本文主要是介绍kakfa消费者组集群化原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
kakfa消费者组集群化原理
- kafka怎样选出leader消费者?
- 一、怎样为每个消费者组选择出唯一协调者?
- 从源码看看怎样选出唯一的协调者?
- 总结
- 二、协调者从消费者组中选出leader消费者
- 这个leader消费者的职责是什么?
- leader consumer如何和非leader节点的consumer进行通信?
- 为什么采取协调者这种机制,还有其他方案吗?
- 总结
kafka怎样选出leader消费者?
本文主要介绍 kafka consumer组是通过什么机制,选择出leader和follower消费者?
一、怎样为每个消费者组选择出唯一协调者?
从源码看看怎样选出唯一的协调者?
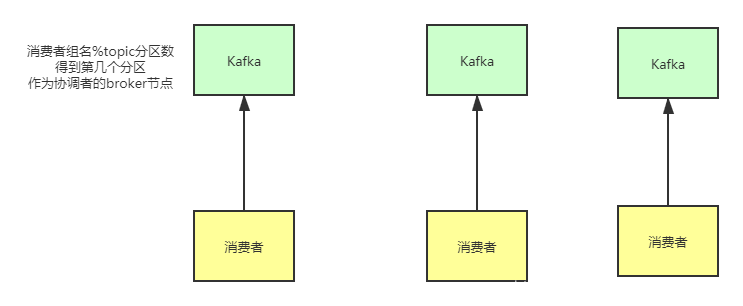
每个消费者,分别随机找一个broker进行通信,询问这个broker的找出该消费者组的协调者是谁。
如何做到这步:consumer内部一个coordinator类,负责消费者协调工作。
