本文主要是介绍3.HDFS的客户端操作—环境准备(Windows10上安装与配置 Hadoop3.2 环境)、API操作、I/O流操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文目录如下:
- 3.HDFS的客户端操作—环境准备、API操作、I/O流操作
- 3.1 HDFS客户端环境准备
- 3.1.1 在Win10上安装Hadoop并配置环境变量
- 3.1.2 创建一个Maven工程Hdfs-0100-HelloWorld
- 3.1.3 导入相应的依赖、配置日志文件
- 3.1.4 创建包名:com.xqzhao.hdfs
- 3.1.5 创建HdfsClient类
- 3.1.6 执行程序
- 3.1.7 涉及的主要类
- 3.2 HDFS的API操作
- 3.2.1 HDFS文件上传(测试参数优先级)
- 3.2.2 HDFS文件下载
- 3.2.3 HDFS文件夹删除
- 3.2.4 HDFS文件名更改
- 3.2.5 HDFS文件详情查看
- 3.2.6 HDFS文件和文件夹判断
- 3.3 HDFS的I/O流操作(扩展 / 了解即可)
- 3.3.1 HDFS文件上传
- 3.3.2 HDFS文件下载
- 3.3.3 定位文件读取
- 6.4.7 HDFS的访问权限控制
- 6.4.8 小文件的合并
3.HDFS的客户端操作—环境准备、API操作、I/O流操作
3.1 HDFS客户端环境准备
3.1.1 在Win10上安装Hadoop并配置环境变量
略,请同学们自行百度查看,此处不在阐述。
可以参考此博客
- 一个问题:安装并配置完成
Hadoop后,我们可以在CMD窗口输入winutils进行测试,若成功输出,则安装配置成功。若弹出某命令无法找到,则可能是系统缺少基本微软运行库。 - 看一下自己的
bin文件里是否有hadoop.dll,以及winutils.exe,没有就去下载对应Hadoop版本的bin文件后添加:下载地址:微软基本运行库下载地址。 - 注:
Hadoop与JDK的安装环境中不要包含空格,避免出现不必要的错误。
3.1.2 创建一个Maven工程Hdfs-0100-HelloWorld
3.1.3 导入相应的依赖、配置日志文件
- (1) 导入依赖
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.7.2</version></dependency><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency>
</dependencies>
- (2) 配置日志文件
需要在项目的src/main/resources目录下,新建一个文件,命名为log4j.properties,在文件中填入如下信息:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3.1.4 创建包名:com.xqzhao.hdfs
3.1.5 创建HdfsClient类
public class HdfsClient{ @Testpublic void put() throws IOException,InterruptedException {//获取一个HDFs的抽象封装对象Configuration configuration = new Configuration();FileSystem fileSystem = FileSystem.get(URI.create("hdfs://hadoop100:9000"), configuration, user:"xqzhao");//用这个对象操作文件系统fileSystem.copyToLocalFile(new Path("/test"), new Path("d:\\"));//关闭文件系统filesystem.close( );}
}
注·:可以将上面的第一步和第三步分别封装为before()和after()两个函数,并使用@Before和@After两个注解分别进行标注。效果如下:
public class HDFSClient {private Filesystem fs;@Beforepublic void before() throws IOException,InterruptedException {fs = FileSystem.get(URI.create("hdfs://hadoop102:9000"), new Configuration(), user:"xqzhao");System.out.println("Before!!!!!!");}@Testpublic void delete() throws IOException {boolean delete = fs.delete( new Path("/1.txt"),recursive: true);}@Afterpublic void after() throws IOException {system.out.print1n( "After!!!!!!!!!!");fs.close();}
}3.1.6 执行程序
- 运行时需要配置用户名称。
客户端去操作HDFS时,是需要一个用户身份的。默认情况下,HDFS客户端API会从JVM中获取一个参数来作为自己的用户身份:
-DHADOOP_USER_NAME=xqzhao,xqzhao为用户名称。
3.1.7 涉及的主要类
在Java中操作HDFS,主要涉及以下Class:
Configuration
该类的对象封转了客户端或者服务器的配置FileSystem
该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过FileSystem的静态方法get获得该对象
FileSystem fs = FileSystem. get(conf)
get方法从conf中的一个参数fs.defaultFS的配置值判断具体是什么类型的文件系统- 如果我们的代码中没有指定
fs.defaultFs,并且工程ClassPath下也没有给定相应的配置,conf中的默认值就来自于Hadoop的Jar包中的core-default.xml- 默认值为
file:///,则获取的不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象
3.2 HDFS的API操作
3.2.1 HDFS文件上传(测试参数优先级)
- (1) 编写源代码
@Test
public void CopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {...// 2 上传文件fileSystem.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));// 3 关闭文件系统fileSystem.close();
}
- (2) 将hdfs-site.xml拷贝到项目的根目录下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
- (3) 参数优先级
参数优先级排序: (1) 客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的默认配置
3.2.2 HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 执行下载操作// boolean delSrc 指是否将原文件删除// Path src 指要下载的文件路径// Path dst 指将文件下载到的路径// boolean useRawLocalFileSystem 是否开启文件校验fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);// 3 关闭资源fs.close();
}
3.2.3 HDFS文件夹删除
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 执行删除fs.delete(new Path("/0508/"), true);// 3 关闭资源fs.close();
}
3.2.4 HDFS文件名更改
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu"); // 2 修改文件名称fs.rename(new Path("/banzhang.txt"), new Path("/banhua.txt"));// 3 关闭资源fs.close();
}
3.2.5 HDFS文件详情查看
查看文件名称、权限、长度、块信息
`@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{// 1获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu"); // 2 获取文件详情RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);while(listFiles.hasNext()){LocatedFileStatus status = listFiles.next();// 输出详情// 文件名称System.out.println(status.getPath().getName());// 长度System.out.println(status.getLen());// 权限System.out.println(status.getPermission());// 分组System.out.println(status.getGroup());// 获取存储的块信息BlockLocation[] blockLocations = status.getBlockLocations();for (BlockLocation blockLocation : blockLocations) {// 获取块存储的主机节点String[] hosts = blockLocation.getHosts();for (String host : hosts) {System.out.println(host);}}System.out.println("-----------班长的分割线----------");}// 3 关闭资源
fs.close();
}
3.2.6 HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件配置信息Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 判断是文件还是文件夹FileStatus[] listStatus = fs.listStatus(new Path("/"));for (FileStatus fileStatus : listStatus) {// 如果是文件if (fileStatus.isFile()) {System.out.println("f:"+fileStatus.getPath().getName());}else {System.out.println("d:"+fileStatus.getPath().getName());}}// 3 关闭资源fs.close();
}
3.3 HDFS的I/O流操作(扩展 / 了解即可)
- 上面我们学的API操作HDFS系统都是框架封装好的。那么如果我们想自己实现上述API的操作该怎么实现呢?
