groupingcomparator专题

hadoop入门7:自定义GroupingComparator进行分组
摘要: GroupingComparator是在reduce阶段分组来使用的,由于reduce阶段,如果key相同的一组,只取第一个key作为key,迭代所有的values。 如果reduce的key是自定义的bean,我们只需要bean里面的某个属性相同就认为这样的key是相同的,这是我们就需要之定义GroupCoparator来“欺骗”reduce了。 我们需要理清楚的还有map阶段你的几个

Hadoop入门之自定义groupingcomparator和outputformat的使用
自定义outputformat输出demo类: /*** maptask或者reducetask在最终输出时,先调用OutputFormat的getRecordWriter方法拿到一个RecordWriter* 然后再调用RecordWriter的write(k,v)方法将数据写出* * @author* */public class LogEnhanceOutputFormat e
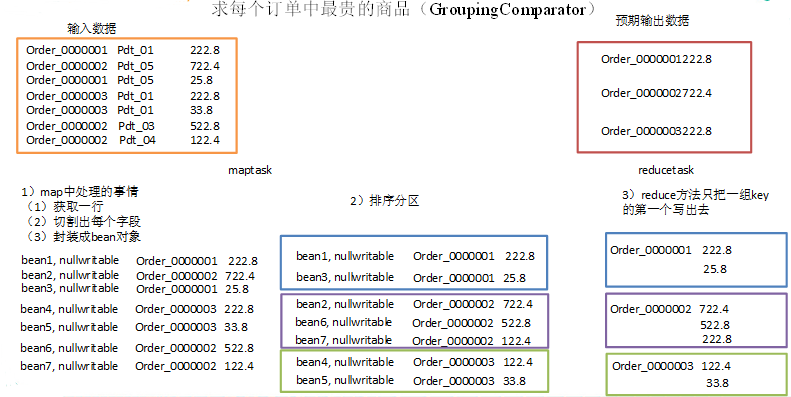
Hadoop案例(八)辅助排序和二次排序案例(GroupingComparator)
辅助排序和二次排序案例(GroupingComparator) 1.需求 有如下订单数据 订单id 商品id 成交金额 0000001 Pdt_01 222.8 0000001 Pdt_05 25.8 0000002 Pdt_03 522.8 0000002 Pdt_04 122.4 0000002 Pdt_05 722.4 0000003 Pdt_01