former专题

【论文极速读】 指令微调BLIP:一种对指令微调敏感的Q-Former设计
【论文极速读】 指令微调BLIP:一种对指令微调敏感的Q-Former设计 FesianXu 20240330 at Tencent WeChat search team 前言 之前笔者在[1]中曾经介绍过BLIP2,其采用Q-Former的方式融合了多模态视觉信息和LLM,本文作者想要简单介绍一个在BLIP2的基础上进一步加强了图文指令微调能力的工作——InstructBLIP,希
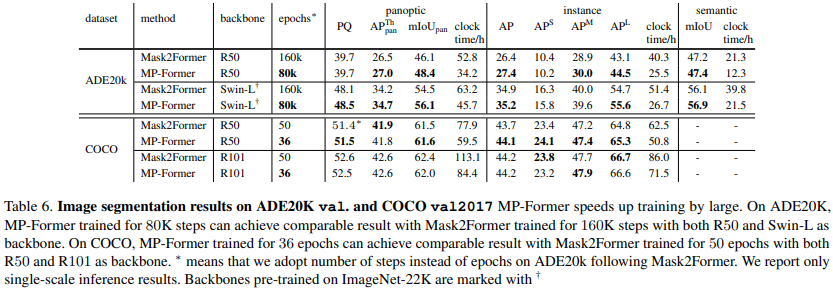
论文阅读——MP-Former
MP-Former: Mask-Piloted Transformer for Image Segmentation https://arxiv.org/abs/2303.07336 mask2former问题是:相邻层得到的掩码不连续,差别很大 denoising training非常有效地稳定训练时期之间的二分匹配。去噪训练的关键思想是将带噪声的GT坐标与可学习查询并

BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法 FesianXu 20240202 at Baidu Search Team 前言 大规模语言模型(Large Language Model,LLM)是当前的当红炸子鸡,展现出了强大的逻辑推理,语义理解能力,而视觉作为人类最为主要的感知世界的手段,亟待和LLM进行融合,形成多模态大规模语言模型(Multimodal L
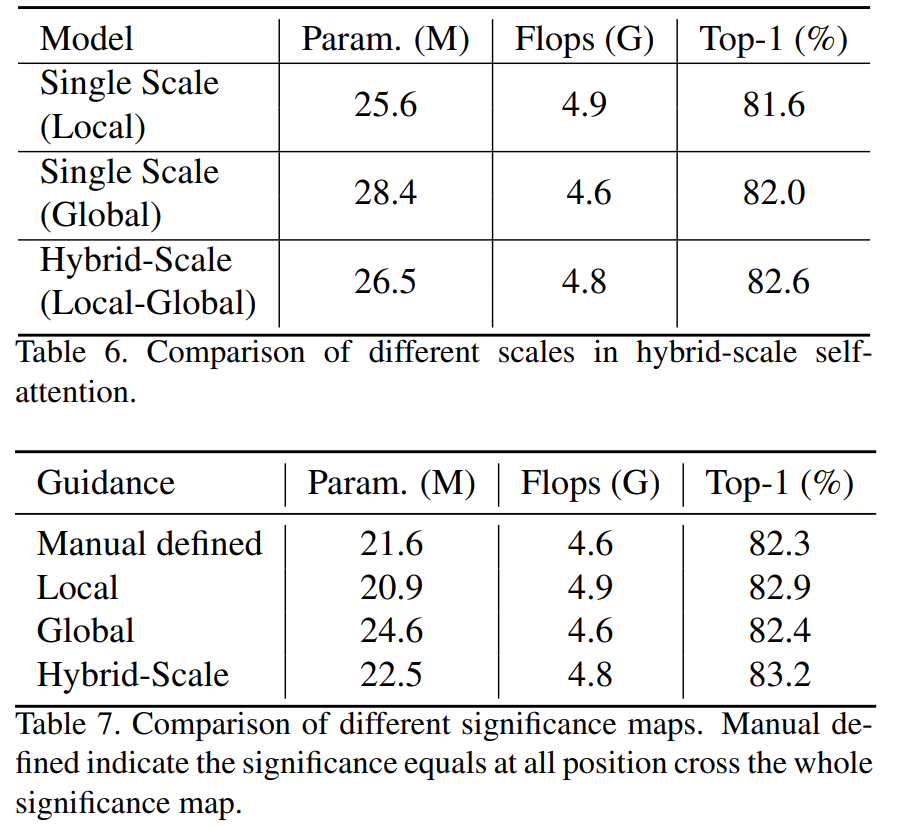
论文阅读——SG-Former
SG-Former: Self-guided Transformer with Evolving Token Reallocation 1. Introduction 方法的核心是利用显著性图,根据每个区域的显著性重新分配tokens。显著性图是通过混合规模的自我关注来估计的,并在训练过程中自我进化。直观地说,我们将更多的tokens分配给显著区域,以实现细粒度的关注,而将更少的tok
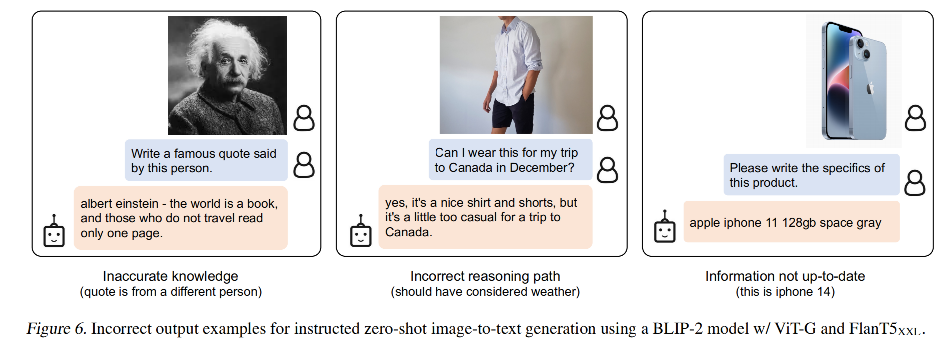
【多模态】6、BLIP-2 | 使用 Q-Former 连接冻结的图像和语言模型 实现高效图文预训练
文章目录 一、背景二、方法2.1 模型结构2.2 从 frozen image encoder 中自主学习 Vision-Language Representation2.3 使用 Frozen LLM 来自主学习 Vision-to-Language 生成2.4 Model pre-training 三、效果四、局限性 论文:BLIP-2: Bootstrapping La
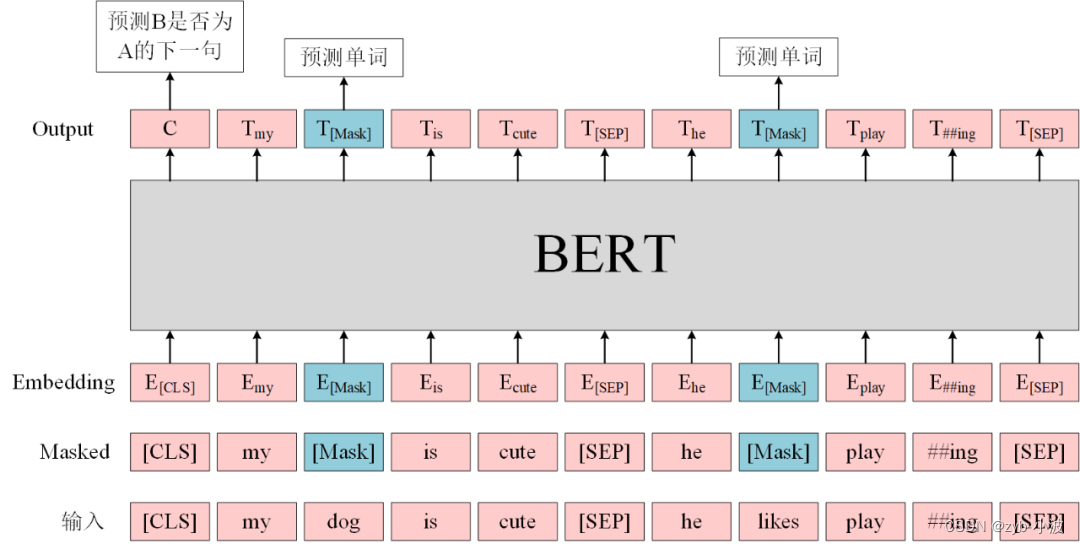
BLIP2中Q-former详解
简介 Querying Transformer,在冻结的视觉模型和大语言模型间进行视觉-语言对齐。 为了使Q-Former的学习达到两个目标: 学习到和文本最相关的视觉表示。 这种表示能够为大语言模型所解释。 需要在Q-Former结构设计和训练策略上下功夫。具体来说, Q-Former是一个轻量级的transformer,它使用一个可学习的query向量集,从冻结的视觉模型提取