etree专题

Python——xml.etree.ElementTree
Python的xml.etree.ElementTree库详解 xml.etree.ElementTree(简称ElementTree)是Python标准库中用于处理XML文件的模块。它提供了简洁且高效的API,适用于解析、创建和修改XML文档。在需要处理XML数据的场景中,比如配置文件、数据交换格式、Web服务响应等,ElementTree都是非常实用的工具。 一、基本使用场景 解析X

ImportError: DLL load failed while importing etree: 找不到指定的模块。
目录标题 前言错误描述报错代码如下: 原因:解决办法 前言 今天我正在悠闲的逛着网站寻找今天要爬取的目标当我找到目标的时候正要创建我的scrapy爬虫文件的时候竟然报错了我很惊讶😮😮😮!!! 心想不应该啊,于是我就开始了寻找破解之法的道路,终于功夫不负有心人让我找到了。 错误描述 报错代码如下: PS D:\xuexi\python\scrapy> scrapyTr
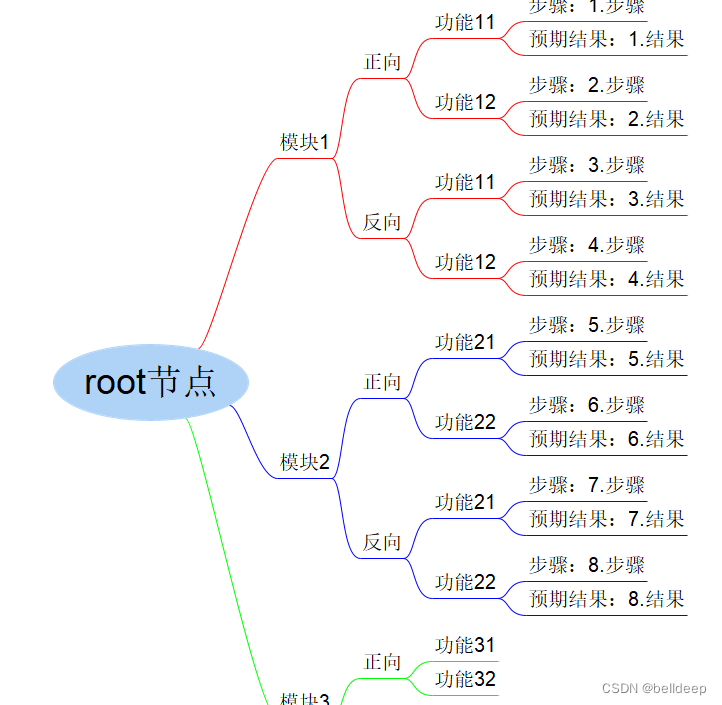
python:读 Freeplane.mm文件,使用 xml.etree 生成测试案例.csv文件
Freeplane 是一款基于 Java 的开源软件,继承 Freemind 的思维导图工具软件,它扩展了知识管理功能,在 Freemind 上增加了一些额外的功能,比如数学公式、节点属性面板等。 强大的节点功能,不仅仅节点的种类很多,而且对于节点的编辑样式也丰富很多,比如数学公式、表格、HTML 的支持等; 思维导图最基本的功能就是新增节点了,和其他商业软件一样,Freeplane 也是通过

python使用etree写回文件出现nso,ns1前缀问题
** 代码 ** import xml.etree.ElementTree as ETimport osclass Deal_Xml:def get_tree_root(self,file_url):"""根据文件路径查询根节点集合:param file_url: 文件路径:return: 返回实例对象本身用于链式操作"""tree = ET.parse(file_url)root = t

python:xml.etree,用 xmltodict 转换为json数据,生成jstree所需的文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad++ 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree pip install xmltodict ; python 用 xml.etree.ElementTree,用 xm
python:xml.etree 生成思维导图 Freemind文件
请参阅:java : pdfbox 读取 PDF文件内书签 或者 python:从PDF中提取目录 请注意:书的目录.txt 编码:UTF-8,推荐用 Notepad++ 转换编码。 xml 是 python 标准库,在 D:\Python39\Lib\xml\etree python 用 xml.etree.ElementTree 生成思维导图 Freemind(.mm)文件 编辑 tx
记一次 python 3.6.4安装Scrapy 从lxml导入etree错误
文章目录 问题将scrapy放到定时任务中执行,不适用scrapyd 问题 对python不熟悉,使用scrapy做了一个爬虫后准备部署到客户服务器,服务器版本是Centos 7,python版本是3.6.4;安装scrapy可以正常安装,但是运行scrapy提示etree导入出错;各种搜索后都不能正常使用(还不知道有virtualenv这种东西);有的说是安装lxml版本3.4

python中lxml.etree 和 ElementTree 的区别
python中lxml.etree 和 ElementTree 的区别还是很明显的。 1.导入方式不同 # etreefrom lxml.etree import Element# ElementTreefrom elementtree.ElementTree import Element# ElementTree in the Python 2.5 standard libraryfr
python xml.etree.ElementTree 模块批量处理xml 标签
在用 xml.etree.ElementTree 模块批量删除xml标签的时候,会出现的问题是,用遍历并不能一次将复合条件的标签删掉。 如下: <?xml version="1.0" encoding="utf-8"?> <resources> <string name="lebian_Download_Error">下载失败,请检查网络</string> <string na
python etree.HTML 以及xpath 解析网页的工具
文章目录 导入模块相关语法实战 导入模块 from lxml import etree 相关语法 XPath(XML Path Language)是一种用于在XML文档中定位和选择元素的语言。XPath的主要应用领域是在XML文档中进行导航和查询,通常用于在XML中选择节点或节点集合。以下是XPath的基本语法和一些常见的表达式: 节点选择: /: 从根节点开始选择/

Python解析xml文件报错:ModuleNotFoundError: No module named ‘xml.etree‘
1.问题描述 在python中 import xml.etree.ElementTree as ET,解析xml文件报错:ModuleNotFoundError: No module named 'xml.etree',如下图所示。 2.原因分析: python在导入模块时将优先搜索当前目录,当前目录中存在名为xml.py的文件或名为xml的包隐藏了同名的标准库包。 3.解决办法 在

Python xml.etree.ElementTree简单解析OFD电子发票(附代码)
OFD文件格式号称中国版的PDF,具有中国自主版权的一种电子文件格式。税局启用电子发票后,电子发票的文件格式也在逐步将PDF格式转成OFD格式,一些新办企业的开票软件领取的开票软件往往是OFD格式的电子发票。在纯电子费用报销的时候我们就需要解析OFD电子发票的信息。 本质上OFD文件是一个xml文件压缩包,我们用解压软件解压OFD电子发票,产生DOC_0的目录和O
python 使用 xml.etree.ElementTree 解析 xml
使用 xml.etree.ElementTree (简称ET) 来解析 xml 非常好用推荐给大家。按照我自己的理解,使用ET 解析xml 就像 遍历 字典一样 ,以如下数据为例 <?xml version="1.0" encoding="utf-8"?><SMP2019-ECISA><Doc ID="4"><Sentence ID="1" label="2">转发了财新网的微博:【内鬼与大