filebeat专题

ELK系列之四---如何通过Filebeat和Logstash优化K8S集群的日志收集和展示
前 言 上一篇文章《日志不再乱: 如何使用Logstash进行高效日志收集与存储》介绍了使用ELK收集通用应用的日志,在目前大多应用都已运行在K8S集群上的环境,需要考虑怎么收集K8S上的日志,本篇就介绍一下如何使用现有的ELK平台收集K8S集群上POD的日志。 K8S日志文件说明 一般情况下,容器中的日志在输出到标准输出(stdout)时,会以.log的命名方式保存在/var/log/po

Elastic Stack(四):filebeat介绍及安装
目录 1 filebeat介绍1.1 filebeat和beat的关系1.2 filebeat是什么1.3 filebeat工作原理1.4 传输方案 2 安装2.1 filebeat-源码包安装8.11、下载2、创建密钥库3、修改filebeat配置文件修改filebeat配置文件(使用模块的配置) 4、配置快速启动文件注意 5、在kibana中查看 1 filebeat介绍

构建ELK+Filebeat+kafka+zookeeper大数据日志分析平台
https://blog.csdn.net/weixin_45623111/article/details/137143863?spm=1001.2014.3001.5502 在构建 ELK (Elasticsearch, Logstash, Kibana) + Filebeat + Kafka + Zookeeper 的大数据日志分析平台中,数据流向 filebeat -> logstash

Filebeat进阶指南:核心架构与功能组件的深度剖析
🐇明明跟你说过:个人主页 🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是ELK 2、FileBeat在ELK中的角色 二、FileBeat核心架构 1、Filebeat的整体架构图 2、核心组件 注册表(Registrar) 3、核心组件 爬虫(Harvester) 4、核心组件 发布者(Publisher

使用filebeat采集文件到es中
继上一篇logstash采集日志。 之前用logstash做日志采集,但是发现logstash很占用机器资源导致机器运行有点慢。查询资料表明logstash使用Java编写,插件是使用jruby编写,对机器的资源要求会比较高,网上有一篇关于其性能测试的报告。之前做过和filebeat的测试对比。在采集日志方面,对CPU,内存上都要比前者高很多。那么果断使用filebeat作为替代方案。走起!
filebeat源码分析服务启动
在开始源码分析之前先说一下filebeat是什么?beats是知名的ELK日志分析套件的一部分。它的前身是logstash-forwarder,用于收集日志并转发给后端(logstash、elasticsearch、redis、kafka等等)。filebeat是beats项目中的一种beats,负责收集日志文件的新增内容。当前的代码分支是最新的6.x的代码。 先看我们服务启动配置文件的一个例子

