本文主要是介绍FlinkCDC介绍及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CDC简介
什么是CDC?
cdc是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的
变动(包括数据或数据表的插入,更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件以供其它服务进行订阅及消费
CDC的种类?
CDC主要分为基于查询和基于Binlog两种方式,咱们主要了解一下这两种的区别:
| 基于查询的CDC | 基于Binlog的CDC | |
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、Maxwell、Debezium |
| 执行模式 | Batch | Streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
FlinkCDC案例实操
开启MySQL Binlog并重启MySQL
sudo vim/etc/my.cnf
把需要监控的数据库名写入到里面
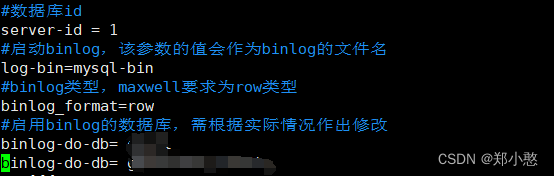
重启mysql
sudo systemctl restart mysqld
DataStream方式的应用
导入依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.1</flink.version>
<flink-cdc.vesion>2.4.0</flink-cdc.vesion>
<hadoop.version>3.3.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<!--如果保存检查点到hdfs上,需要引入此依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client-api</artifactId>
<version>${hadoop.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client-runtime</artifactId>
<version>${hadoop.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.36</version>
</dependency>
<!--cdc 依赖-->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink-cdc.vesion}</version>
</dependency>
<!-- flink sql 相关的依赖: 使用 cdc 必须导入 sql 依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
编写代码

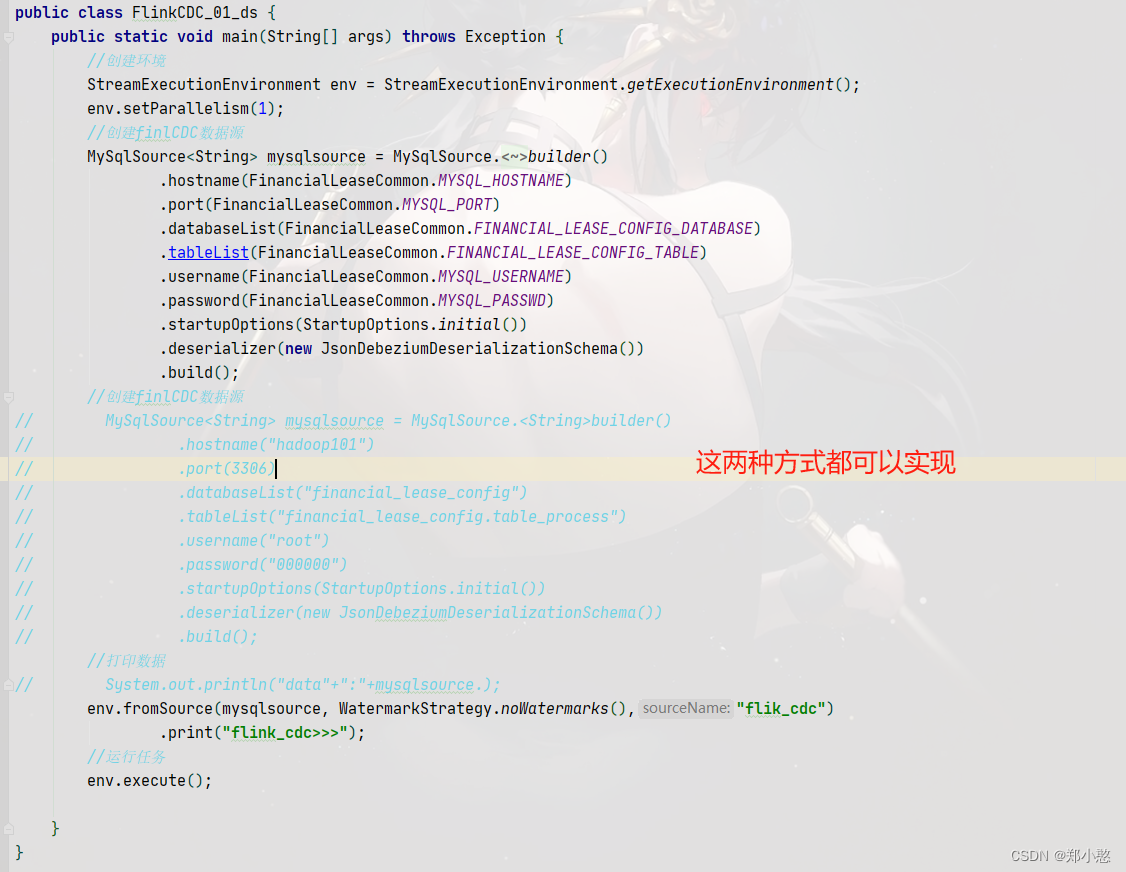
这篇关于FlinkCDC介绍及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