coordinator.ensureCoordinatorReady(),发送寻找组协调者的请求sendGroupCoordinatorRequest,消息类型是 GROUP_COORDINATOR
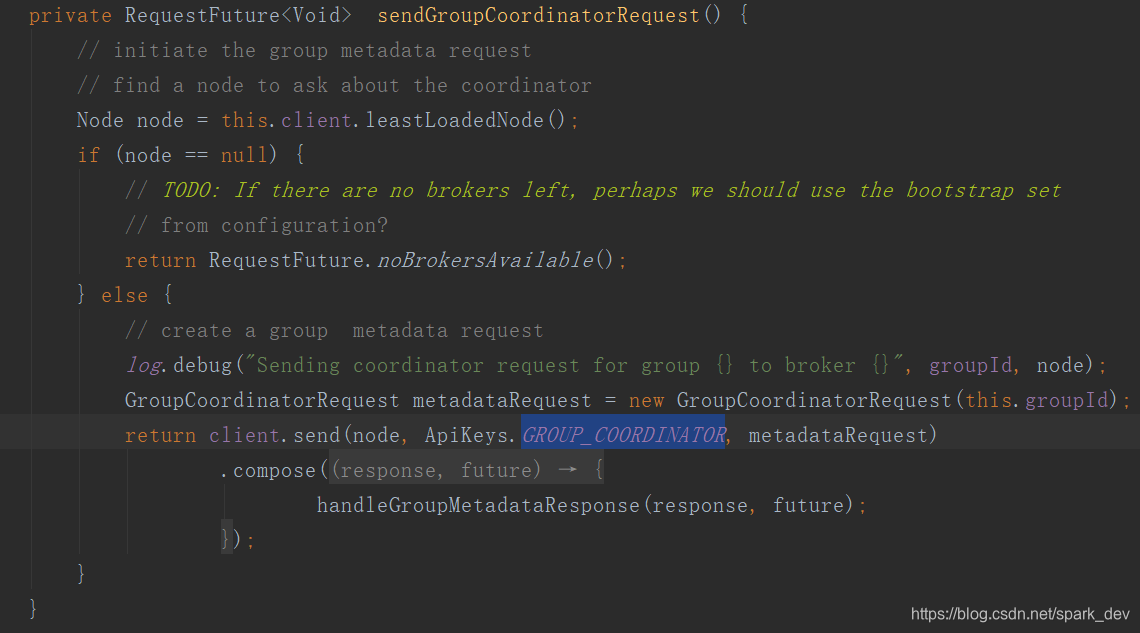
broker收到请求后, kafkaApis进行处理:
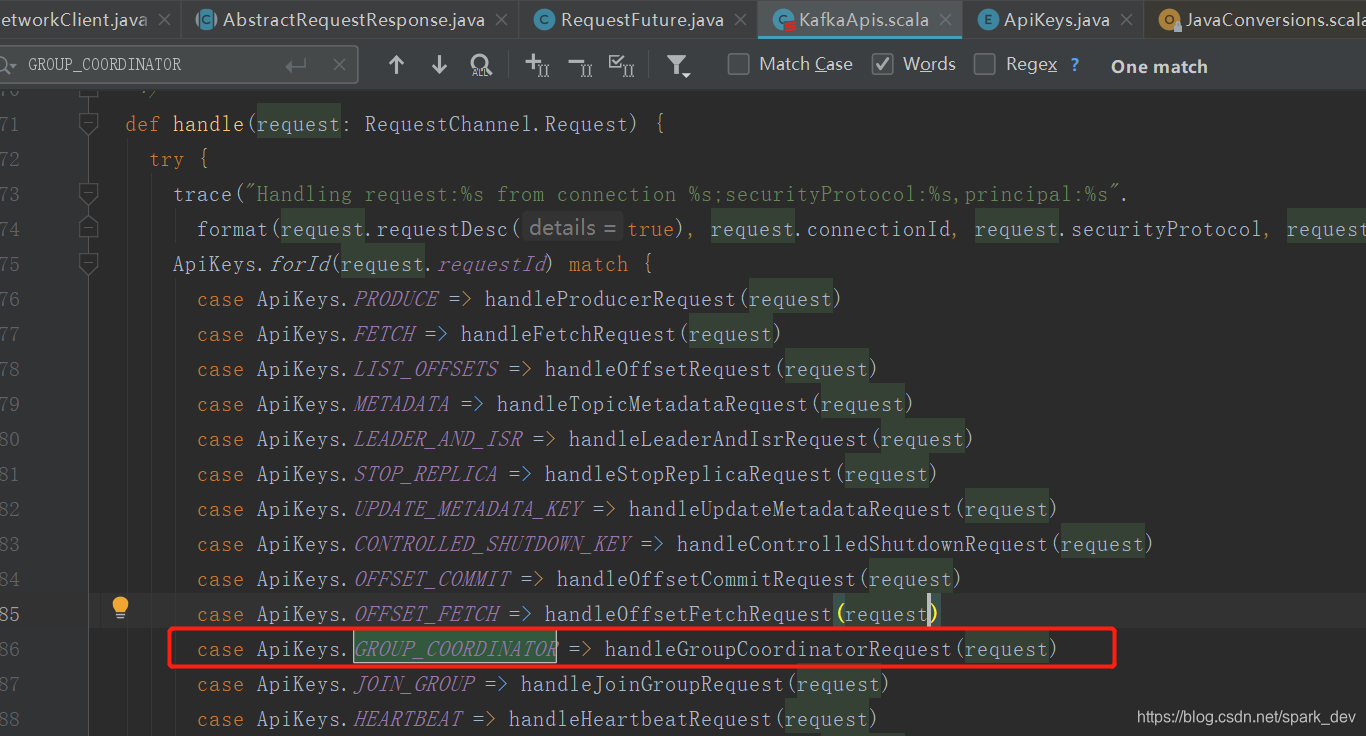
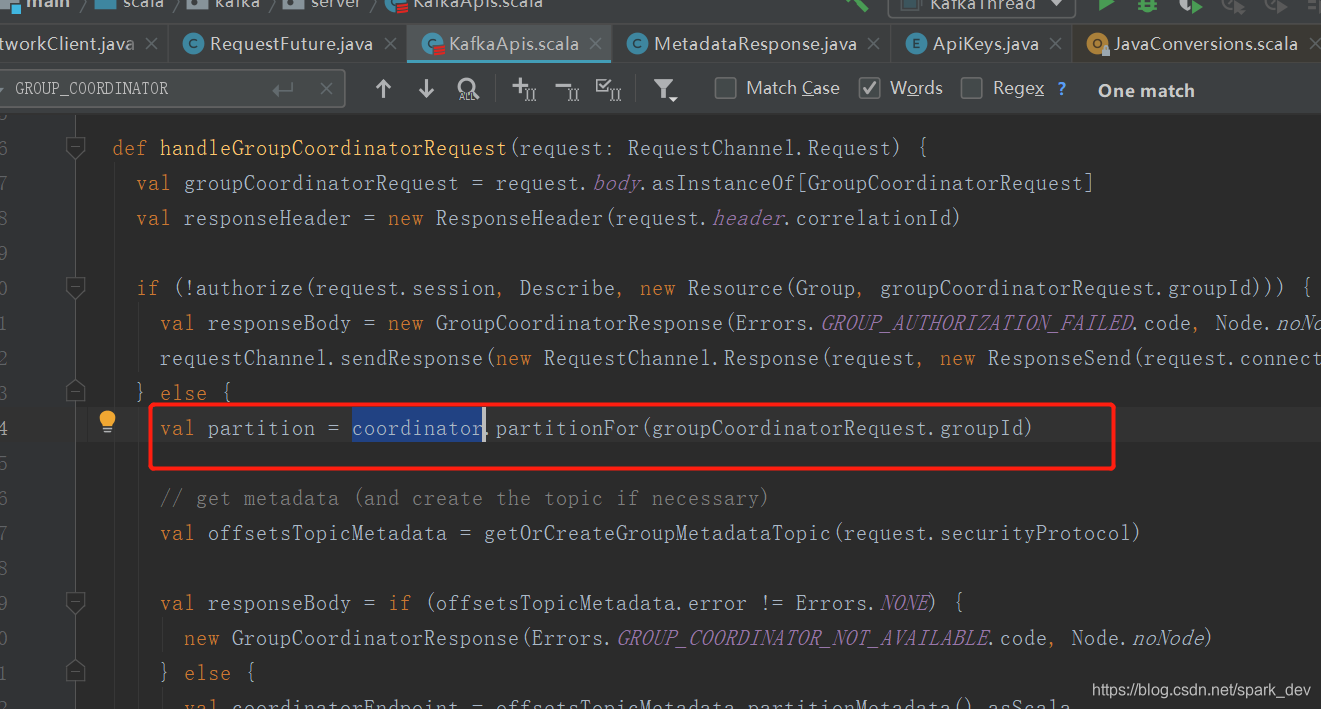
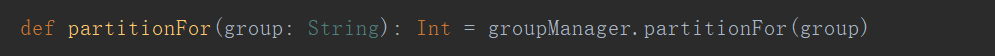

总结
意思是:使用组名称的hash值%这个topic的分区数量,得到指定的一个分区,这个分区leader所在节点就是组协调者的节点,所有消费者计算出的协调者节点都是一样的
二、协调者从消费者组中选出leader消费者
这个leader消费者的职责是什么?
leader消费者的职责: 制定消息消费的方案,发给协调者的broker
非leader的消费者:协调者通知它是follower,就发消息给协调者,等待分区分配
