impala专题

CDH集群中Impala 使用的端口
下表中列出了 Impala 是用的 TCP 端口。在部署 Impala 之前,请确保每个系统上这些端口都是打开的。 组件 服务 端口 访问需求 备注 Impala Daemon Impala 守护进程前端端口 21000 外部 被 impala-shell, Beeswax, Cloudera ODBC 1.2 驱动 用于传递命令和接收结果。参见 Confi
Apache Impala 4.4.1正式发布了!
Impala 4.4.1是一个维护性发布,主要修复Impala 4.4.0的一些问题。下面简要列举一些改动,完整的ChangeLog可参考 https://impala.apache.org/docs/changelog-4.4.1.html Impala 4.4.0的新功能可参考上一篇文章:Apache Impala 4.4.0正式发布了! 安装包下载 这次版本发布提供了RPM/DEB安装包

6.4 Impala和HBase进行整合,JDBC
Impala可以通过Hive外部表方式和HBase进行整合 步骤1:创建hbase 表,向表中添加数据 create ' test_info', 'info' put 'test_info','1','info:name','zhangsan' put 'test_info','2','info:name','lisi' • 步骤2:创建hive表 CREATE
6.3 Impala介绍
https://www.cloudera.com/products/open-source/apache-hadoop/impala.html http://www.impala.io/index.html Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。 基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
impala和kudu使用的小细节
之前入门的小错误总结,建表都会出错,真的好尴尬 还是要做好笔记 第一个错误: error:AnalysisException:Table property 'kudu.master_addresses' is required when the impalad startup flat -kudu_master_hosts is not used. answer:'kudu.maste
kudu-impala分区表(hash和range分区)
展开 1、分区表支持hash分区和range分区,根据主键列上的分区模式将table划分为 tablets 。每个 tablet 由至少一台 tablet server提供。理想情况下,一张table分成多个tablets分布在不同的tablet servers ,以最大化并行操作。 2、Kudu目前没有在创建表之后拆分或合并 tablets 的机制。 3、创建表时,必须为表提供分区模式。
获取impala下所有的数据库建表语句
本博文介绍三种方法,推荐使用第三种,前两种都是尝试。 方法一: 现在的导出还是有缺陷的,导出的文件中还是存在其他不必要的信息 #!/bin/bash##获取数据库databases=$(hive -e "show databases; exit;") for database in $databases;do #获取hive建表语句 tabl

Impala的分布式查询
http://blog.csdn.net/u011239443/article/details/51655483 翻译自《Getting Started with Impala》 分布式查询 分布式查询是impala的核心。曾几何时,你需要研究并行计算,才能开始进行深奥而晦涩的操作。现在,有运行在Hadoop上面的Impala,你只需要...一台笔记本电脑。理

IMPALA数据库(其实是HIVE平台,偏向于sql的实现)JDBC链接方式
IMPALA数据库 MAVEN驱动核心代码注意点 MAVEN <dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>2.1.0</version></dependency> 驱动 org.apache.hive.jdbc.HiveDriver 核心
Impala运行中java.net.UnknownHostException: nameservice1的异常
解决Impala运行中java.net.UnknownHostException: nameservice1的异常,nameservice1是配置hdfs中用到的HA,在执行Impala程序时出现 java.net.UnknownHostException: nameservice1异常,找到正确的路径。 分析在CDH5.11.0中配置文件/etc/hadoop/conf/