elk+filebeat+kafka日志收集方案
文章目录 架构图搭建安装zookeeper集群安装kafka集群安装kafka-manager 管理平台安装elasticsearch集群安装filebeat安装logstash安装kibana 架构图 搭建 安装zookeeper集群 tar -zxf /opt/files/zookeeper-3.4.8.tar.gz -C /opt/env vim /op
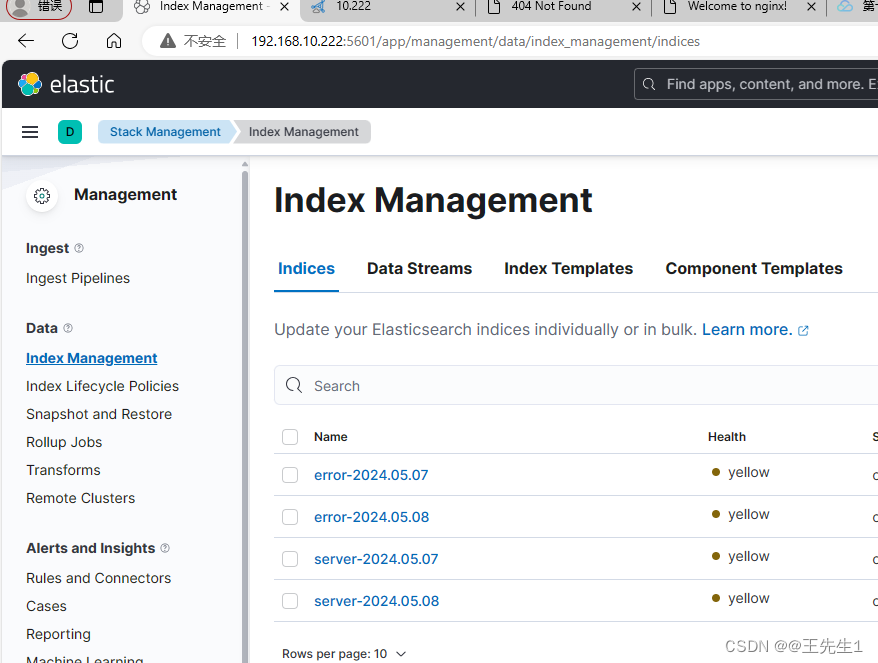
elk + filebeat 8.4.3 收集nginx日志(docker部署)
ELK filebeat docker部署 一、 elasticsearch部署1、运行elasticsearch临时配置容器2、拷贝文件目录到本地3、检查elasticsearch.yml4、删除之前elastic,运行正式容器5、docker logs记录启动日志 二、部署kibana1、运行kibana临时配置容器2、docker拷贝配置文件到本地,3、删除之前kibana,运行正式容
ELK之Filebeat实用配置及批量部署(部署200+可用)
跟我之前Zabbix-agent批量部署脚本Linux and Windows(部署300+可用)文章的套路一样,在使用该脚本前,请先准备好安装包及配置好安装包的资源下载点,由于我这边是纯内网,所以我就找了一个NAS做了共享目录,用于安装脚本去下载安装包 至于怎么做共享目录就不多说,我的目录包含4个文件: filebeat.service#用于配置filebeat服务及自启动filebeat.

【ELFK】Filebeat+ELK 部署
Filebeat+ELK 部署 在 Filebeat 节点上操作 环境准备 Node1节点(2C/4G):node1/192.168.67.11 Elasticsearch KibanaNode2节点(2C/4G):node2/192.168.67.12 ElasticsearchApache节点:apache/192.168.67.10
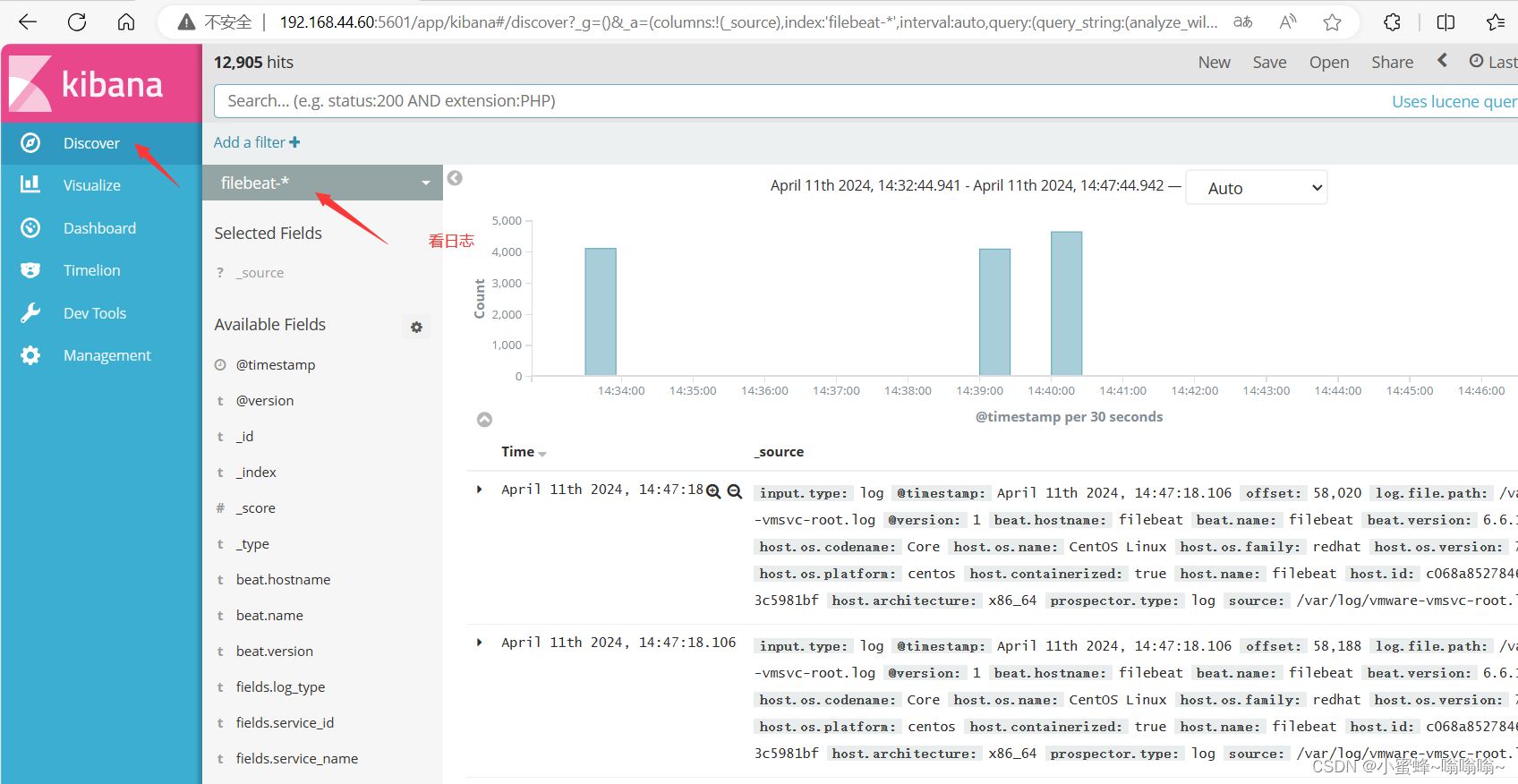
ELFK (Filebeat+ELK)日志分析系统
一. 相关介绍 Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。行解析 filebeat 结合 logs

(20201222已解决)config file (“filebeat.yml“) must be owned by the user identifier (uid=0) or root
问题描述 在Filebeat 容器内运行: ./filebeat modules list 出现错误: Error initializing beat: error loading config file: config file (“filebeat.yml”) must be owned by the user identifier (uid=0) or root 解决方案 ll查看