协调者:收到leader分配方案,等待所有本组消费者到期,分配消息消费方案
leader consumer如何和非leader节点的consumer进行通信?
通过协调者broker
为什么采取协调者这种机制,还有其他方案吗?
consumer之间没有直接通信,降低架构发复杂度
其他方案:如果不进行新的技术,采用在zk上精选leader也是可以的,缺点:zk的读写就会变多,选举压力转移到zk上。
总结
提示:这里对文章进行总结:
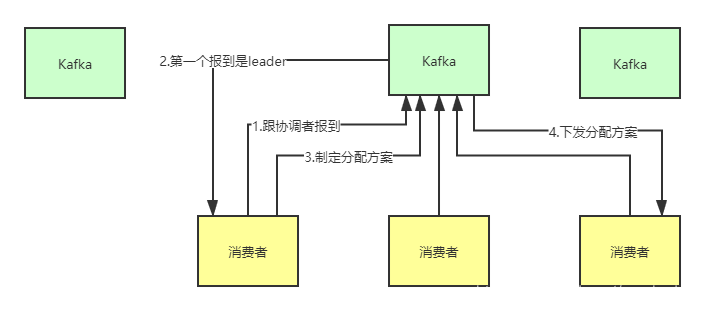
选举主消费者是通过broker协调者,broker协调者选举leader,leader指定消息消费方案,下发给协调者,协调者把方案下发给所有消费者(包括leader消费者)。
与现实生活对照就像:选举一个领导,leader消费者是二把手,二把手指定任务计划,提交给领导,领导再下发任务,二把手也要干活。
这篇关于kakfa消费者组集群化原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






