dataframes专题

DataFrames相关介绍文件读取
目录 1.初识DataFrame 2.DataFrame的构造函数 3.数据框的轴 4.CSV文件读取 5.Excel文件读取 1.初识DataFrame (1)昨天,我们学习了Series。而Pandas的另一种数据类型:DataFrame,在许多特性上和Series有相似之处。 (2)顾名思义,这个就是一个数据框,用来存储这个二维数组的相关的信息,通过行和列可以找到

Apache Spark DataFrames入门指南:创建DataFrame(2)
本系列文章翻译自:《scala data analysis cookbook》第二章:Getting Started with Apache Spark DataFrames。原书是基于 Spark 1.4.1编写的,我这里使用的是Spark 1.6.0,丢弃了一些已经标记为遗弃的函数。并且修正了其中的错误。 一、从csv文件创建DataFrame 如何做? 如何工作

Pandas DataFrames筛选数据的方法
在使用dataframe处理数据的时候碰到了按照条件选取行的问题,单个条件时可以使用: df[df['one'] > 5] 如果多个条件的话需要这么写: import numpy as np df[np.logical_and(df['one']> 5,df['two']>5)] 也可以这么写 df[(df['one']> 5) & (df['two']>5)]
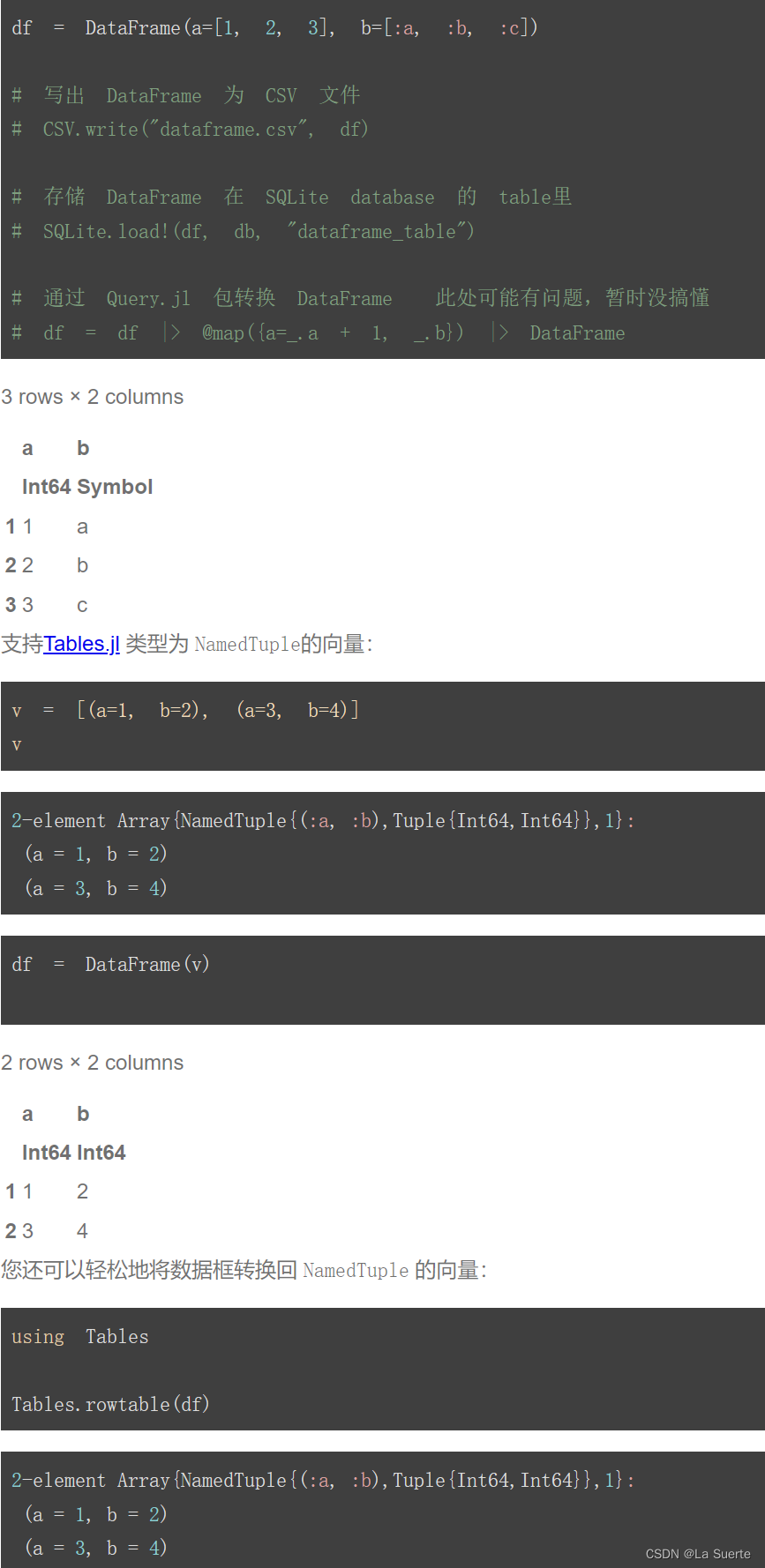
(一)Dataframes安装与类型 #Julia数据分析 #CDA学习打卡
目录 一. Julia简介 二. Dataframe构造方法 1)访问列的方式 (a)判断严格相等 i. 切片严格相等是true ii. 复制严格相等是false (b)判断相等 i. 切片相等是true ii. 复制相等是true 2)获取列名称 (a)使用names函数获取列名 (b)通过第二个参数过滤条件来选择列名 (c)使用propertynames函数将列名

Spark SQL(二) DataFrames相关的Transformation操作
Spark SQL(二) DataFrames相关的Transformation操作 DataFrames是不可变的,且与其相关的Transformation操作和RDD的相关操作一样都是返回一个新的DataFrame. DataFrames Transformations selectselectExprfilter/wheredistinct/dropDuplicatessort/ord
Spark SQL(一) 如何创建DataFrames
Spark SQL(一) 如何创建DataFrames Spark SQL包含两个主要的部分,第一部分是DataFrames和Datasets, 第二部分是Catalyst optimizer. DataFrames和Datasets是结构性API的展示,定义了操作结构化数据的高层次API, 而Catalyst optimizer则是在背后对处理数据的逻辑进行优化,以加速处理数据的速度。 结构

DataFrames入门指南:创建和操作DataFrame
2019独角兽企业重金招聘Python工程师标准>>> 一、从csv文件创建DataFrame 本文将介绍如何从csv文件创建DataFrame。 如何做? 从csv文件创建DataFrame主要包括以下几步骤: 1、在build.sbt文件里面添加spark-csv支持库; 2、创建SparkConf对象,其中包括Spark运行所有的环境信息; 3、创建Spark
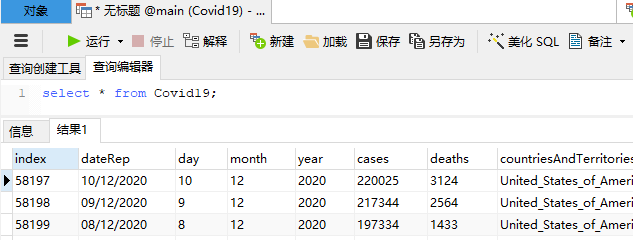
使用SQLAlchemy将Pandas DataFrames导出到SQLite
一、概述 在进行探索性数据分析时 (例如,在使用pandas检查COVID-19数据时),通常会将CSV,XML或JSON等文件加载到 pandas DataFrame中。然后,您可能需要对DataFrame中的数据进行一些处理,并希望将其存储在关系数据库等更持久的位置。 本教程介绍了如何从CSV文件加载pandas DataFrame,如何从完整数据集中提取一些数据,然后使用SQLAlchem