filebeat作为daemonSet
创建 Filebeat 服务账户和 ClusterRole apiVersion: v1kind: Namespacemetadata:name: logging---apiVersion: v1kind: ServiceAccountmetadata:name: filebeatnamespace: logginglabels:k8s-app: filebeat---apiVe
ELK之使用Filebeat插件收集日志到Logstash
对于Springboot项目接入ELK非常方便,对于非maven,非Spring项目来说就比较复杂,这个时候我们就可以使用Filebeat插件还完成日志的收集发送工作。 Filebeat介绍 Filebeat是用于转发和收集数据的轻量级工具,Filebeat可以监视指定的日志文件或位置,收集日志事件,并将数据转发到Elasticsearch或Logstash进行存储。 Filebeat的工作
Filebeat rpm方式安装及配置
一、使用服务器root用户、filebeat8.11.1版本,rpm安装方式进行安装 curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.11.1-x86_64.rpm sudo rpm -vi filebeat-8.11.1-x86_64.rpm 二、配置核心的采集文件、使用inputs
docker部署filebeat
一、背景 最近公司用到了filebeat,所以学习了下这个技术。filebeat是一个轻量级的日志采集工具,使用golang语言开发,可以将日志转发到es,kafka等。官方对filebeat提供了最全面的支持。filebeat的性能非常好,部署简单,是一个非常理想的文件采集工具。相比logstash它的内存占用更少,filebeat开发的目的也是为了替换logstash。当然也有缺点,比如fi
centos7 部署filebeat
先决条件参考 虚拟机部署elasticsearch集群-CSDN博客 下载并安装filebeat的rpm包 curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.18-x86_64.rpmrpm -vi filebeat-7.17.18-x86_64.rpm 修改配置文件 mkdir
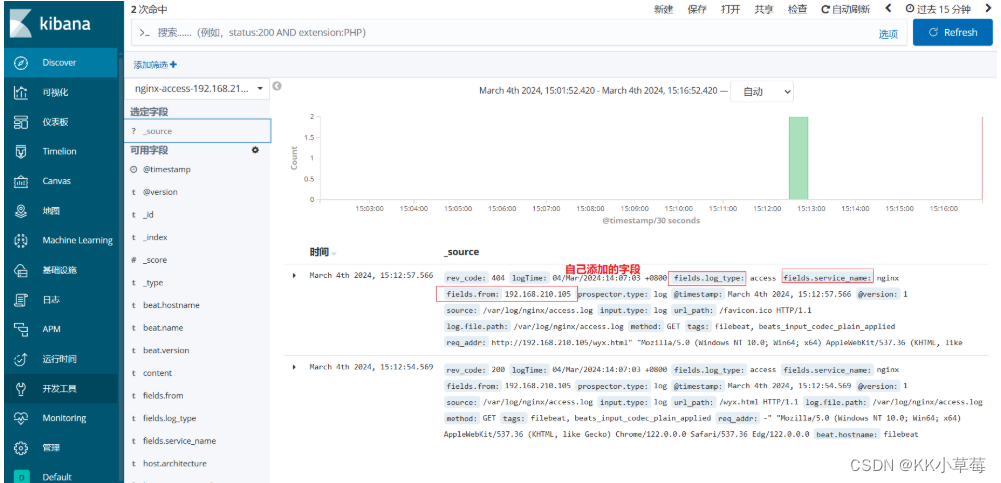
【ELK日志分析系统】ELK+Filebeat分布式日志管理平台部署
ELK+Filebeat部署一、ELK简介1、ELK组件1.1 其他组件 2、为什么要使用 ELK3、完整日志系统基本特征 二、ELK的工作原理三、ELK Elasticsearch 集群部署1、环境准备2、部署 Elasticsearch 软件(node节点)2.1 安装elasticsearch—rpm包2.2 修改elasticsearch主配置文件2.3 es性能调优参数2.3.