Impala查询报错:InternalException: Memory limit exceeded: Error occurred on backend
在HUE执行Impala查询的时候报错:InternalException: Memory limit exceeded: Error occurred on backend.... 报错原因是impala连接数过多导致的,可以通过修改连接数,或者等其他连接释放
导出 CDH 中各组件(HDFS、Hive、Impala、Kafka、Kudu、YARN和Zookeeper)指标到 Prometheus
文章目录 前言一、提取准备1. 下载jmx2. 创建规则文件 二、HDFS指标提取1. namenode指标提取2. datanode指标提取 二、Hive指标提取1. Hive Metastore Server 指标提取2. HiveServer2 指标提取 三、Impala 指标提取1. Impala Catalog Server 指标提取2. Impala Daemon 指标提取 四、
Impala系统架构理解
1 impalad(含3个模块,执行hbase或hdfs中的数据,数据的底层存储为hdfs) 当用户通过用户接口提出查询或分析请求时,Impala会选择一个Impalad实例作为协调者(Coordinator)来负责整个查询过程的协调。这个协调者Impalad会与StateStore进行交互,获取集群中其他Impalad实例的健康状态和位置信息,以便选择最靠近数据所在DataNo
Hive/Impala/Hbase/Spark Kerberos
使用hadoop Kerberos有几个地方需要注意,避免真实环境老是有问题: 1. 我以前使用IP地址构建集群(虽然也用了DNS解析),但是有时候你直接通过主机名+DNS解析来做集群,这2者从我实际测试来看是有区别的,使用IP没有任何问题,但是使用DNS解析,开启kerberos总是会有些许问题,因此如果使用DNS解析,建议客户端连接kerberos的主机把集群的IP和主机名写入/etc/ho
Impala JDBC bug
此文仅仅适合开启了简单认证权限的impala,也就是使用sentry+OS用户组来简单控制impala访问控制权限。 impala JDBC有2种访问方式,一种是使用hive2 jdbc访问, 一种使用impala 自己的JDBC访问。 参阅官方文档了解详情: https://www.cloudera.com/documentation/enterprise/latest/topics/imp

impala使用round函数保留小数失效
问题描述如标题所示 1.理论情况: round()函数,是用来做四舍五入的,比如:select round(2.126,2) 结果为:2.13 2.异常情况: 但是有时候会出现一些意料之外的情况,比如:select round(1/3,3) 结果为:0.33300000000000002正确的应该是:0.333 截图效果示例如下: 3.解决办法: 问题原因在于rou

工作中遇到的impala的小问题
我从一个中间表vl_stat_tmp,需要将几个字段保留2位小数,数据类型是double类型的,查询的时候,结果是保留了2位小数。但是插入到最终表volte_nei190130的时候,发现有一个值变成了小数点后不止有2位小数。 下面这张截图是从中间表查询: 然后是插入到最终表后,查询的结果: 这两个字段的数据类型都是double类型。 sql语句如下: insert into v

