hadoop3.2专题
Hadoop3.2 集群搭建 (免密登录)
首页下载APP Hadoop3.2 集群搭建 Hadoop3.2 集群新版本的搭建详细讲解过程,从下面第一张官方的图来看,最新版是3.2,所以大猪将使用3.2的版本来演示,过程中遇到的坑留给自己,把路留给你们,IT之路还有大猪。 大猪 为了把文章压缩极简方便小伙伴阅读,将使用root帐号进行所有操作。 准备两台主机10.211.55.11、10.211.55.12 对应的

分布式部署(JDK1.8+Hadoop3.2+Spark2.4+Ubuntu16.04)
本次分布式Spark环境部署采用JDK1.8、Hadoop3.2、Spark2.4的套装,一个Master,两个Slaves 1. 修改hosts文件,设置Master、Slaves1、Slaves2节点的IP地址。 2. SSH免登录设置 #ssh-keygen -t rsa 一直回车,后将文件分别拷贝到Master,Slaves1,Slaves2中 #ssh-copy
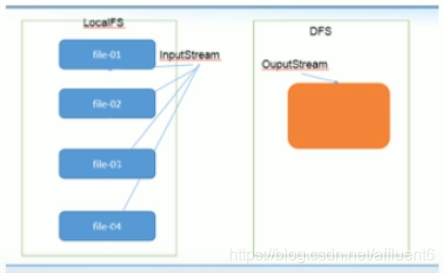
3.HDFS的客户端操作—环境准备(Windows10上安装与配置 Hadoop3.2 环境)、API操作、I/O流操作
本文目录如下: 3.HDFS的客户端操作—环境准备、API操作、I/O流操作3.1 HDFS客户端环境准备3.1.1 在Win10上安装Hadoop并配置环境变量3.1.2 创建一个Maven工程Hdfs-0100-HelloWorld3.1.3 导入相应的依赖、配置日志文件3.1.4 创建包名:com.xqzhao.hdfs3.1.5 创建HdfsClient类3.1.6 执行程序3.1.
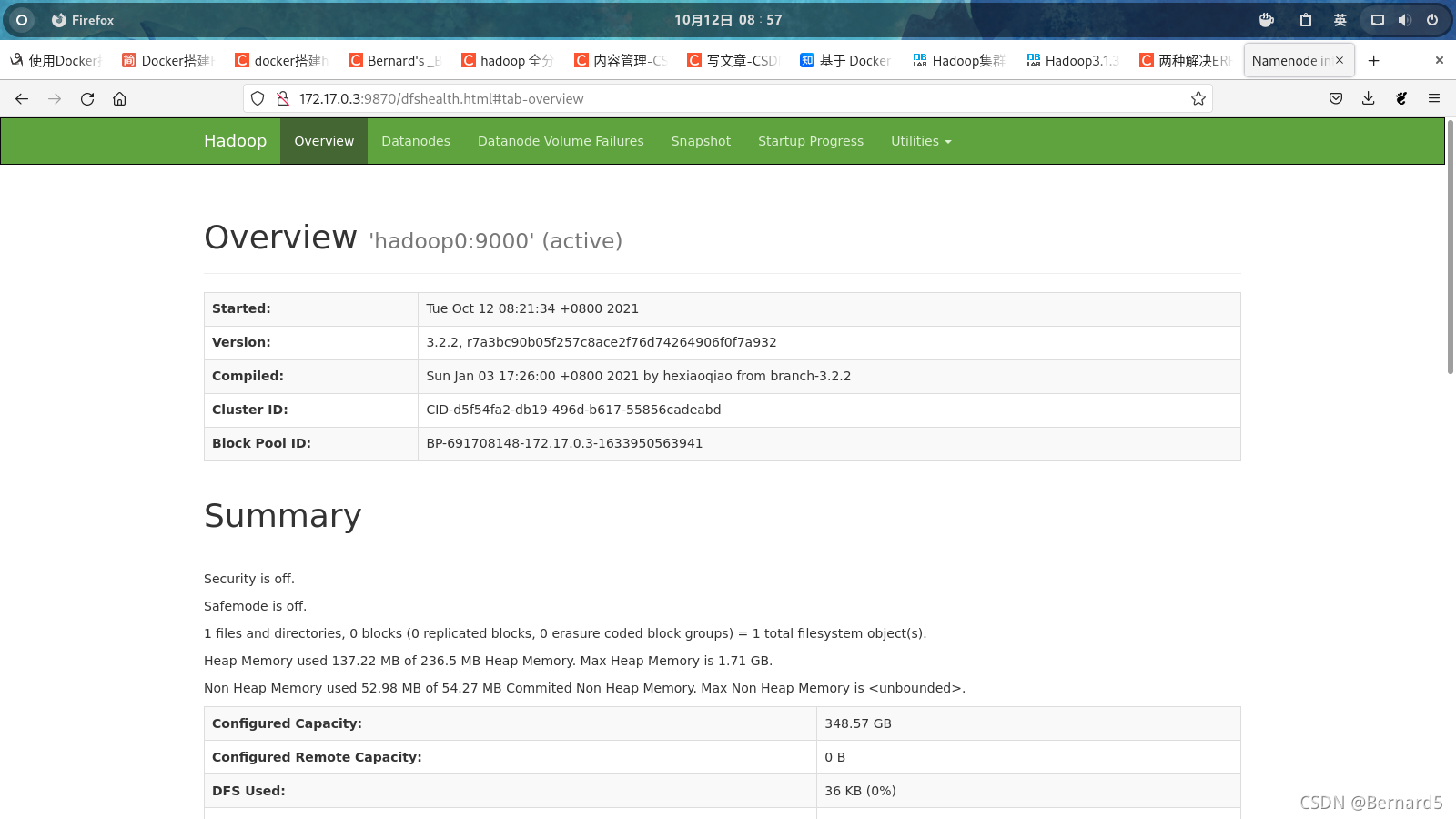
docker配置hadoop3.2.2全分布式集群