ELK+kafka+filebeat企业内部日志分析系统
目录 ELK+kafka+filebeat企业内部日志分析系统 1、组件介绍 1、Elasticsearch: 2、Logstash: 3、Kibana: 4、Kafka: 5、Filebeat: 2、环境介绍 3、版本说明 4、搭建架构 5、实施部署 1、 Elasticsearch集群部署 1、安装配置jdk 2、安装配置ES (1)创建运行ES的普通用户
糟糕的 filebeat
因为公司的服务器和日志所在的kafka集群不是在一个网络下,导致服务器到kafka之间日志传输率受带宽的限制,高峰期一直把带宽跑满,最近花了挺长时间来解决这个问题。 问题 遇到带宽跑满时,大概率就知道是压缩有问题。我们的filebeat采用了snappy压缩算法,这算法压缩率确实感人,单机发往kafka集群的流量在3Mb/s左右。 第一次尝试解决问题 看到snappy压缩这么感人,果断立马
filebeat 数据采集流程
filebeat启动流程 讲解了filebeat的启动流程,filebeat在构建完crawler对象,开始采集流程。 Crawler的start方法内,会启动Inputs func (c *Crawler) Start(pipeline beat.Pipeline,r *registrar.Registrar,configInputs *common.Config,configModul
filebeat 启动流程
因为各种各样的原因,好久没有写博客了,还是希望能够坚持下来 讲解一下filebeat的启动流程吧,核心功能先不描述了0.0 filebeat启动入口在main.go文件内, cmd.RootCmd.Execute()启动filebeat; func main() {if err := cmd.RootCmd.Execute(); err != nil {os.Exit(1)}} 在
【Ubuntu】安装filebeat
在Ubuntu系统上安装filebeat 1. 添加ElasticSearch的GPG密钥 wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - 2. 添加ElasticSearch的APT存储库 echo "deb https://artifacts.elastic.co/p

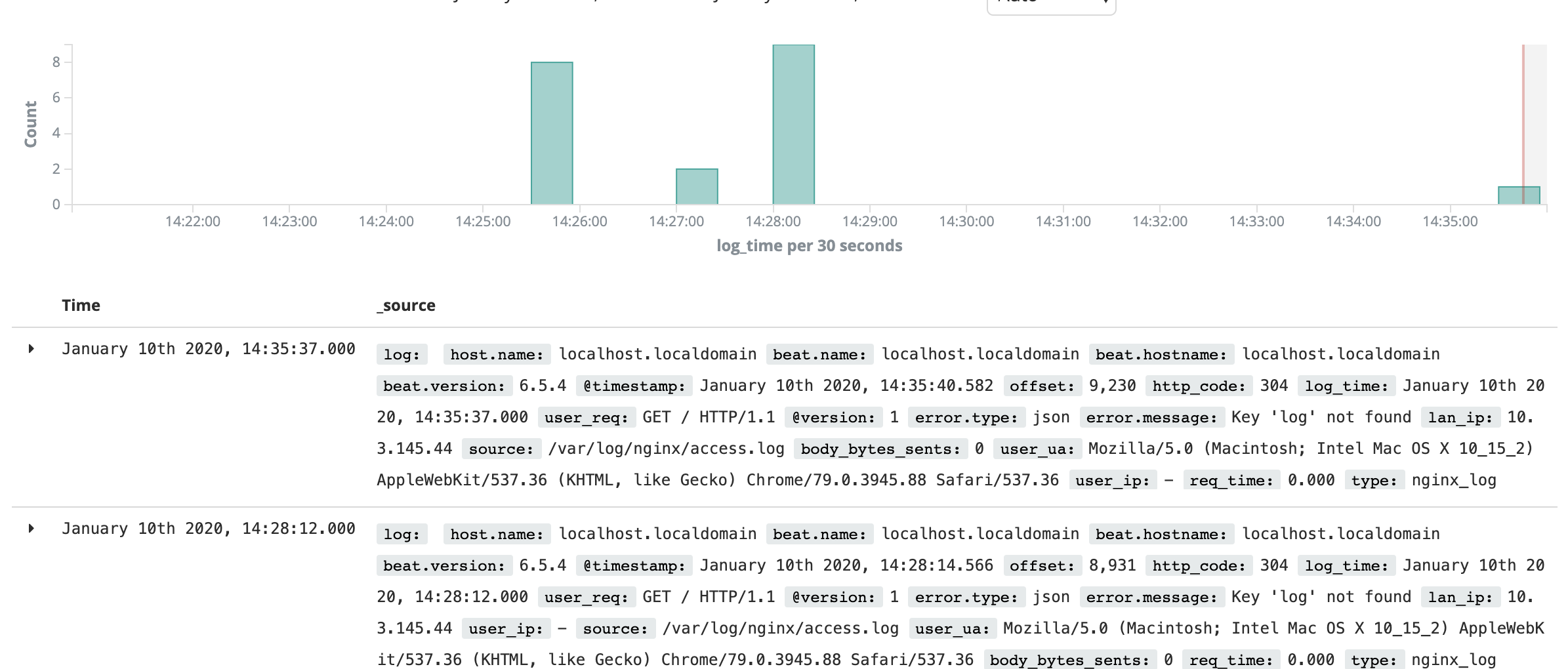
