本文主要是介绍docker配置hadoop3.2.2全分布式集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
docker 配置
在此之前需要完成docker的安装
mkdir centos-ssh && cd centos-ssh && vi Dockerfile
sudo docker pull hub.c.163.com/public/centos
FROM centos # 基础镜像,在使用之前需要pullMAINTAINER bernard# 安装openssh-server和sudo软件包,并且将sshd的UsePAM参数设置成no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装openssh-clients
RUN yum install -y openssh-clients# 添加测试用户root,密码root,并且将此用户添加到sudoers里
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 启动sshd服务并且暴露22端口
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
docker build -t 'bernard/centos-ssh' . # 构建
mkdir centos-ssh-root-jdk && cd centos-ssh-root-jdk
# 拷贝一个jdk到这个文件夹下
vi Dockerfile#基于上一个ssh镜像构建
FROM bernard/centos-ssh
#拷贝并解压jdk
ADD jdk-8u301-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_231 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH# wq
docker build -t 'bernard/centos-jdk' .
mkdir centos-ssh-root-jdk-hadoop && cd centos-ssh-root-jdk-hadoop
# 拷贝一个hadoop-3.2.2到这个文件夹下
vi DockerfileFROM bernard/centos-jdk
ADD hadoop-3.2.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.2.2 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH# wq
docker build -t 'bernard/hadoop' .
分别开三个窗口。
docker run --name hadoop0 --hostname hadoop0 -d -P -p bernard/hadoop
docker run --name hadoop1 --hostname hadoop1 -d -P bernard/hadoop
docker run --name hadoop2 --hostname hadoop2 -d -P bernard/hadoop
配置免密登陆
- 配置hadoop0到1/2上的免密登陆
- 在hadoop0 hadoop1 hadoop2的host上增加三者的IP地址
# src
ssh localhost
ssh-keygen -t rsa
scp ~/.ssh/id_rsa.pub root@hadoop1:~
# dst
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
172.17.0.3 hadoop0
172.17.0.4 hadoop1
