本文主要是介绍linux安装部署flink1.17,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、flink下载
- 二、配置
- 三、启动
- 结尾
前言
Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。目前市场上主流的流式计算框架有Apache Storm、Spark Streaming、Apache Flink等,但能够同时支持低延迟、高吞吐、Exactly-Once(收到的消息仅处理一次)的框架只有Apache Flink。
Flink是原生的流处理系统,但也提供了批处理API,拥有基于流式计算引擎处理批量数据的计算能力,真正实现了批流统一。与Spark批处理不同的是,Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
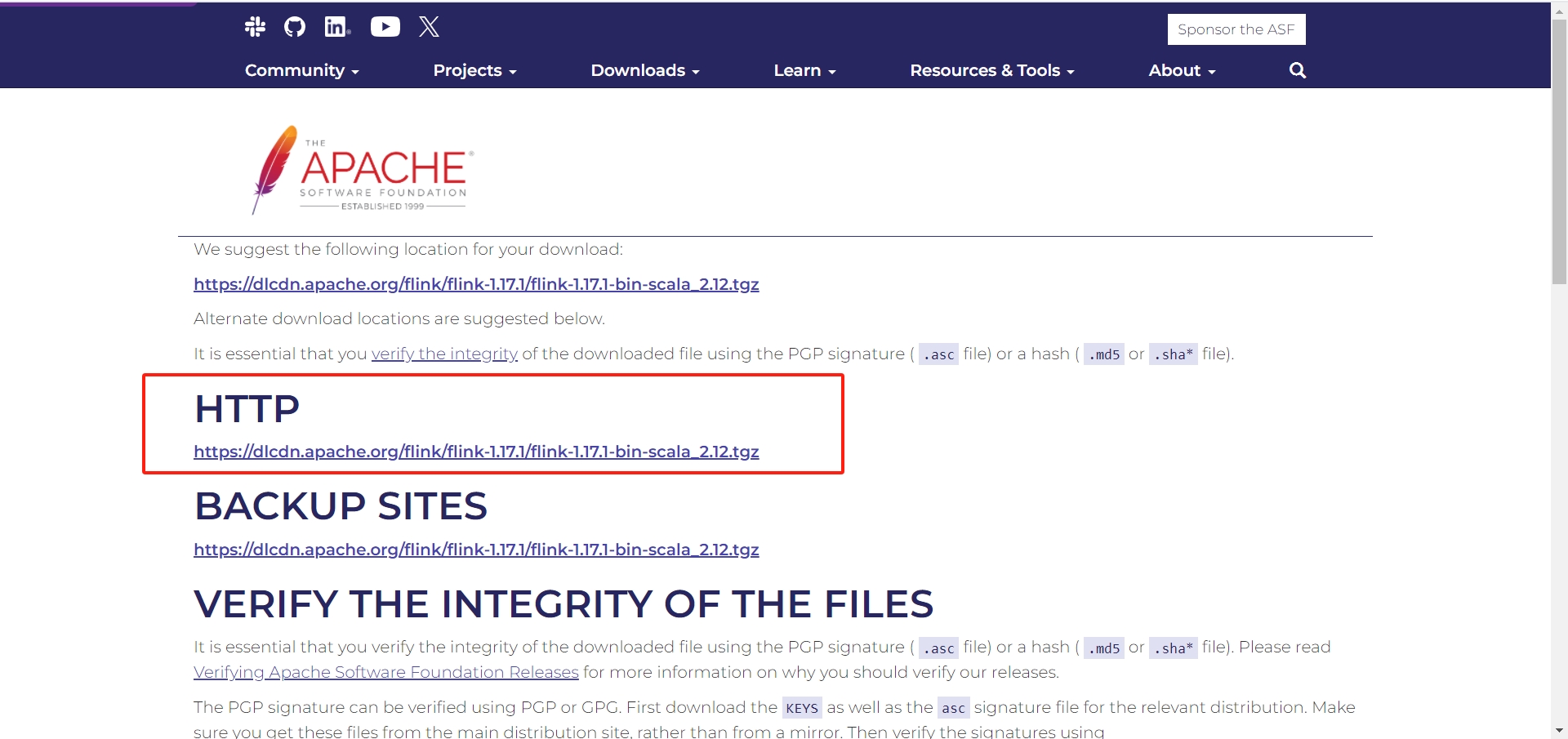
一、flink下载
https://www.apache.org/dyn/closer.lua/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
二、配置
#修改配置文件
vim conf/flink-conf.yaml
新增或修改如下配置
taskmanager.numberOfTaskSlots: 8
rest.bind-address: 0.0.0.0
#自定义IP可设置
rest.port: 31992
三、启动
#启动
./bin/start-cluster.sh
web页面地址 :http://localhost:8081/
结尾
- 感谢大家的耐心阅读,如有建议请私信或评论留言。
- 如有收获,劳烦支持,关注、点赞、评论、收藏均可,博主会经常更新,与大家共同进步
这篇关于linux安装部署flink1.17的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!