hashmap专题

Java HashMap的底层实现原理深度解析
《JavaHashMap的底层实现原理深度解析》HashMap基于数组+链表+红黑树结构,通过哈希算法和扩容机制优化性能,负载因子与树化阈值平衡效率,是Java开发必备的高效数据结构,本文给大家介绍... 目录一、概述:HashMap的宏观结构二、核心数据结构解析1. 数组(桶数组)2. 链表节点(Node

Java中HashMap的用法详细介绍
《Java中HashMap的用法详细介绍》JavaHashMap是一种高效的数据结构,用于存储键值对,它是基于哈希表实现的,提供快速的插入、删除和查找操作,:本文主要介绍Java中HashMap... 目录一.HashMap1.基本概念2.底层数据结构:3.HashCode和equals方法为什么重写Has

Java遍历HashMap的6种常见方式
《Java遍历HashMap的6种常见方式》这篇文章主要给大家介绍了关于Java遍历HashMap的6种常见方式,方法包括使用keySet()、entrySet()、forEach()、迭代器以及分别... 目录1,使用 keySet() 遍历键,再通过键获取值2,使用 entrySet() 遍历键值对3,

Golang HashMap实现原理解析
《GolangHashMap实现原理解析》HashMap是一种基于哈希表实现的键值对存储结构,它通过哈希函数将键映射到数组的索引位置,支持高效的插入、查找和删除操作,:本文主要介绍GolangH... 目录HashMap是一种基于哈希表实现的键值对存储结构,它通过哈希函数将键映射到数组的索引位置,支持

JAVA保证HashMap线程安全的几种方式
《JAVA保证HashMap线程安全的几种方式》HashMap是线程不安全的,这意味着如果多个线程并发地访问和修改同一个HashMap实例,可能会导致数据不一致和其他线程安全问题,本文主要介绍了JAV... 目录1. 使用 Collections.synchronizedMap2. 使用 Concurren
HashMap中常用的函数
假设如下HashMap<String, Integer> map = new HashMap<>();获取value值1、返回key为a的valueget(a)2、返回key为a的value,若没有该key返回0getOrDefault(a,0)新增键值对1、新增键值对(a,1)put(a,1)2、如果key为a的键不存在,则存入键值对(a,1)putIfAbsent(a,1)3

hashmap的存值,各种遍历方法
package com.jefflee;import java.util.HashMap;import java.util.Iterator;import java.util.Map;public class HashmapTest {// 遍历Hashmap的四种方法public static void main(String[] args) {//hashmap可以存一个null,把
容器第五课,Map和HashMap的基本用法,hashMap和HashTable的区别
Map接口 实现Map接口的类用来存储键(Key) --- 值(value)对。 Map接口的实现类有HashMap和TreeMap类 Map类中存储的键---值对通过键来标识,所以键值不能重复 package com.pkushutong.Collection;import java.util.HashMap;import java.util.Map;/*** 测试Map的基本用法
面试:HashMap
文章引用: http://www.importnew.com/7099.html https://blog.csdn.net/niuwei22007/article/details/52005329 HashMap的工作原理是近年来常见的Java面试题。几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么
HashMap 源码分析(删除+总结)JDK1.8
文章来源: 1 https://segmentfault.com/a/1190000012926722#articleHeader7 2 https://www.zhihu.com/question/20733617 3 https://tech.meituan.com/java-hashmap.html 4 https://www.zhihu.com/question/5752

【HashMap】深入原理解析
【HashMap】深入原理解析 分类: 数据结构 自考 equals与“==”(可以参考自己的另一篇博文) 1,基本数据类型(byte,short,char,int,long,float,double,boolean) 使用“==” 对比的是具体的值是否相等 2,复合数据类型 “== ”对比的是内存中存放的地址 object中的equals初始行为是比较内存中的地址,但在
HashMap初始化指定容量后,遇到不够用时,还会扩容吗?
先说答案:会 public class temp{public static void main(String agrs[]){HashMap hashMap = new HashMap(20);System.out.println(hashMap.size);//输出0, 要记得 容量是容量,尺寸是尺寸for(int i=0;i,30; i++){hashMap.put(i,i);System
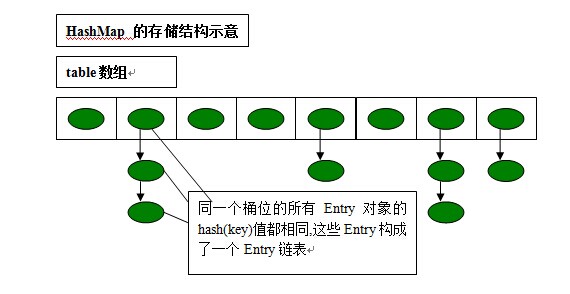
Java集合框架(Set与Map,HashSet与HashMap,TreeSet与TreeMap)
这是一个介绍集合类,数组以及容器关系的截图,便于我们对集合的理解。 一.Set和Map Set代表一种集合元素无序、不可重复的集合,Map则代表一种由多个key-value(键-值)对组成的集合。 从表面上看,它们之间的相似性很少,但实际上Map和Set之间有莫大的联系。可以说,Map集合是Set集合的扩展。 如果只考察Map集合的Key,不难发现,这些Map集合的key具有一个特
63-java hashmap的原理
Java HashMap的底层是哈希表,它是一个数组,每个数组元素是一个链表。当调用put(key, value)方法时,HashMap会计算key的哈希值,然后将其映射到数组的一个位置。如果有多个键映射到同一个位置,它们会存储在一个链表中。当需要获取一个值时,HashMap会再次计算键的哈希值,找到对应的数组位置,然后遍历链表以找到正确的键,并返回相应的值。 HashMap的扩容机制也很重要,
Implement HashMap in Java
Implement Hashmap in Java. 原理: Hashmap就是array of linkedlist,就是利用hash算法,算index之后,然后冲突了,就看后面有没有 Key Value pair 相等,如果相同,则覆盖,如果没有,则加在bucket的beginning。 源代码: http://developer.classpath.org/doc/java/util/H

吃透Java集合系列九:HashMap
一:HashMap的整体实现 HashMap是由Hash表来实现的,数组+链表(1.8加入红黑树)的方式实现的,通过key的hash值与数组长度取余来获取应插入数组的下标,如果产生Hash冲突,在原下标位置转为链表,当链表长度到达8并且数组长度大于等于64则转为红黑树。 通过以上描述我们提以下问题: 1、什么是Hash表 我们知道数组的特点是:寻址容易,插入和删除困难。 链表的特点是:寻址困难
HashMap putIfAbsent computeIfAbsent 使用方法
方法功能描述: putIfAbsent (a,b) 如果当前map 里面没有key 为a 的数据, 那么把key 为 a,值为b放到map 里面,方法放回null, 如果之前有key 为a 的数据,那么返回a 对应的value,无视参数b computeIfAbsent(a, Function f) 如果map 里面没有key 为a 的数据, 那么使用f 计算一个key对应的value

HashMap 链表转红黑树的阈值为何为 8
与一个重要的统计学原理——泊松分布密切相关:该原理阐明了在单位时间(或面积、体积)内,随机事件的平均发生次数遵循泊松分布 为什么这因子设定为0.5呢? 在忽略方差的情况下,哈希表容量占比的期望值约为 0.5625,也就是说,平均每个桶内有 0.5 个元素,这便是源码中 λ = 0.5 值的由来。

HashTable amp;amp; HashMap
HashTable && HashMap HashTable:散列表,它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的做法。顾名思义,该数据结构可以理解为一个线性表,但是其中的元素不是紧密排列的,而是可能存在空隙。时间复杂度为O(1)。 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进

第一章 集合框架和泛型(ArrayList/LinkedList/HashSet/HashMap/泛型集合/Collections算法类)
第一章 集合框架和泛型 一、Collection 1、Collection 接口存储一组不唯一,无序的对象 二、List List 接口存储一组不唯一,有序(插入顺序)的对象 1.ArrayList 实现了长度可变的数组,在内存中分配连续的空间优点:遍历元素和随机访问元素的效率比较高ArrayList类是List接口的一个具体实现类ArrayList对象实现了可变大小

java中,HashMap为什么每次扩容的倍数是2,而不是1.5或者2.5?
本文为转载文章,部分位置加入了个人对原文的理解 原文:https://www.zhihu.com/question/422840340/answer/1494603694 来源:知乎 一、前言二、HashCode为什么使用31作为乘数 1. 固定乘积31在这用到了2. 来自stackoverflow的回答3. Hash值碰撞概率统计4. Hash值散列分布 三、HashMap 数据

手搓 Java hashmap
1. 前言 都知道 hashmap 是哈希表,字典,这里全萌新向,至于为什么萌新向,因为我也不会,算是拷打自己对于一些流程的实现。 我们先把最基础的功能实现了,后面再考虑扰动,红黑冲突树,并发安全,以及渐进式 hash这些高阶功能。 2. 实现过程 2.1. 底层存储结构 这里毫无疑问,就选择数组就行,初始容量我们随便写一个,就写 10 算了。 class BestHashMap{p

HashMap原理。图文并茂式解读。这些注意点你一定还不了解
[TOC] 概述 本篇文章我们来聊聊大家日常开发中常用的一个集合类 - HashMap。HashMap 最早出现在 JDK 1.2中,底层基于散列算法实现。HashMap 允许 null 键和 null 值,在计算哈键的哈希值时,null 键哈希值为 0。HashMap 并不保证键值对的顺序,这意味着在进行某些操作后,键值对的顺序可能会发生变化。另外,需要注意的是,HashMap 是非线程安全
JDK1.8 HashMap源码分析 ----转载别人的,以后好复习。
本人看不懂源码,逻辑思维差,又懒。连看文档都喜欢跳字阅读。所以只能去看别人写的源码分析。也不知道能不能转载。。所以直接贴个地址。 这是几天下来,翻了好多篇博客,发现写的非常详细,而且步骤和注释写的非常清晰的一篇了。。 大神好厉害。拜读两遍,以表敬意。 读技术文档一定要逐字阅读。认真看,认真计算。毕竟这个貌似面试会问啊,找工作那么难。 JDK1.8 HashMap源码分析 >>>
9. HashMap和Hashtable有什么区别?为什么HashMap是线程不安全的?
HashMap 和 Hashtable 都是 Java 中用于存储键值对的数据结构,但它们在设计和使用上有一些显著的区别。以下是它们的主要区别: 1. 线程安全性 HashMap: 不是线程安全的。多个线程同时访问和修改HashMap对象时,如果不进行同步,可能会导致数据不一致和其他问题。 Hashtable: 线程安全的。Hashtable内部方法大部分都使用了synchronized关