flink1.17专题

Flink1.17之前实现JdbcLookup谓词下推
Flink1.17之前实现JdbcLookup谓词下推 需求背景 Flink在1.17版本之前,flink-connector-jdbc的LookupJoin是不支持on条件下推的,例如on device_id=‘1’,查询SQL中是不会包含device_id='1’的条件,相关issue:https://issues.apache.org/jira/browse/FLINK-32321,在1
CentOS7安装flink1.17完全分布式
前提条件 准备三台CenOS7机器,主机名称,例如:node2,node3,node4 三台机器安装好jdk8,通常情况下,flink需要结合hadoop处理大数据问题,建议先安装hadoop,可参考 hadoop安装 Flink集群规划 node2node3node4 JobManager TaskManager TaskManagerTaskManager 下载安装包 在n
Flink1.17 基础知识
Flink1.17 基础知识 来源:B站尚硅谷 目录 Flink1.17 基础知识Flink 概述Flink 是什么Flink特点Flink vs SparkStreamingFlink的应用场景Flink分层API Flink快速上手创建项目WordCount代码编写批处理流处理 Flink部署集群角色部署模式会话模式(Session Mode)单作业模式(Per-Job Mode)应
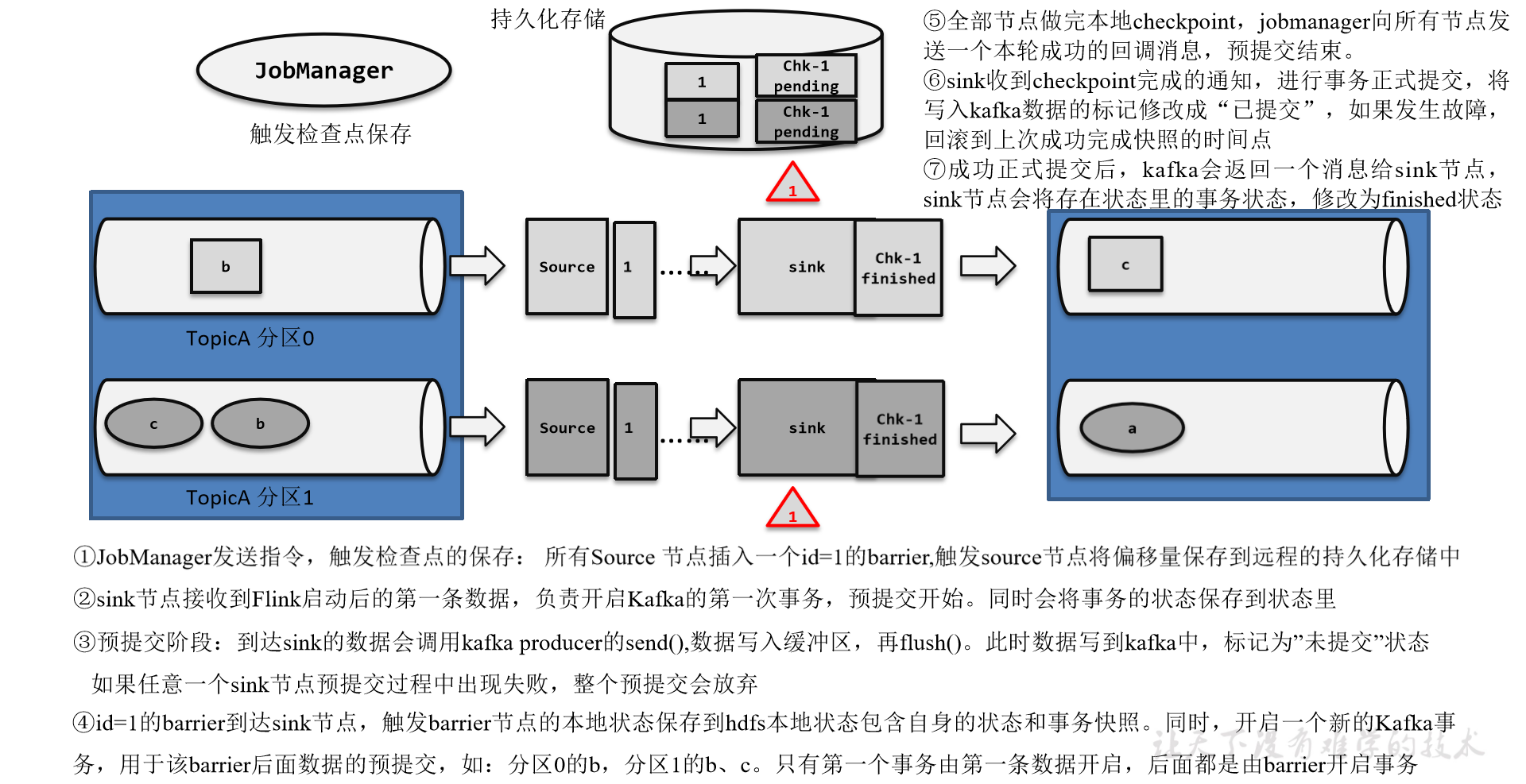
