本文主要是介绍论文阅读——MP-Former,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MP-Former: Mask-Piloted Transformer for Image Segmentation
https://arxiv.org/abs/2303.07336
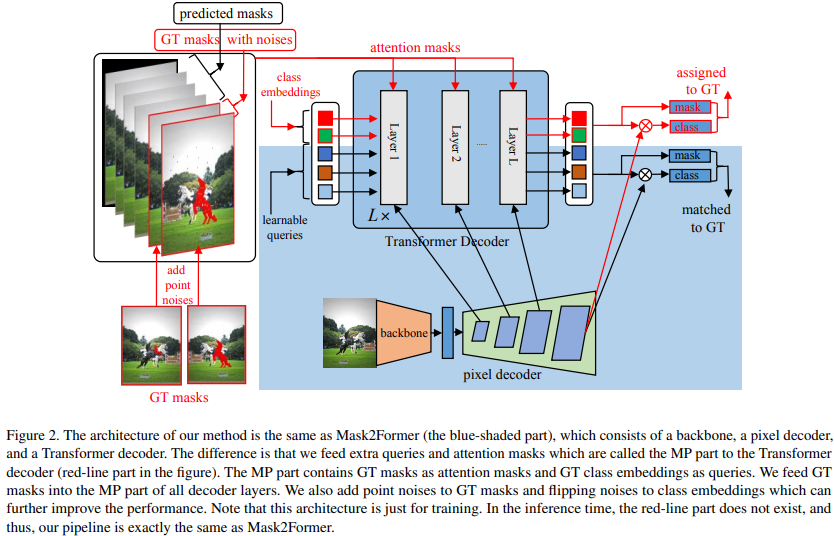
mask2former问题是:相邻层得到的掩码不连续,差别很大

denoising training非常有效地稳定训练时期之间的二分匹配。去噪训练的关键思想是将带噪声的GT坐标与可学习查询并行地送到Transformer解码器中,并训练模型去噪和恢复GT边框坐标。MPFormer去噪训练的思想从DN-DETR来,改进的mask2former模型。
MPformer送入class embeddings作为查询,给每层解码层送入GT masks作为attention masks,然后让模型重建类别和masks。
mask2former提出的mask attention可以使得训练时容易收敛。作者发现使得Vit类模型容易收敛的一些常识为给可学习的查询明确的意义,减少不确定性;二是给交叉注意力局部限制,更好的找到目标。因此作者认为给交叉注意力明确的导向可以提高分割性能。和DN-DETR不同,MPformer噪声可选择,可以没有。
作者把mask2former看做一个掩码不断精细化的过程,一层的预测作为下一层的attention masks。
MPformer是每层将GTmask作为attention masks,由于每层大小不一样,所以把GT使用双线性插值到不同分辨率。
加噪声的三种方式:

点噪声表现最好,所以用的点噪声。
Label-guided training:class embeddings会对应一个classification loss,class embeddings加噪声。
两种噪声,类别和掩码噪声的比例给的是0.2。
辅助函数:

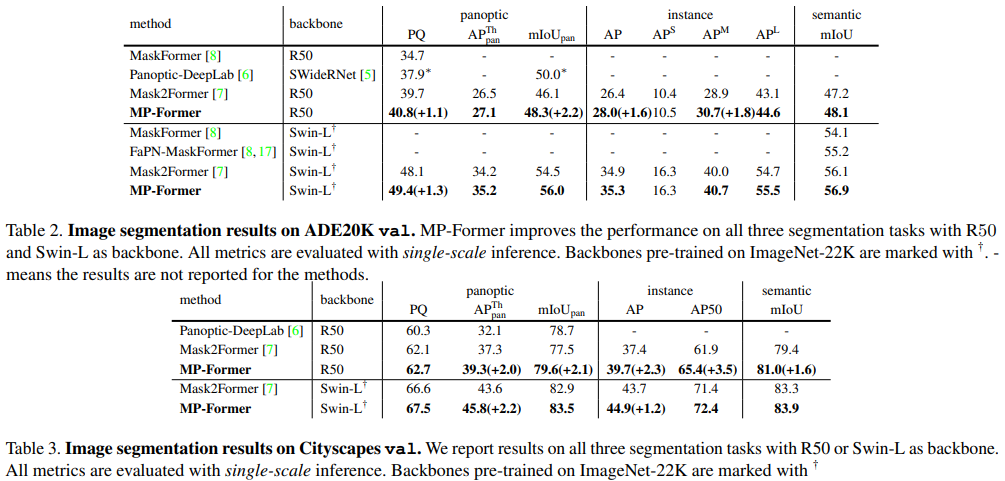
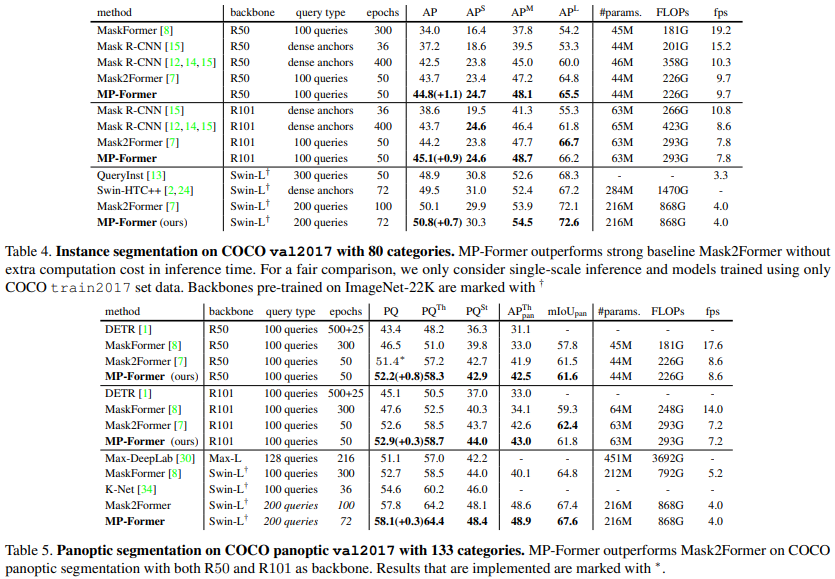
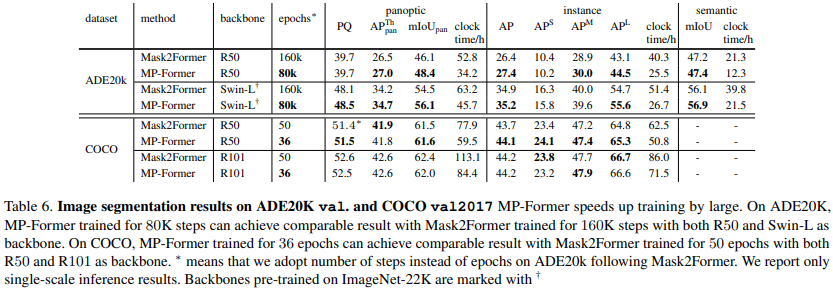
结果
这篇关于论文阅读——MP-Former的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