Impala:新一代开源大数据分析引擎
大数据处理是云计算中非常重要的问题,自Google公司提出MapReduce分布式处理框架以来,以Hadoop为代表的开源软件受到越来越多公司的重视和青睐。以Hadoop为基础,之后的Hbase,Hive,Pig等系统如雨后春笋般的加入了Hadoop的生态系统中。今天我们就来谈谈Hadoop系统中的一个新成员 – Impala。 Impala架构分析 Impala是Cloudera公司主导开
Impala批量插入数据出现空格问题
常用语句记录 impala insert values 批量插入出现空格 出现空格(password的两个值长度不一样 导致666666那个会出现空格) UPSERTinto user ( name, password )VALUES ('admin','666666'),('xiaobu','88888888') 正常 UPSERTUPSERTinto user ( name,
Impala与hive相关知识点摘录
Impala与hive相关知识点摘录Impala架构 Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的 Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直
impala数据导入汇总
1. put/distcp hdfs dfs -put 从本地上传到hdfs 2.load data [cdh2:21000] > select count(*) from tab1; Query: select count(*) from tab1 +----------+ | count(*) | +----------+ | 3279912
impala与hive的比较以及impala的优缺点
Impala相对于Hive所使用的优化技术 没有使用MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少了
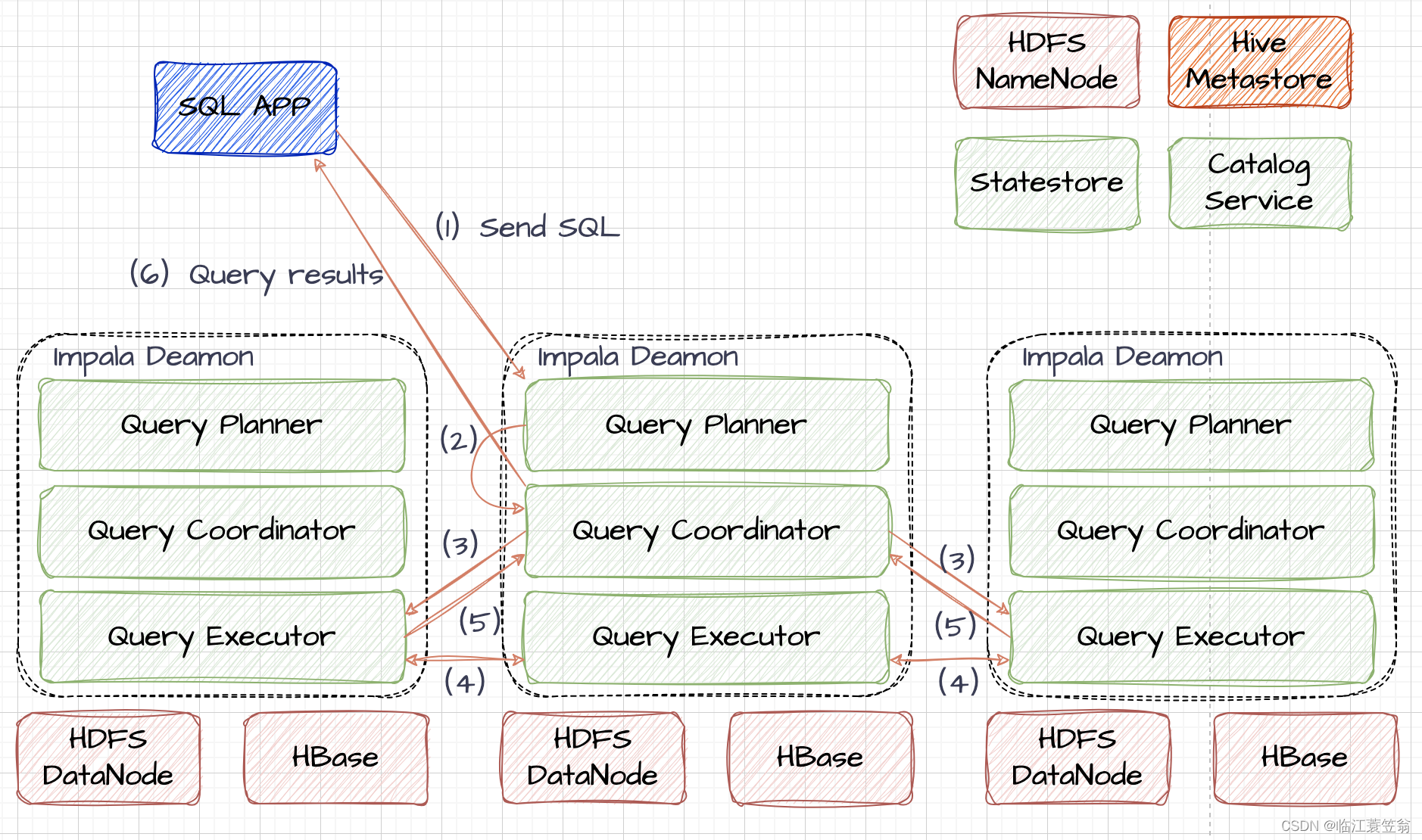
Impala-架构与设计
架构与设计 一、背景和起源二、框架概述1.设计特点2.框架优点3.框架限制 三、架构图1.Impala Daemon2.Statestore3.Catalog 四、Impala查询流程1.发起查询2.生成执行计划3.分配任务4.交换中间数据5.汇集结果6.返回结果 总结参考链接 一、背景和起源 现有的大数据查询分析工具Hive更适合长时间批处理查询分析,并不能满足实时交互式场
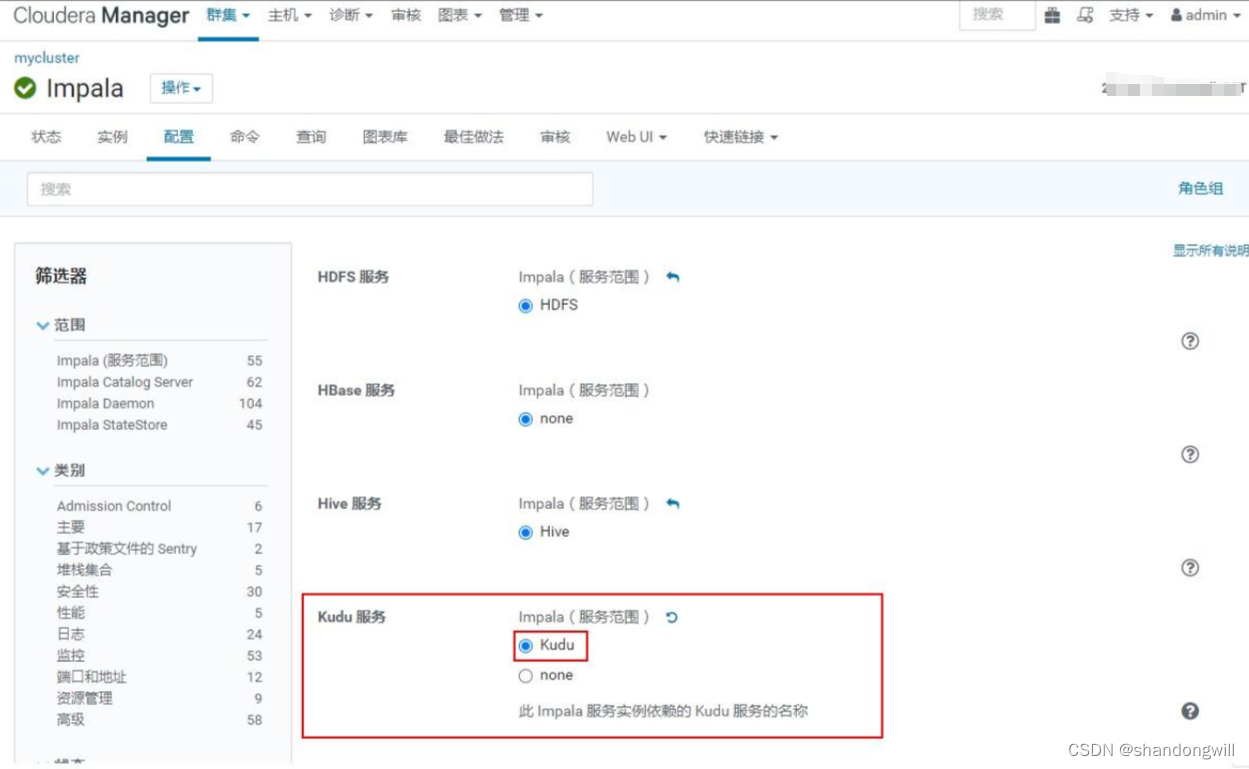
impala与kudu进行集成
文章目录 概要Kudu与Impala整合配置Impala内部表Impala外部表Impala sql操作kuduImpala jdbc操作表如果使用了Hadoop 使用了Kerberos认证,可使用如下方式进行连接。 概要 Impala是一个开源的高效率的SQL查询引擎,用于查询存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。它提供了一个类似于传统关系型数据库的