- 我们可以采用IO流的方式实现数据的上传和下载。
3.3.1 HDFS文件上传
需求:把本地e盘上的banhua.txt文件上传到HDFS根目录
编写代码
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException {// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 创建输入流FileInputStream fis = new FileInputStream(new File("e:/banhua.txt"));// 3 获取输出流FSDataOutputStream fos = fs.create(new Path("/banhua.txt"));// 4 流对拷IOUtils.copyBytes(fis, fos, configuration);// 5 关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fs.close();
}
3.3.2 HDFS文件下载
需求:从HDFS上下载banhua.txt文件到本地e盘上
编写代码
// 文件下载
@Test
public void getFileFromHDFS() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 获取输入流FSDataInputStream fis = fs.open(new Path("/banhua.txt"));// 3 获取输出流FileOutputStream fos = new FileOutputStream(new File("e:/banhua.txt"));// 4 流的对拷IOUtils.copyBytes(fis, fos, configuration);// 5 关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fs.close();
}
3.3.3 定位文件读取
需求:分块读取HDFS上的大文件,比如根目录下的/hadoop-2.7.2.tar.gz
编写代码
- (1) 下载第一块
@Test
public void readFileSeek1() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 获取输入流FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));// 3 创建输出流FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.2.tar.gz.part1"));// 4 流的拷贝byte[] buf = new byte[1024];for(int i =0 ; i < 1024 * 128; i++){fis.read(buf);fos.write(buf);}// 5关闭资源IOUtils.closeStream(fis);IOUtils.closeStream(fos);
fs.close();
}
- (2) 下载第二块
@Test
public void readFileSeek2() throws IOException, InterruptedException, URISyntaxException{// 1 获取文件系统Configuration configuration = new Configuration();FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "atguigu");// 2 打开输入流FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));// 3 定位输入数据位置fis.seek(1024*1024*128);// 4 创建输出流FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.2.tar.gz.part2"));// 5 流的对拷IOUtils.copyBytes(fis, fos, configuration);// 6 关闭资源IOUtils.closeStream(fis);IOUtils.closeStream(fos);
}
- (3) 合并文件
在Window命令窗口中进入到目录E:\,然后执行如下命令,对数据进行合并
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
合并完成后,将hadoop-2.7.2.tar.gz.part1重新命名为hadoop-2.7.2.tar.gz。解压发现该tar包非常完整。
6.4.7 HDFS的访问权限控制
- 1.停止hdfs集群,在node01机器上执行以下命令
cd /export/servers/hadoop-2.7.5
sbin/stop-dfs.sh
- 2.修改node01机器上的hdfs-site.xml当中的配置文件
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<property><name>dfs.permissions.enabled</name><value>true</value>
</property>
6.4.8 小文件的合并
- 由于Hadoop擅长存储大文件,因为大文件的元数据信息比较少,如果
Hadoop集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力,所以在实际工作当中,如果有必要一定要将小文件合并成大文件进行一起处理 - 在我们的
HDFS的Shell命令模式下,可以通过命令行将很多的hdfs文件合并成一个大文件下载到本地
cd /export/servers
hdfs dfs -getmerge /config/*.xml ./hello.xml
- 既然可以在下载的时候将这些小文件合并成一个大文件一起下载,那么肯定就可以在上传的时候将小文件合并到一个大文件里面去
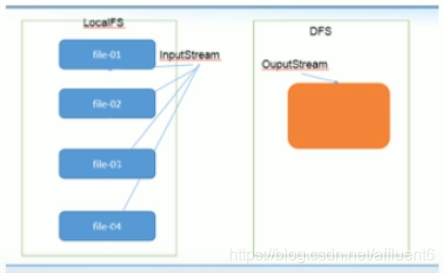
@Test
public void mergeFile( ) throws Exception{//获取分布式文件系统FileSystem fileSystem = FileSystem.get(new URI("hdf://192.168.52.250:8020"), new Configuration(), "root");FSDataOutputStream outputStream = fileSystem.create(newPath("/bigfile.txt"));//获取本地文件系统LocalFileSystem local = FileSystem.getLocal(new Configuration());//通过本地文件系统获取文件列表,为一个集合FileStatus[] fileStatuses = local.listStatus(newPath("file:///E:\\input" ) );for (FileStatus fileStatus : fileStatuses) {FSDataInputStream inputStream = local.open(fileStatus.getPath());IOUtils.copy(inputStream, outputStream);IOUtils.closeQuietly(inputStream);}IOUtils.closeQuietly(outputStream);local.close();fileSystem.close();
}
这篇关于3.HDFS的客户端操作—环境准备(Windows10上安装与配置 Hadoop3.2 环境)、API操作、I/O流操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




