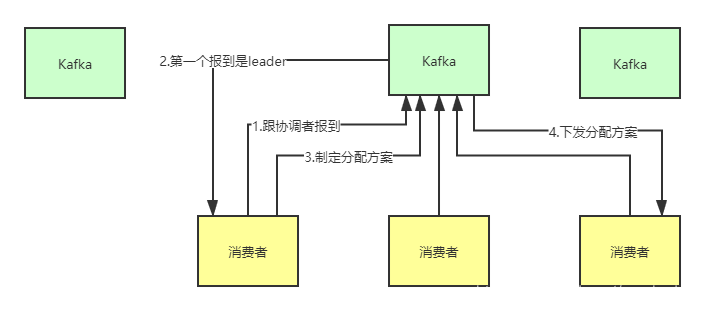
kakfa消费者组集群化原理
kakfa消费者组集群化原理 kafka怎样选出leader消费者?一、怎样为每个消费者组选择出唯一协调者?从源码看看怎样选出唯一的协调者?总结 二、协调者从消费者组中选出leader消费者这个leader消费者的职责是什么?leader consumer如何和非leader节点的consumer进行通信?为什么采取协调者这种机制,还有其他方案吗? 总结 kafka怎样选出le
一个用Kakfa低级api的SparkStreaming程序实例
spark2.4以后可以用structStreaming 低级api消费:KafkaUtils.createDirectStream方式 这种方式不同于Receiver(高级api)接收数据,它定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者Api(低级api)读取