filebeat采集中断与变慢问题分析
4、未采集的那段时间内无以下日志,这段时间内数据源正常,应能被正常采集到。 5、相关进程资源,服务器磁盘、cpu、内存无明显异常。 6、日志中断前有如下报错。 2022-02-15T15:22:22.223+0800 INFO log/harvester.go:254 Harvester started for file: /opt/smbdata/VIBE4/V0403/SPI/K
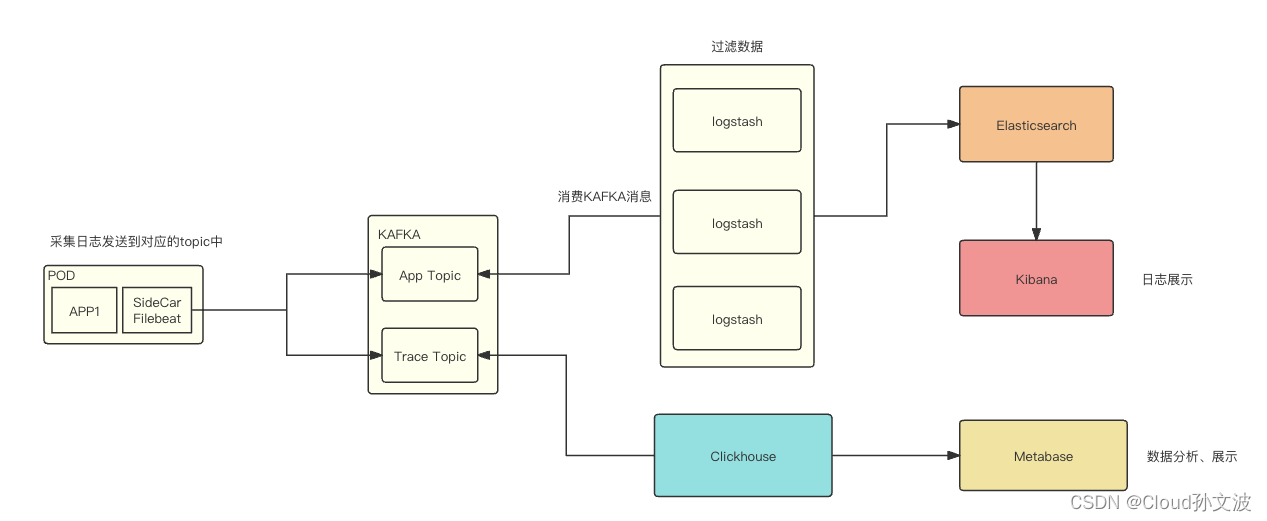
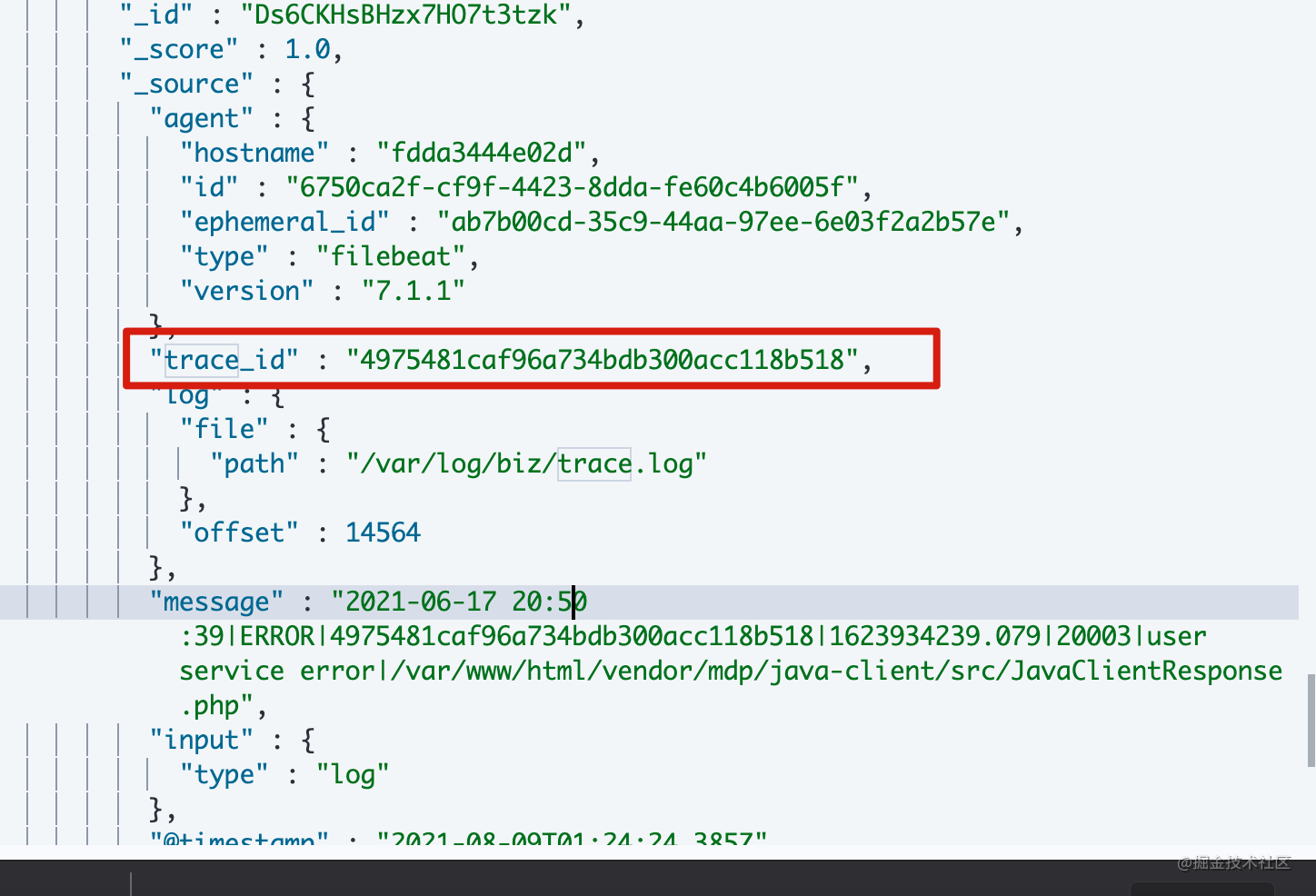
k8s Sidecar filebeat 收集容器中的trace日志和app日志
目录 一、背景 二、设计 三、具体实现 Filebeat配置 K8S SideCar yaml Logstash配置 一、背景 将容器中服务的trace日志和应用日志收集到KAFKA,需要注意的是 trace 日志和app 日志需要存放在同一个KAFKA两个不同的topic中。分别为APP_TOPIC和TRACE_TOPIC 二、设计 流程图如下: