一、概述
在进行探索性数据分析时 (例如,在使用pandas检查COVID-19数据时),通常会将CSV,XML或JSON等文件加载到 pandas DataFrame中。然后,您可能需要对DataFrame中的数据进行一些处理,并希望将其存储在关系数据库等更持久的位置。
本教程介绍了如何从CSV文件加载pandas DataFrame,如何从完整数据集中提取一些数据,然后使用SQLAlchemy将数据子集保存到SQLite数据库 。
二、配置开发环境
确保已安装Python 3。截至目前, Python 3.8.2是Python的最新版本。
在本教程中,我们还将使用:
- pandas(项目主页 和源代码),本教程中的版本1.1.5
- SQLAlchemy (项目主页和 源代码),本教程的1.3.20
- SQLite(项目首页 和源代码),Python 包含一个连接器,作为Python标准库的一部分
使用以下命令将上述代码库安装到新的 Python虚拟环境中:
pip3 install pandas sqlalchemy
现在,我们的开发环境已准备好下载示例COVID-19数据集,将其加载到pandas DataFrame中,对其进行一些分析,然后保存到SQLite数据库中。
三、获取COVID-19数据
在您的网络浏览器中, 下载关于当今全球COVID-19病例地理分布页面的数据下载。它看起来应类似于以下屏幕截图。
应该有一个以CSV格式下载数据的链接,但是该组织在过去几周内多次更改了页面布局,这使得很难找到Excel(XLSX)以外的格式。如果您在获取CSV版本时遇到问题,只需从GitHub下载此版本即可,该版本 与2020年12月10日下载的副本挂钩。
四、将CSV导入pandas
原始数据位于CSV文件中,我们需要通过pandas DataFrame将其加载到内存中。
REPL准备执行代码,但是我们首先需要导入pandas库,以便可以使用它。
from pandas import read_csvdf = read_csv("data.csv", encoding="ISO-8859-1")
现在将数据加载到df作为pandas DataFrame 类实例的变量中 。
count在此DataFrame上运行该函数时,我们会发现它具有61048行。
from pandas import read_csvdf = read_csv("data.csv", encoding="ISO-8859-1")
print(df.count())
执行输出:
dateRep 61048
day 61048
month 61048
year 61048
cases 61048
deaths 61048
countriesAndTerritories 61048
geoId 60777
countryterritoryCode 60929
popData2019 60929
continentExp 61048
Cumulative_number_for_14_days_of_COVID-19_cases_per_100000 58173
dtype: int64
接下来,我们将采用这组61048行数据,并仅切出与美国有关的行。
从原始数据帧创建新的数据帧
我们可以使用pandas函数将单个国家/地区的所有数据行匹配countriesAndTerritories到与所选国家/地区匹配的列。
from pandas import read_csvdf = read_csv("data.csv", encoding="ISO-8859-1")
# print(df.count())save_df = df[df['countriesAndTerritories']=="United_States_of_America"]
print(save_df)
该save_df变量包含数据的较小的子集。您可以通过自己打印来找出其中的内容:
您应该看到类似以下输出的内容:
dateRep ... Cumulative_number_for_14_days_of_COVID-19_cases_per_100000
58197 10/12/2020 ... 794.356027
58198 09/12/2020 ... 784.195114
58199 08/12/2020 ... 769.896719
58200 07/12/2020 ... 762.794473
58201 06/12/2020 ... 757.944062
... ... ... ...
58538 04/01/2020 ... NaN
58539 03/01/2020 ... NaN
58540 02/01/2020 ... NaN
58541 01/01/2020 ... NaN
58542 31/12/2019 ... NaN [346 rows x 12 columns]
原始61048行中有346行数据。让我们继续将此子集保存到SQLite关系数据库中。
将DataFrame保存到SQLite
我们将使用SQLAlchemy创建与新SQLite数据库的连接,在此示例中,该数据库将存储在名为的文件中save_pandas.db。当然,您可以使用所需的任何名称在任何位置保存文件,而不仅是在执行Python REPL的目录中保存。
首先create_engine从sqlalchemy 库中导入函数。
使用导入的create_engine函数创建连接,然后connect在其上调用方法。
from pandas import read_csvdf = read_csv("data.csv", encoding="ISO-8859-1")
# print(df.count())save_df = df[df['countriesAndTerritories']=="United_States_of_America"]
# print(save_df)from sqlalchemy import create_engine
engine = create_engine('sqlite:///save_pandas.db', echo=True)
sqlite_connection = engine.connect()
我们设置echo=True为查看来自数据库连接的所有输出。连接成功后,您将看到类似于以下的输出:
2020-12-11 16:30:21,542 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2020-12-11 16:30:21,543 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:30:21,544 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2020-12-11 16:30:21,545 INFO sqlalchemy.engine.base.Engine ()
使用您要创建的表名的字符串设置变量名。然后to_sql 在save_df对象上调用该方法时使用该变量,这是我们的pandas DataFrame,它是原始数据集的子集,从原始7320中筛选出89行。
请注意,在这种情况下,如果表已经存在于数据库中,我们将失败。您可以在该程序的更强大的版本中更改if_exists为replace 或append添加自己的异常处理。查看 pandas.DataFrame.to_sql 文档,以获取有关您的选项的详细信息。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
from pandas import read_csvdf = read_csv("data.csv", encoding="ISO-8859-1")
# print(df.count())save_df = df[df['countriesAndTerritories']=="United_States_of_America"]
# print(save_df)from sqlalchemy import create_engine
engine = create_engine('sqlite:///save_pandas.db', echo=True)
sqlite_connection = engine.connect()sqlite_table = "Covid19"
save_df.to_sql(sqlite_table, sqlite_connection, if_exists='fail')
sqlite_connection.close()
执行输出:
2020-12-11 16:31:11,484 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2020-12-11 16:31:11,484 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,485 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2020-12-11 16:31:11,485 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,489 INFO sqlalchemy.engine.base.Engine PRAGMA main.table_info("Covid19")
2020-12-11 16:31:11,489 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,490 INFO sqlalchemy.engine.base.Engine PRAGMA temp.table_info("Covid19")
2020-12-11 16:31:11,490 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,492 INFO sqlalchemy.engine.base.Engine
CREATE TABLE "Covid19" ("index" BIGINT, "dateRep" TEXT, day BIGINT, month BIGINT, year BIGINT, cases BIGINT, deaths BIGINT, "countriesAndTerritories" TEXT, "geoId" TEXT, "countryterritoryCode" TEXT, "popData2019" FLOAT, "continentExp" TEXT, "Cumulative_number_for_14_days_of_COVID-19_cases_per_100000" FLOAT
)2020-12-11 16:31:11,492 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,506 INFO sqlalchemy.engine.base.Engine COMMIT
2020-12-11 16:31:11,507 INFO sqlalchemy.engine.base.Engine CREATE INDEX "ix_Covid19_index" ON "Covid19" ("index")
2020-12-11 16:31:11,507 INFO sqlalchemy.engine.base.Engine ()
2020-12-11 16:31:11,516 INFO sqlalchemy.engine.base.Engine COMMIT
2020-12-11 16:31:11,519 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2020-12-11 16:31:11,524 INFO sqlalchemy.engine.base.Engine INSERT INTO "Covid19" ("index", "dateRep", day, month, year, cases, deaths, "countriesAndTerritories", "geoId", "countryterritoryCode", "popData2019", "continentExp", "Cumulative_number_for_14_days_of_COVID-19_cases_per_100000") VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
2020-12-11 16:31:11,525 INFO sqlalchemy.engine.base.Engine ((58197, '10/12/2020', 10, 12, 2020, 220025, 3124, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 794.35602672), (58198, '09/12/2020', 9, 12, 2020, 217344, 2564, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 784.1951137), (58199, '08/12/2020', 8, 12, 2020, 197334, 1433, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 769.89671919), (58200, '07/12/2020', 7, 12, 2020, 173432, 1111, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 762.79447316), (58201, '06/12/2020', 6, 12, 2020, 211933, 2203, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 757.94406245), (58202, '05/12/2020', 5, 12, 2020, 231930, 2680, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 746.87056354), (58203, '04/12/2020', 4, 12, 2020, 214747, 2481, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 735.98730065), (58204, '03/12/2020', 3, 12, 2020, 203311, 3190, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', 727.86519506) ... displaying 10 of 346 total bound parameter sets ... (58541, '01/01/2020', 1, 1, 2020, 0, 0, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', None), (58542, '31/12/2019', 31, 12, 2019, 0, 0, 'United_States_of_America', 'US', 'USA', 329064917.0, 'America', None))
2020-12-11 16:31:11,527 INFO sqlalchemy.engine.base.Engine COMMIT
2020-12-11 16:31:11,535 INFO sqlalchemy.engine.base.Engine SELECT name FROM sqlite_master WHERE type='table' ORDER BY name
2020-12-11 16:31:11,535 INFO sqlalchemy.engine.base.Engine ()
我们可以通过sqlite3命令行查看器查看数据,以确保将其正确保存到SQLite文件中。
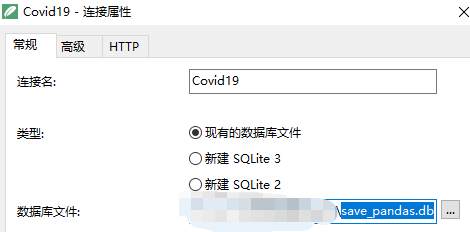
通过Navicat软件,打开save_pandas.db文件名的命令来访问数据库。然后,使用标准的SQL查询从Covid19表中获取所有记录。
打开表Covid19,执行sql语句
select * from Covid19;
效果如下:
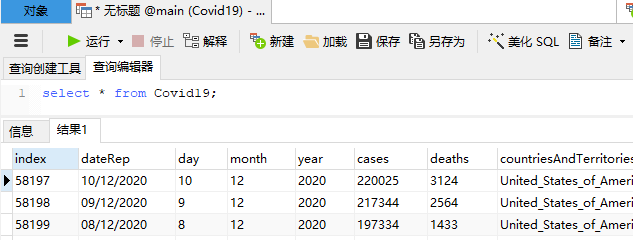
countriesAndTerritories列匹配的 所有数据United_States_of_America都在那里!我们已成功将数据从DataFrame导出到SQLite数据库文件中。
下一步是什么?
我们只是将数据从CSV导入到pandas DataFrame中,选择了该数据的一个子集,然后将其保存到关系数据库中。
您应该看一下“ 通过研究COVID-19数据学习熊猫” 教程,以了解有关如何从较大的DataFrame中选择数据子集的更多信息,或者访问pandas页面,以获取Python社区其他成员提供的更多教程。
您还可以通过阅读Full Stack Python目录表来了解Python项目中下一步的代码 。
本文参考链接:
https://www.fullstackpython.com/blog/export-pandas-dataframes-sqlite-sqlalchemy.html