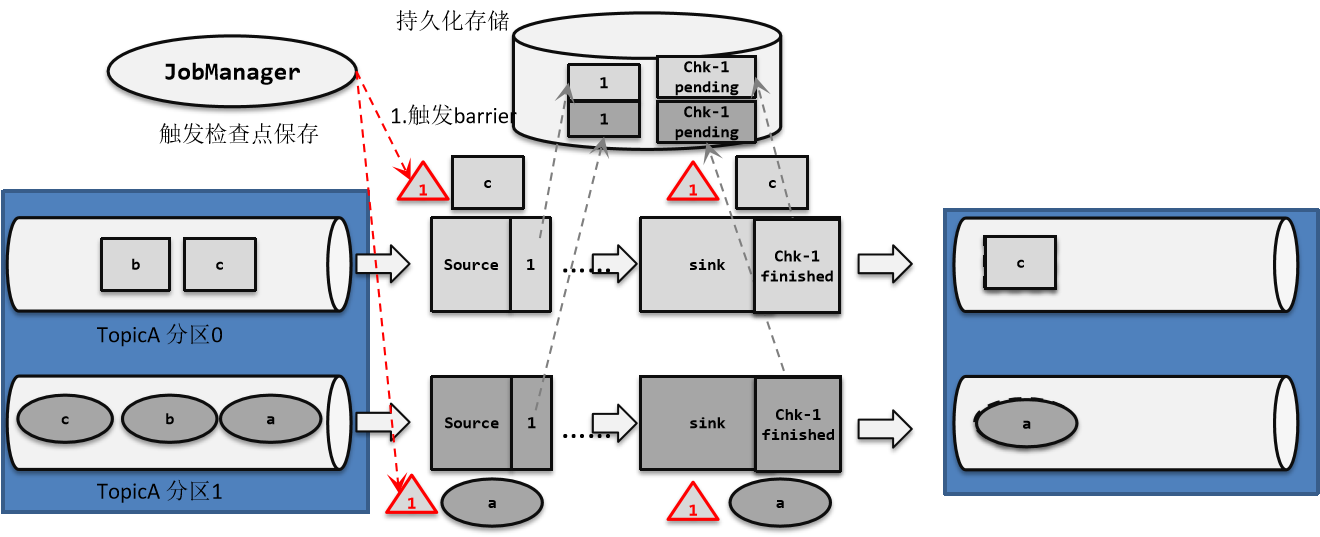
Flink1.17实战教程(第六篇:容错机制)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程(第四篇:处理函数) Flink1.17实战教程(第五篇:状态管理) Flink1.17实战教程(第六篇:容错机制) Flink1.17实战教程(第七篇:Flink SQL)

Flink1.17实战教程(第七篇:Flink SQL)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程(第四篇:处理函数) Flink1.17实战教程(第五篇:状态管理) Flink1.17实战教程(第六篇:容错机制) Flink1.17实战教程(第七篇:Flink SQL)
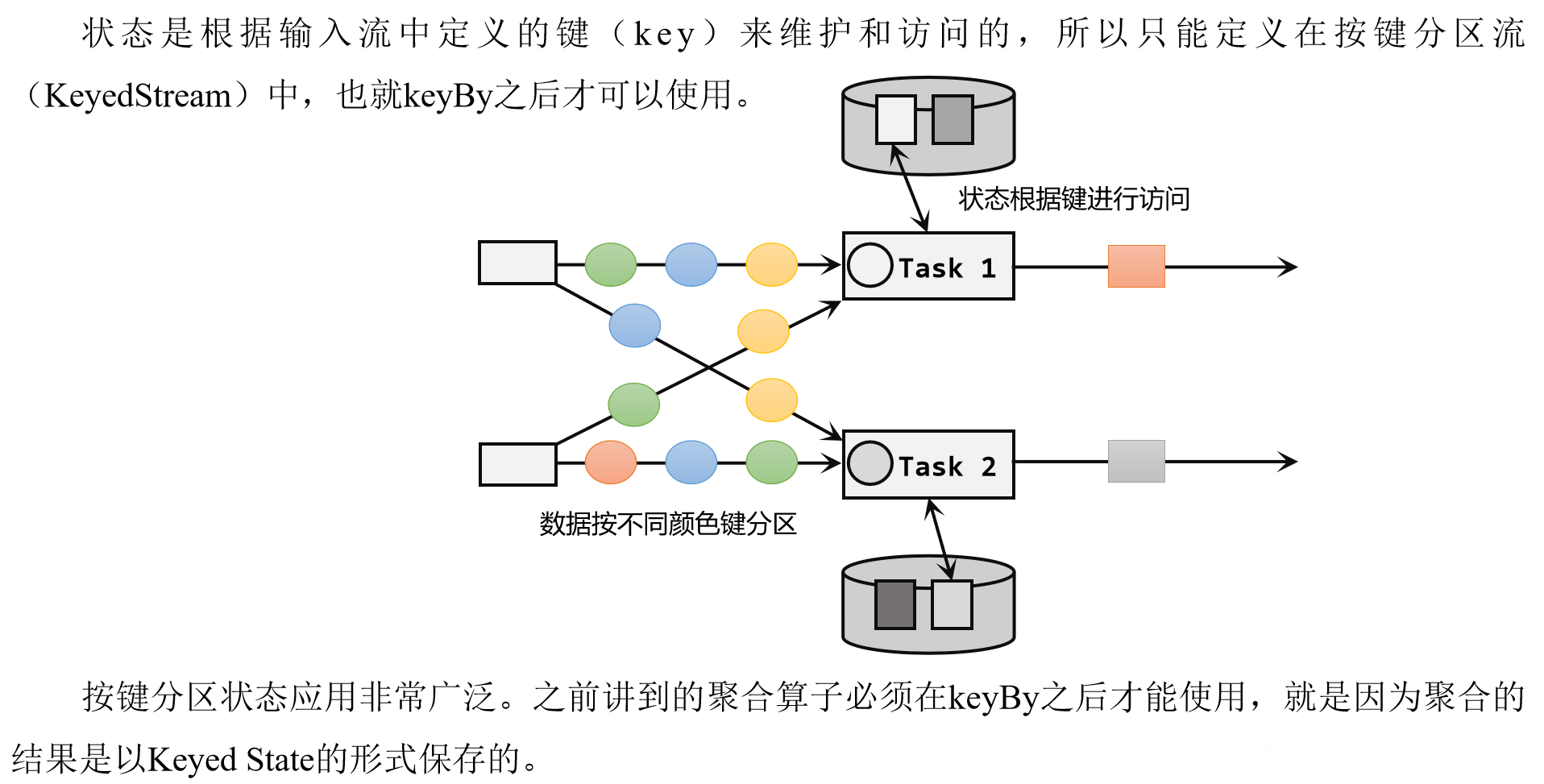
Flink1.17实战教程(第五篇:状态管理)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程(第四篇:处理函数) Flink1.17实战教程(第五篇:状态管理) Flink1.17实战教程(第六篇:容错机制) Flink1.17实战教程(第七篇:Flink SQL)

Flink1.17实战教程(第三篇:时间和窗口)
系列文章目录 Flink1.17实战教程(第一篇:概念、部署、架构) Flink1.17实战教程(第二篇:DataStream API) Flink1.17实战教程(第三篇:时间和窗口) Flink1.17实战教程(第四篇:处理函数) Flink1.17实战教程(第五篇:状态管理) Flink1.17实战教程(第六篇:容错机制) Flink1.17实战教程(第七篇:Flink SQL)
flink1.17部署模式和部署方法
文章目录 前言一、部署模式1.会话模式(Session Mode)2.单作业模式(Per-Job Mode)3.应用模式(Application Mode) 二、运行模式1.Standalone运行模式1.1 会话模式部署(本文采用此方式部署)1.2 单作业模式部署1.3 应用模式部署 2.YARN运行模式2.1 会话模式部署2.2 单作业模式部署2.3 应用模式部署 3.K8S 运行模式

Python 编写 Flink 应用程序经验记录(Flink1.17.1)
目录 官方API文档 提交作业到集群运行 官方示例 环境 编写一个 Flink Python Table API 程序 执行一个 Flink Python Table API 程序 实例处理Kafka后入库到Mysql 下载依赖 flink-kafka jar 读取kafka数据 写入mysql数据 flink-mysql jar 官方API文档 https
linux安装部署flink1.17
文章目录 前言一、flink下载二、配置三、启动结尾 前言 Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。目前市场上主流的流式计算框架有Apache Storm、Spark Streaming、Apache Flink等,但能够同时支持低延迟、