docker 配置 在此之前需要完成docker的安装 mkdir centos-ssh && cd centos-ssh && vi Dockerfilesudo docker pull hub.c.163.com/public/centos FROM centos # 基础镜像,在使用之前需要pullMAINTAINER bernard# 安装openssh-server和sudo软
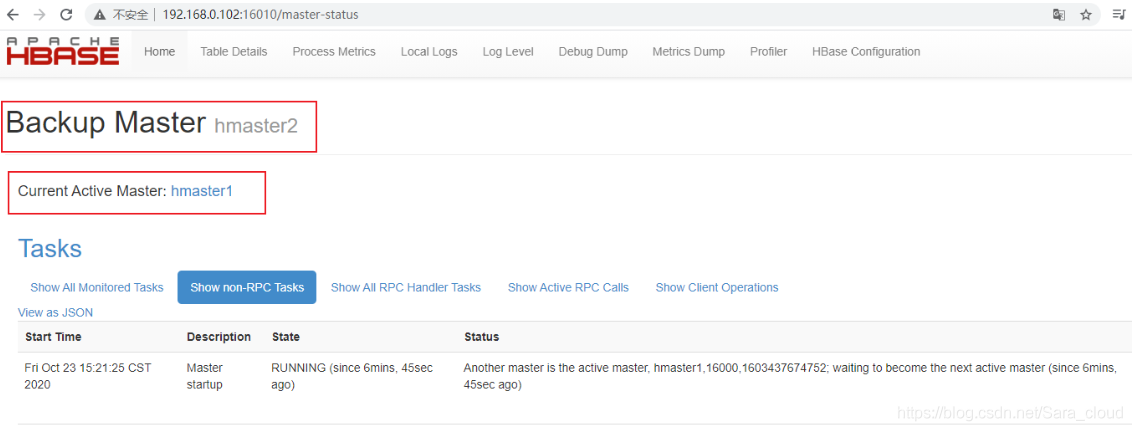
zookeeper3.5.8 + hadoop3.2.1+Hbase2.2.5完全分布式+高可用(HA)集群
目录 摘要: 1 关于集群 1.1 Hadoop是什么 1.2 Hadoop能做什么 1.3 怎么使用Hadoop 1.4 分布式大数据介绍 1.5 Zookeeper原理说明 2 项目准备 2.1 Linux Centos 环境准备 2.2 配置集群间免密登录(ssh服务) 2.3 修改主机的hostname,便于区分和后续的配置 2.4 集群安装java环境

基于CentOS7的Hadoop3.2.2完全分布式集群部署记录
服务器部署结构 hostnamehadoop1hadoop2hadoop3IP192.168.10.25192.168.10.27192.168.10.28HDFSNameNodeSecondaryNameNodeHDFSDataNodeDataNodeDataNodeYARNResourceManagerYARNNodeManagerNodeManagerNodeManager 一.环境准备

mac 版hadoop3.2.4 解决 Unable to load native-hadoop library 缺失文件
mac 版hadoop3.2.4或其他版本 Unable to load native-hadoop library 缺失文件 Native 包报错缺失: 1. hadoop-3.2.4/lib/native里加*.dylib 2. hadoop-3.2.4/etc/hadoop/hadoop-env.sh 加或修改 export HADOOP_OPTS="-Djava.library.p