三十:Kakfa模拟Json数据生成和发送
在计算 PV 和 UV 的过程中关键的一个步骤就是进行日志数据的清洗。实际上在其他业务,比如订单数据的统计中,我们也需要过滤掉一些“脏数据”。 所谓“脏数据”是指与我们定义的标准数据结构不一致,或者不需要的数据。因为在数据清洗 ETL 的过程中经常需要进行数据的反序列化解析和 Java 类的映射,在这个映射过程中“脏数据”会导致反序列化失败,从而使得任务失败进行重启。在一些大作业中,重启会导致任
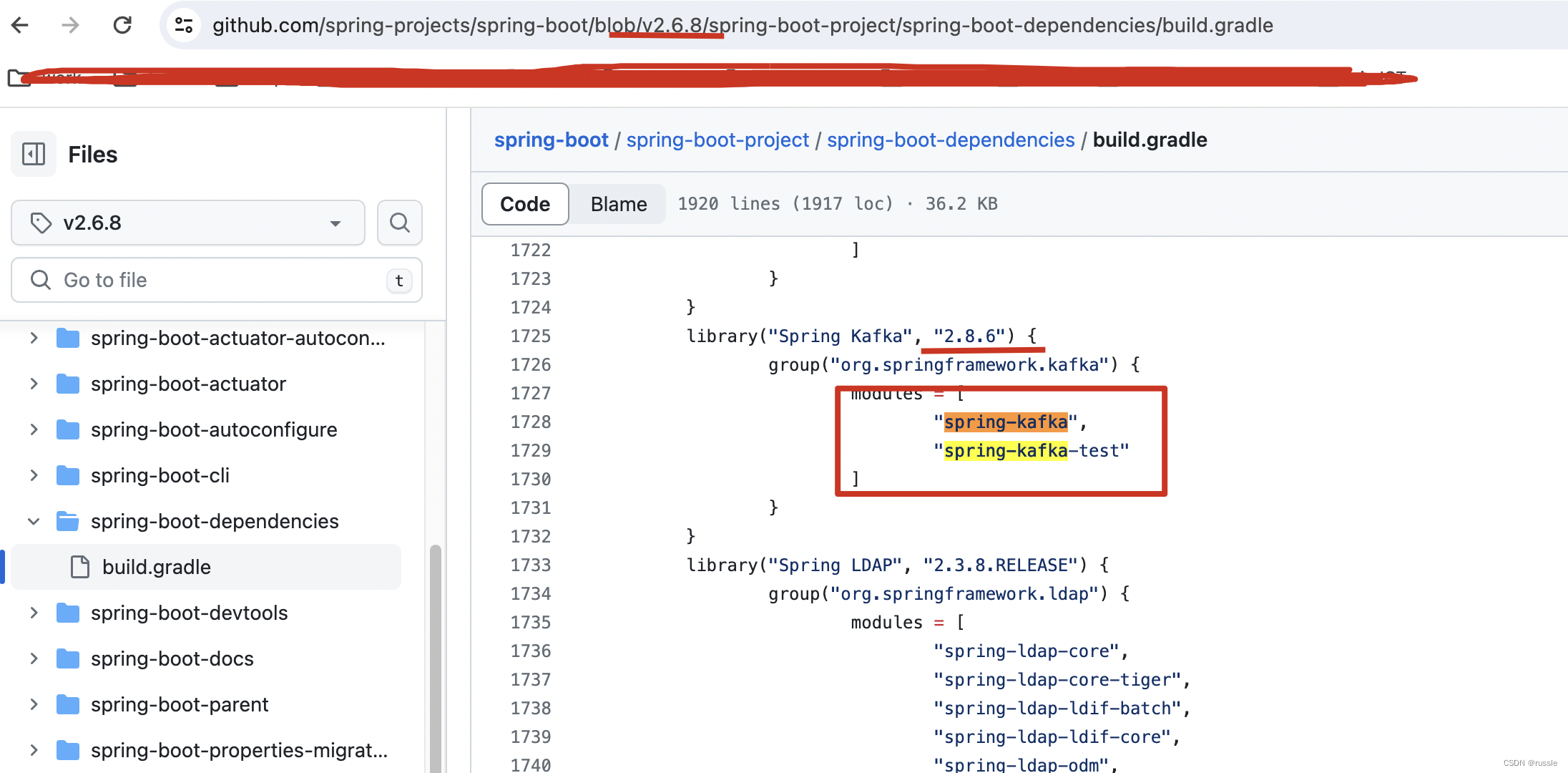
spring-kakfa依赖管理之org/springframework/kafka/listener/CommonErrorHandler错误
问题: 整个项目使用spring-boot2.6.8版本,使用gradle构建,在common模块指定了implementation 'org.springframework.kafka:spring-kafka:2.6.8’这个工程也都能运行(这正常发送kafka消息和接收消息),但是执行单元测试报错,报错信息如下: ... 86 moreCaused by: java.lang.NoCl

kakfa的维护:Brock停止
错误1:kakfa的Brock停止 org.apache.spark.SparkException: Couldn’t find leader offsets for Set() 原因: 1、TopicName复制数Replication为1; 2、TopicName的Partitions一部分落在Brock上面,而这个Brock没有复制数,导致Partitions丢失 北京小辉微信
kakfa实战指引-实时海量流式数据处理
前言 我们最终决定从头开始构建一些东西。我们的想法是,与其专注于保存成堆的数据,如关系数据库、键值存储、搜索索引或缓存,不如专注于将数据视为不断发展和不断增长的流,并围绕这个想法构建一个数据系统——实际上是一个数据架构。 事实证明,这个想法的适用范围比我们预期的要广泛。尽管 Kafka 最初是在社交网络的幕后为实时应用程序和数据流提供支持的,但现在您可以在每个可以想象的行业中看到它成为下一代

Spring Kafka 教程 – spring读取和发送kakfa消息
Apache Kafka, 分布式消息系统, 非常流行。Spring是非常流行的Java快速开发框架。将两者无缝平滑结合起来可以快速实现很多功能。本文件简要介绍Spring Kafka,如何使用 KafkaTemplate发送消息到kafka的broker上, 如何使用“listener container“接收Kafka消息。 1,Spring Kafka的组成 这一节我们首先介绍Sprin