flinkcdc专题

三.海量数据实时分析-FlinkCDC实现Mysql数据同步到Doris
FlinkCDC 同步Mysql到Doris 参考:https://nightlies.apache.org/flink/flink-cdc-docs-release-3.0/zh/docs/get-started/quickstart/mysql-to-doris/ 1.安装Flink 下载 Flink 1.18.0,下载后把压缩包上传到服务器,使用tar -zxvf flink-xxx-
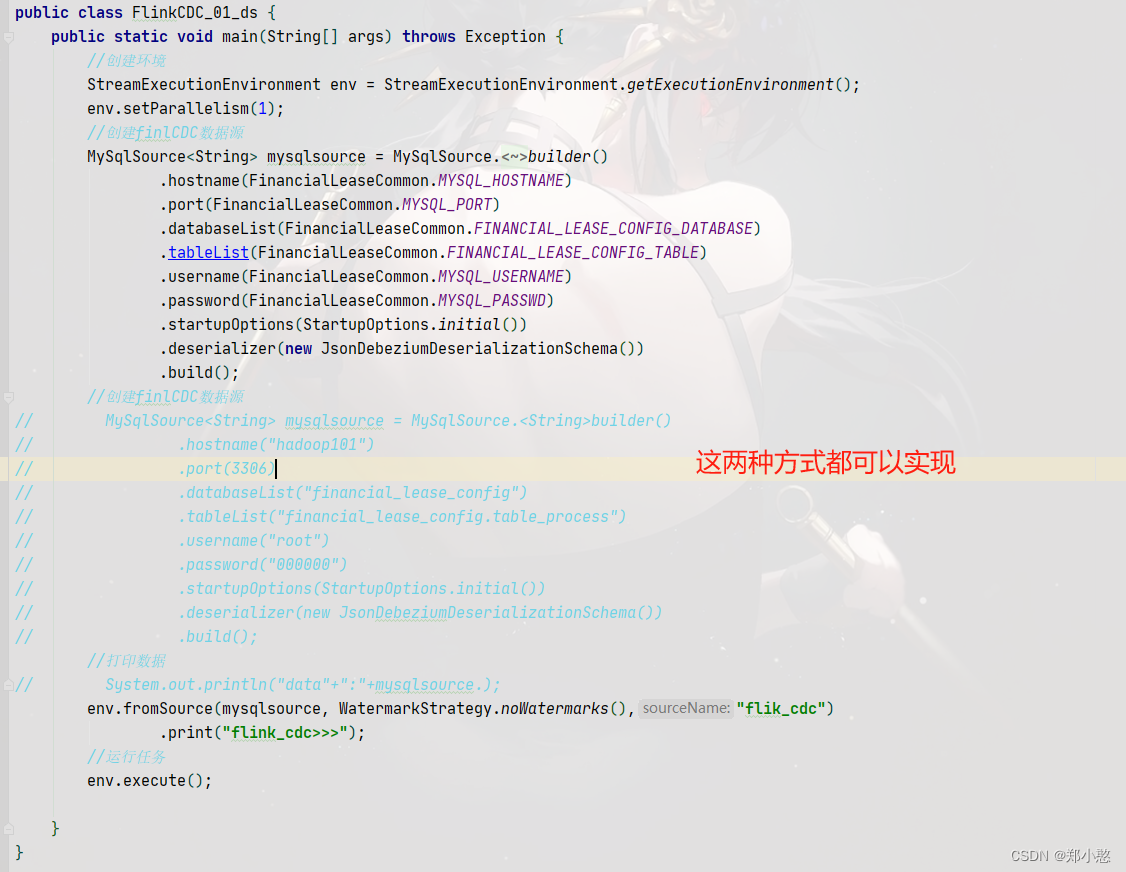
FlinkCDC介绍及使用
CDC简介 什么是CDC? cdc是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的 变动(包括数据或数据表的插入,更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件以供其它服务进行订阅及消费 CDC的种类? CDC主要分为基于查询和基于Binlog两种方式,咱

垃圾的flinkcdc
在 MySQL 中,创建表时使用反引号 ` 将表名或字段名括起来的作用是: 保留字和关键字: 使用反引号可以避免使用MySQL的保留字和关键字作为表名或字段名时产生的冲突。比如,你可以创建一个名为 select 或 order 的表: sqlCopy Code CREATE TABLE `select` ( id INT AUTO_INCREMENT PRIMARY KEY, name VA

Flinkcdc通过catalog同步mysql数据到hologres的ods中
Flinkcdc通过catalog同步mysql数据到hologres的ods中大致分为以下几步: 配置Flink CDC 的MySQL catalog: CREATE CATALOG mysqlsourceWITH ('type' = 'mysql','hostname' = 'xxxx','port' = 'xxxx','username' = 'xxxx'<

flinkcdc 3.0 架构设计学习
本文将会了解到flinkcdc3.0版本的架构设计,从一个宏观层面来学习flinkcdc3.0带来的新特性 这也是作者目前觉得学习一项技术的思路和方法,就是首先先把demo跑起来体验一下,然后整体了解一下架构设计,应用场景等,之后再去学习技术细节和源码,由浅入深的学习. 文中内容有误请多多包涵,欢迎评论区或者加笔者微信指教. 一.概述 Flink CDC(Change Data Capu

用flinkcdc debezium来捕获数据库的删除内容
我在用flinkcdc把数据从sqlserver写到doris 正常情况下sqlserver有删除数据,doris是能捕获到并很快同步删除的。 但是我现在情况是doris做为数仓,数据写到ods,ods的数据还会通过flink计算后写入dwd层,所以此时ods的数据是删除了,但是dwd甚至ads的都没删除,这样就会有脏数据。此时我们就需要去捕获被删除的数据,就要用到debezium插件。 利
flinkcdc 3.0 尝鲜
本文会将从环境搭建到demo来全流程体验flinkcdc 3.0 包含了如下内容 flink1.18 standalone搭建doris 1fe1be 搭建整库数据同步测试各同步场景从检查点重启同步任务 环境搭建 flink环境(Standalone模式) 下载flink 1.18.0 链接 : https://archive.apache.org/dist/flink/flink-1
大数据技术14:FlinkCDC数据变更捕获
前言:Flink CDC是Flink社区开发的flink-cdc-connectors 组件,这是⼀个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。 https://github.com/ververica/flink-cdc-connectors 一、CDC 概述 CDC 的全称是 Change Data Capture ,

flinkcdc 体验
0 flink版本 踩雷 java代码操作 flink Table/SQL API 和 DataStream API 编写程序后,打成jar包丢到flink集群运行,报错首选需要考虑flink集群版本和 jar包中maven依赖的版本是否一致。 目前网上flink、flinkcdc相关博文绝大部分是基于flink1.13、1.14编写的,而我的flink集群是1.15! 而flink1.15由于