172.17.0.5 hadoop2
# IP地址要根据你的改
配置hadoop
bashrc
vi ~/.bashrcexport JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootsource ~/.bashrc
hadoop-env.sh
本文件和以下文件均在HADOOP_HOME/etc/hadoop下
cd /usr/local/hadoop/etc/hadoop
vi hadoop-env.shexport JAVA_HOME=/usr/local/jdk1.8
core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop0:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property>
<!--<property><name>fs.trash.interval</name><value>1440</value></property>
-->
</configuration>
hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>hadoop0:50090</value></property><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
</configuration>
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop0:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop0:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value></property>
</configuration>
yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>hadoop0</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
workers
hadoop0
hadoop1
hadoop2
scp * root@hadoop1:/usr/local/hadoop/etc/hadoop
scp * root@hadoop2:/usr/local/hadoop/etc/hadoop
启动
start-dfs.sh
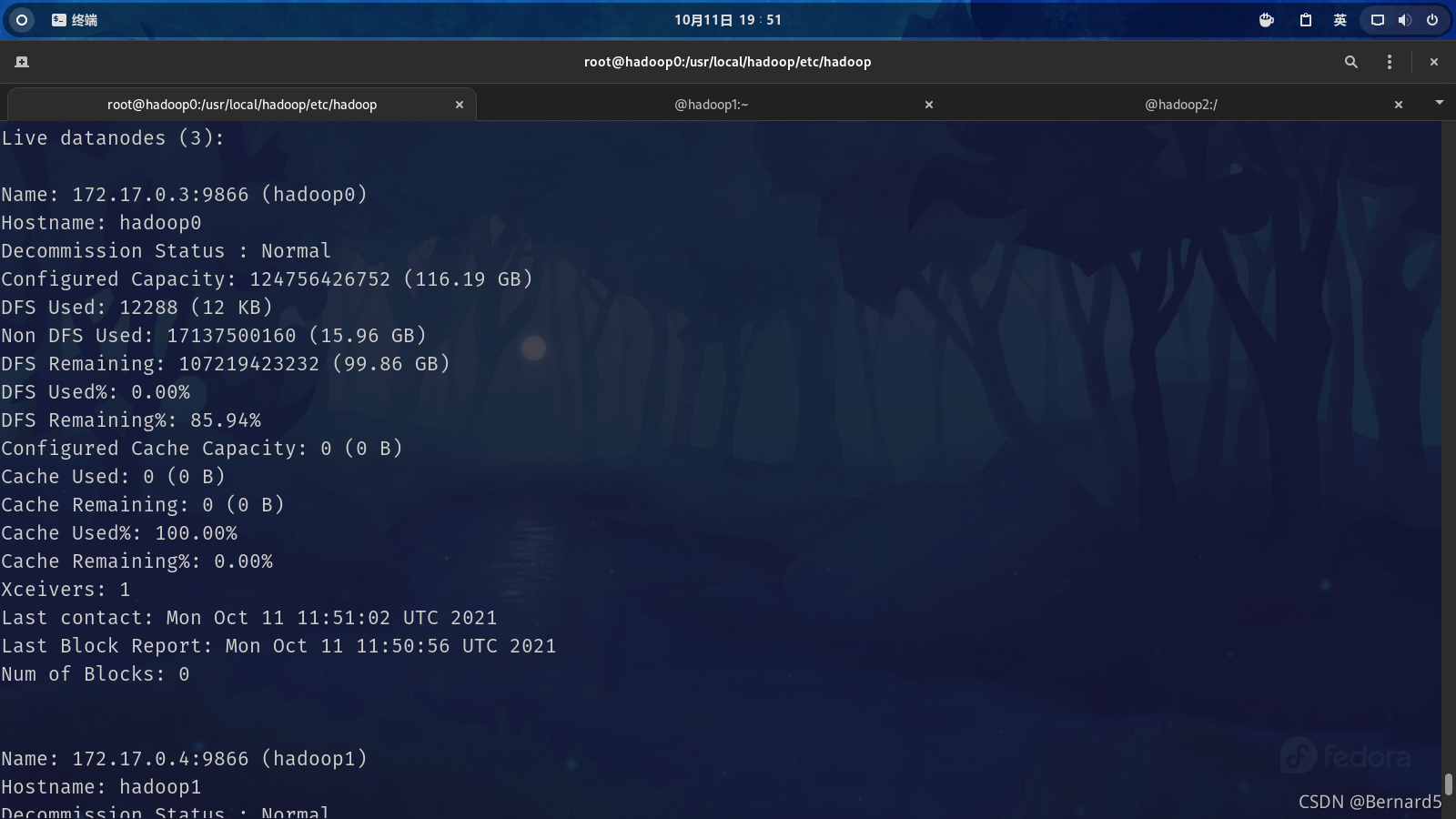
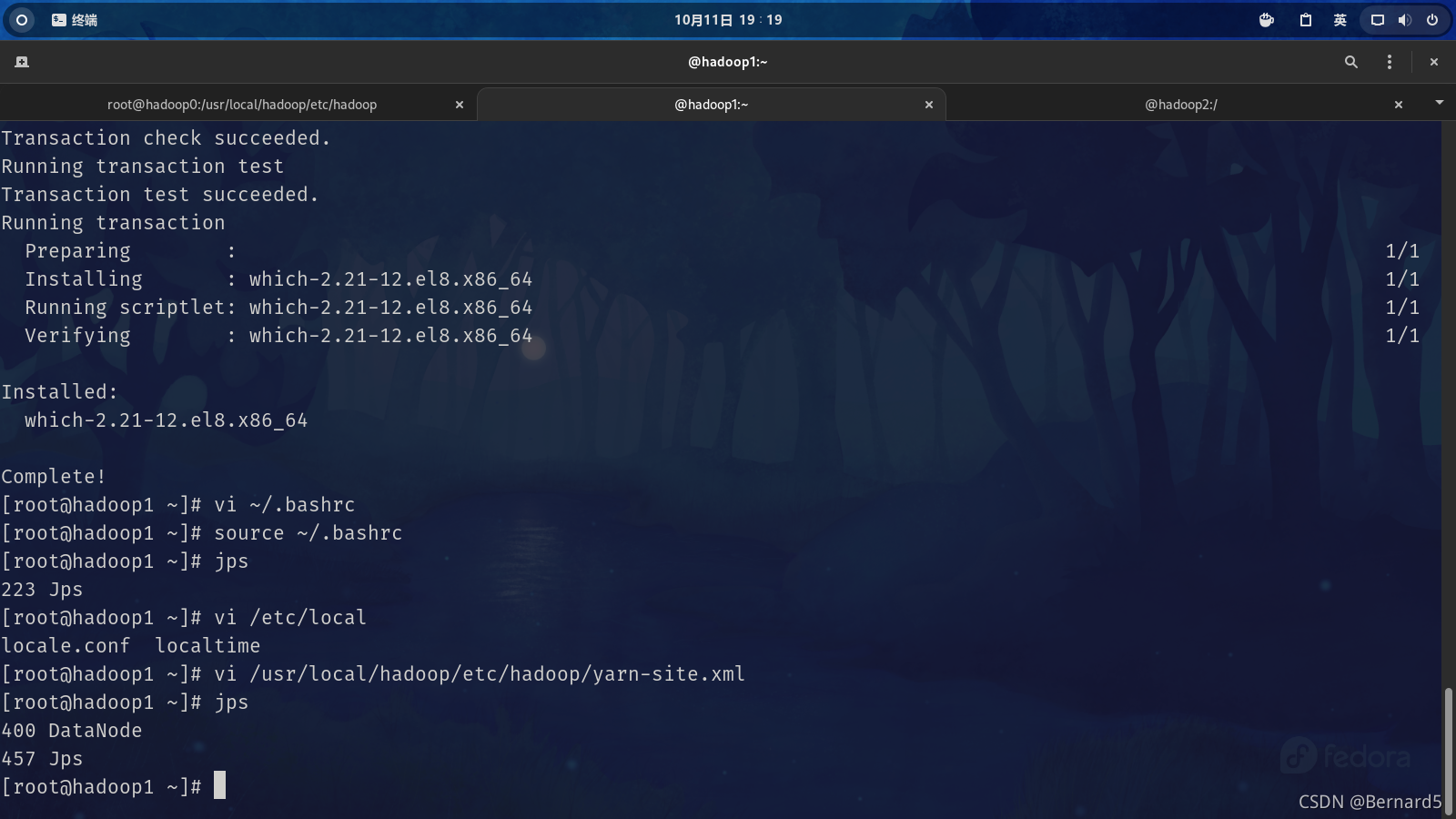
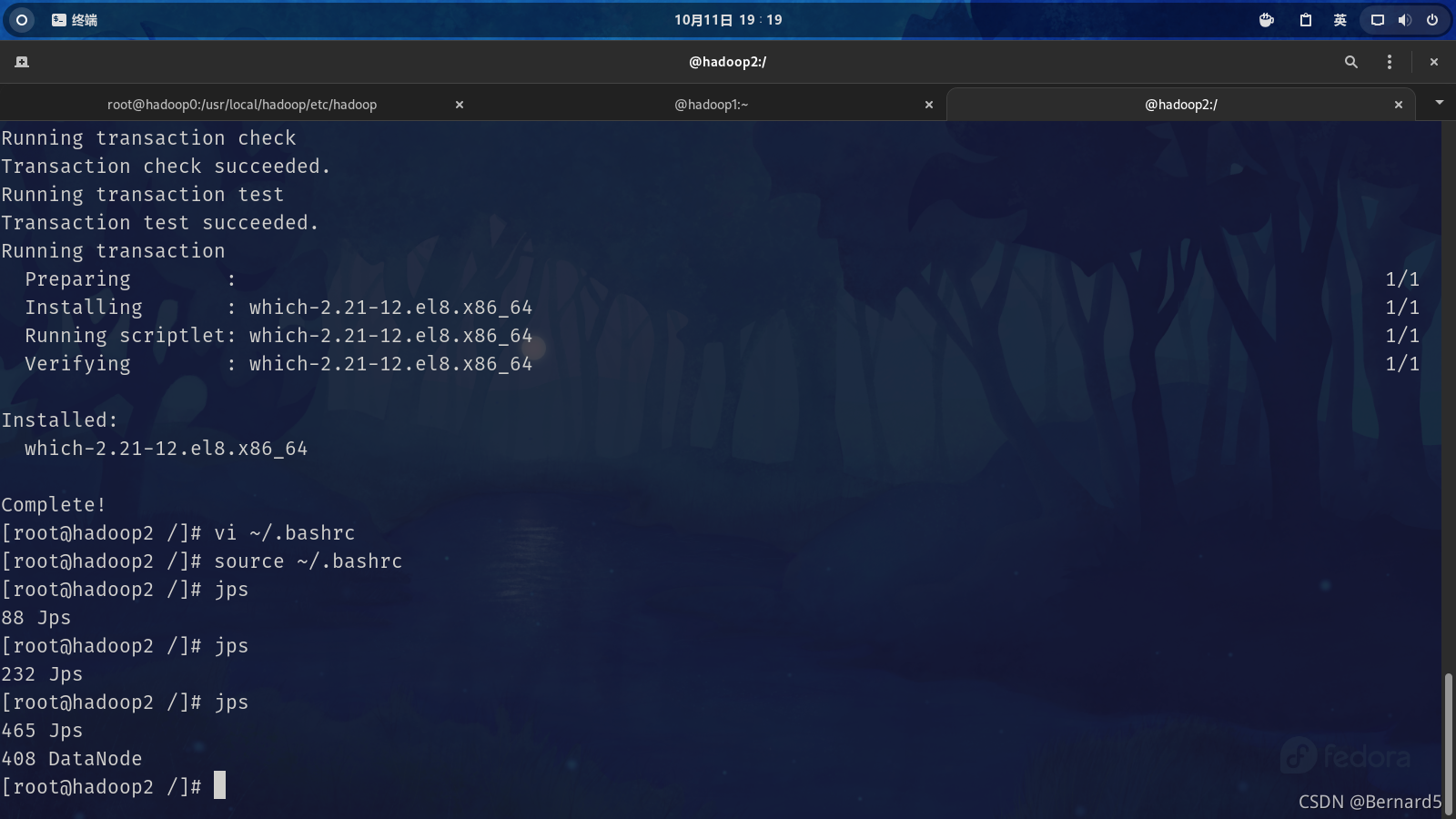
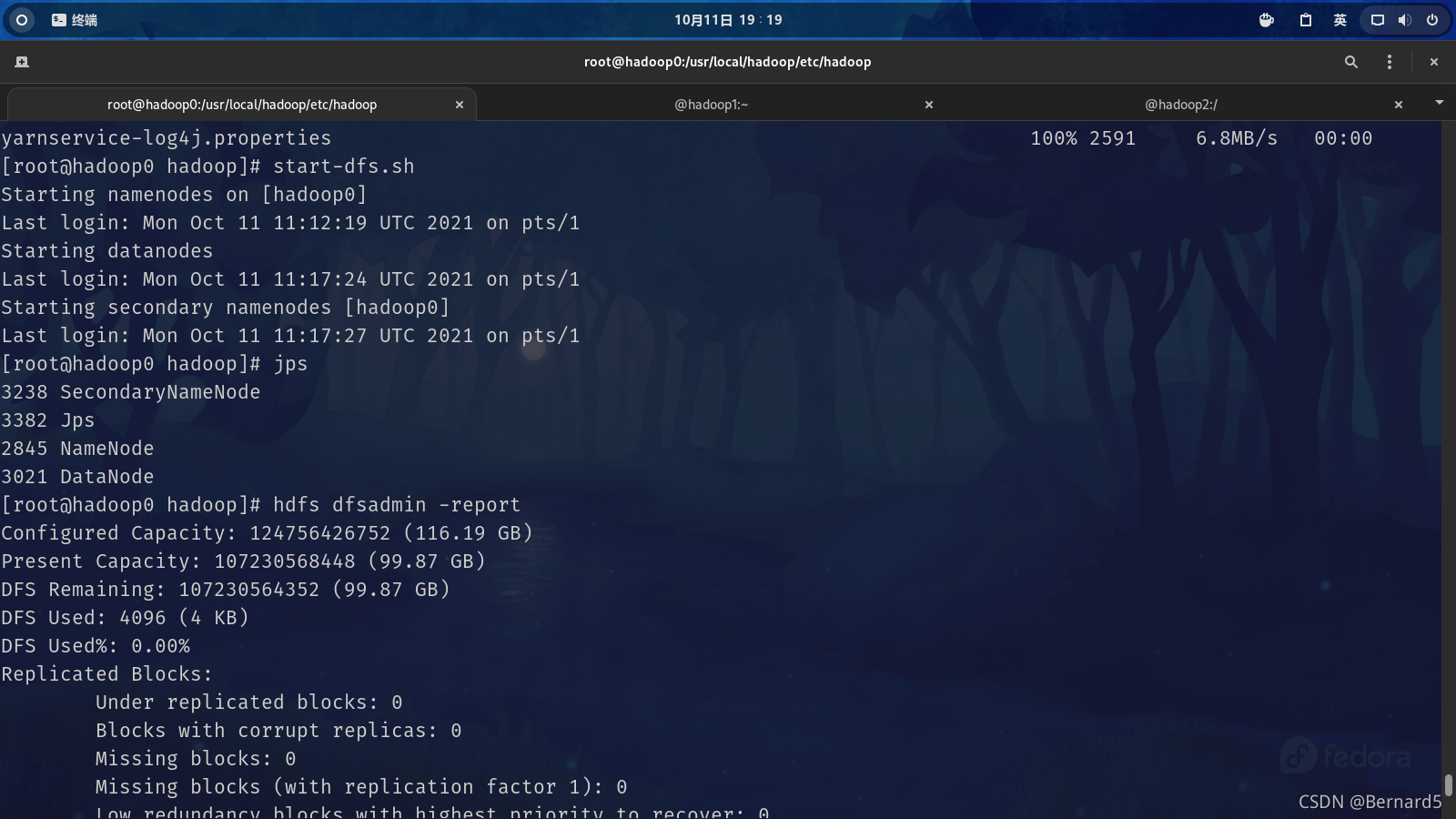
reference
https://zhuanlan.zhihu.com/p/59758201
https://www.cnblogs.com/rmxd/p/12051866.html#_label1
git clone https://github.com/jpetazzo/pipework.git
sudo cp -rp pipework-master/pipework /usr/local/bin/sudo brctl addbr br0
sudo ip link set dev br0 up
sudo ip addr add 192.168.2.1/24 dev br0这篇关于docker配置hadoop3.2.2全分布式集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







