crawl专题

记录一次Crawl遇到的301重定向问题
在浏览器中打开网页正常运行,模拟浏览器运行就会返回301永久重定向,这是网站设置的一种反PA机制,那么我们在requests.get()中设置allow_redirects=False,将允许重定向设置为FALSE, res = requests.get(url=s, headers=self.headers2, allow_redirects=False, timeout=50).header

【Python/crawl】如何使用Python爬虫将一系列网页上的同类图片下载到本地
【需求】 从网页https://www.zhainq.com/%e7%be%8e%e5%a5%b3%e5%86%99%e7%9c%9f%e6%9c%ba%e6%9e%84/%e6%97%a5%e6%9c%ac%e7%be%8e%e5%a5%b3%e5%86%99%e7%9c%9f/109012.html 开始,有十七页,每页都有大漂亮“小濑田麻由”的若干图片,想要将其下载到本地。 如果手工一

scrapy : Unknown command: crawl
这个问题挺简单啊 看看上面两张图的区别, 一下只就懂了吧 只要在terminal中加个 cd ‘文件位置’ 就好了吧 这样子的目的是确定你文件的位置,pycharm才会去执行 不然是找不到对象的 has no attitude ‘one’ 我的爬虫文件名是one,每个人不同啊,别照抄!!!
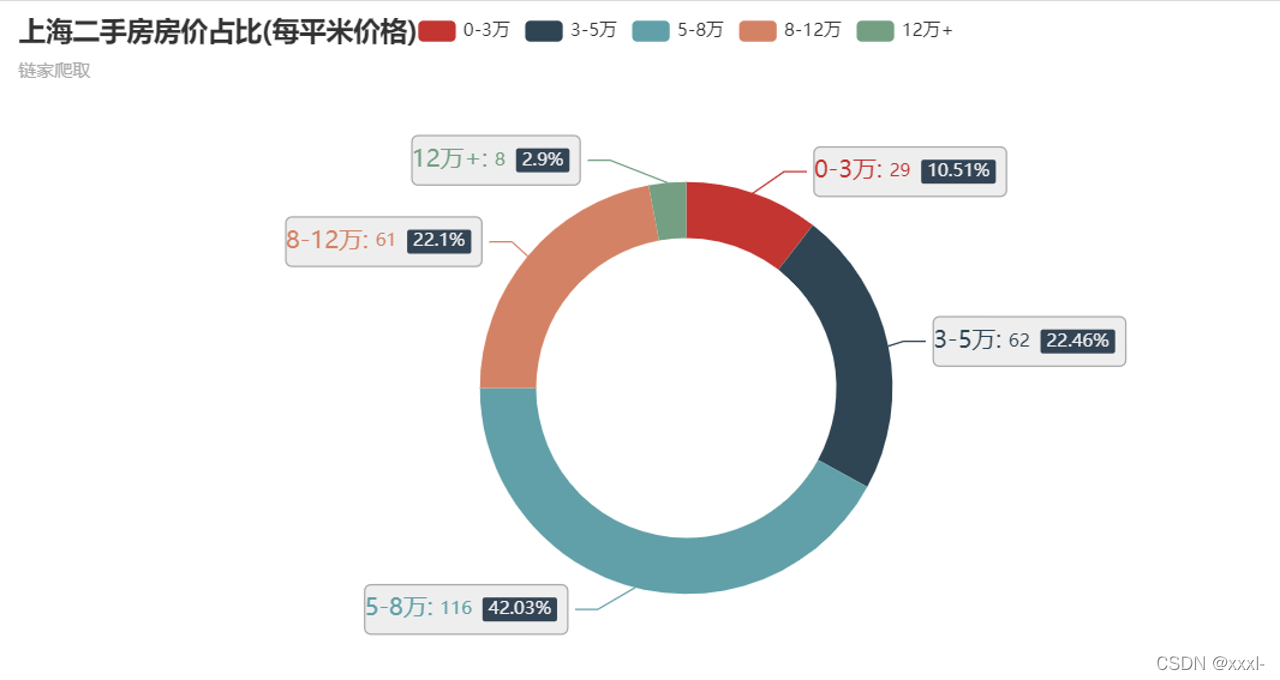
二手房网站信息数据分析、数据可视化-基于python的crawl,jupyter notebook进行数据清洗和可视化。
爬取数据 使用的是beautifulsoup和request库,最终将数据存入excel即csv格式 首先导入库: import requestsfrom bs4 import BeautifulSoupimport csv 创建一个方法-根据网页链接和headers获取网页的内容: def crawl_data(crawl_url):headers = {'User-Agent':