gqa专题

GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC)
0x0. 前言 在openreview上看到最近NV的一个KV Cache压缩工作:https://openreview.net/pdf?id=tDRYrAkOB7 ,感觉思路还是有一些意思的,所以这里就分享一下。 简单来说就是paper提出通过一种特殊的方式continue train一下原始的大模型,可以把模型在generate过程中的KV Cache分成多个段,并且每个token都会学出
大模型都在用的GQA是什么
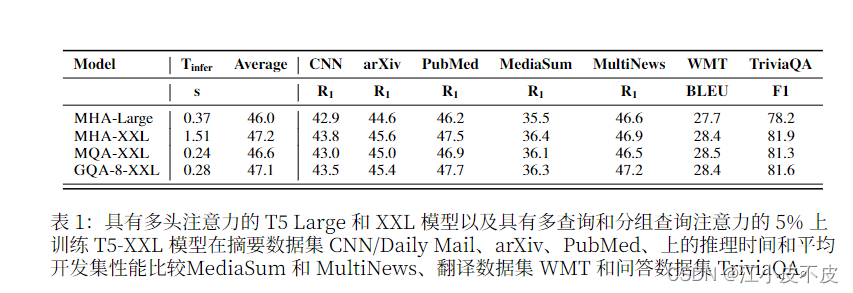
论文:Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 更详细内容直接看原文!!! 摘要 Multi-query attention(MQA)只使用一个键值头,大大加快了解码器推理。然而,MQA可能导致质量下降,而且不为了更快的推断而训练一个单独的模型。我们提出了一个方法,
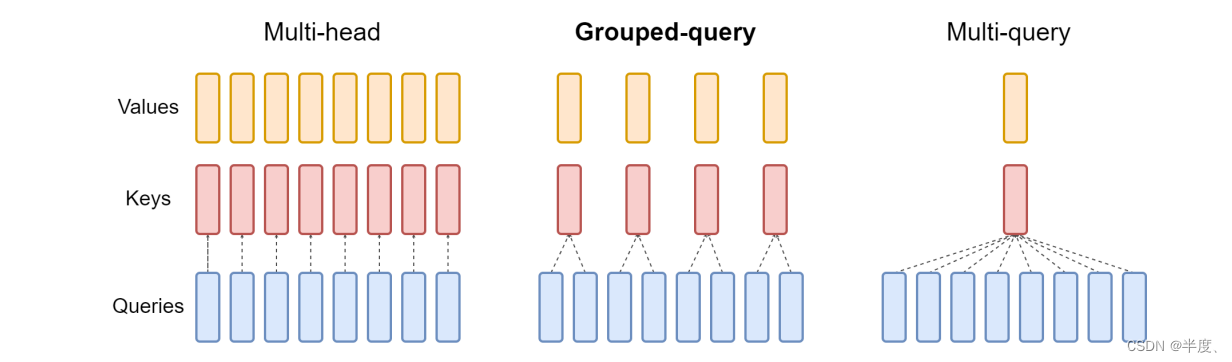
MHD、MQA、GQA注意力机制详解
MHD、MQA、GQA注意力机制详解 注意力机制详解及代码前言:MHAMQAGQA 注意力机制详解及代码 前言: 自回归解码器推理是 Transformer 模型的 一个严重瓶颈,因为在每个解码步骤中加 载解码器权重以及所有注意键和值会产生 内存带宽开销 下图为三种注意力机制的结构图和实验结果 MHA 多头注意力机制是Transformer模型中的核心组
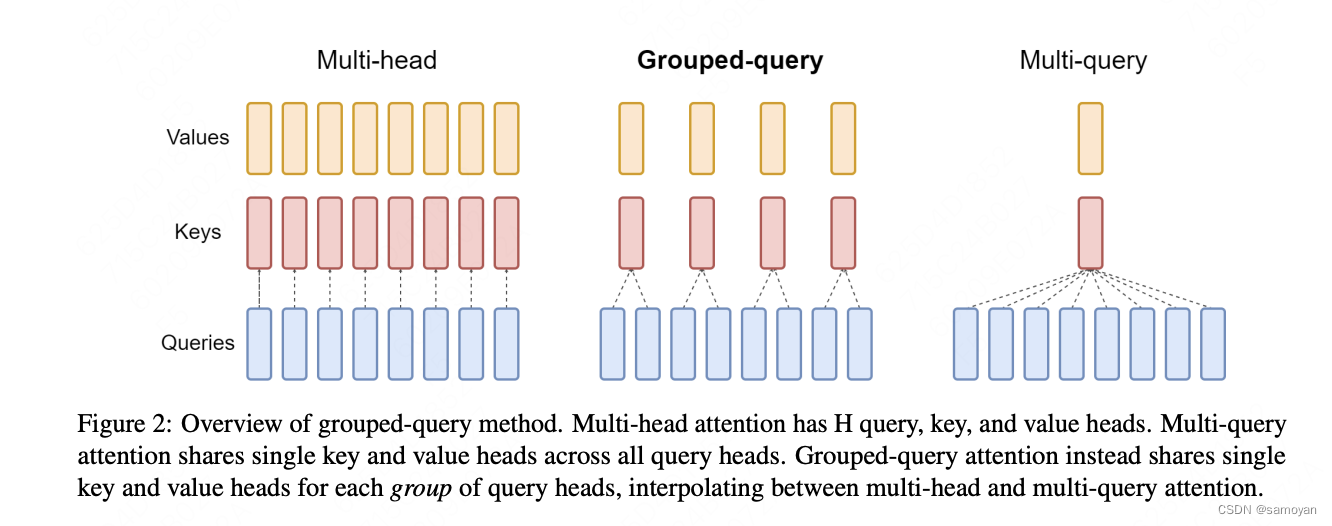
Group Query Attention (GQA) 机制详解以及手动实现计算
Group Query Attention (GQA) 机制详解 1. GQA的定义 Grouped-Query Attention (GQA) 是对 Multi-Head Attention (MHA) 和 Multi-Query Attention (MQA) 的扩展。通过提供计算效率和模型表达能力之间的灵活权衡,实现了查询头的分组。GQA将查询头分成了G个组,每个组共享一个公共的键(
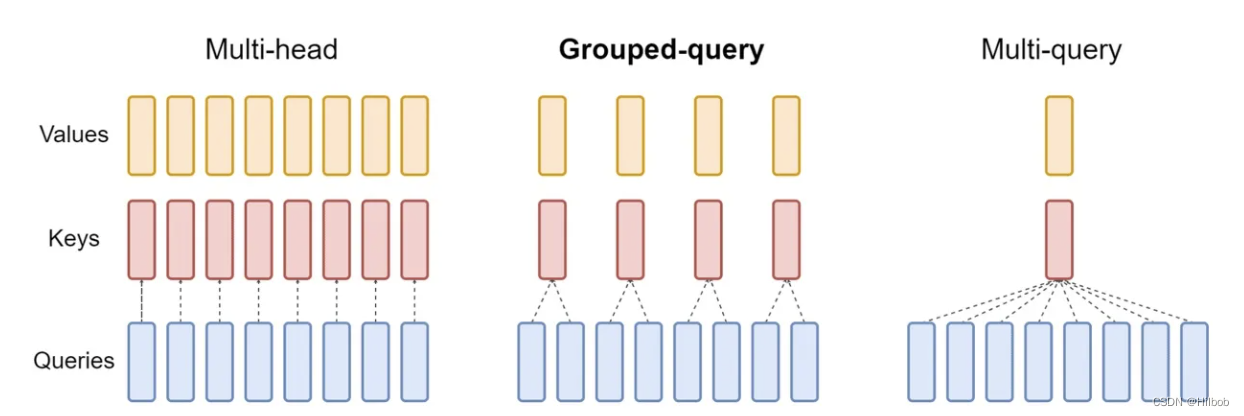
【NLP】MHA、MQA、GQA机制的区别
Note LLama2的注意力机制使用了GQA。三种机制的图如下: MHA机制(Multi-head Attention) MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 Value 矩阵权重不共享 MQA机制(Multi-Query Attention) MQA(Multi-Que