convnet专题

2015深度学习回顾:ConvNet、Caffe、Torch及其他
CVPR可谓计算机视觉领域的奥运会,这是vision.ai的Co-Founder,前MIT研究人员T. Malisiewicz针对CVPR'15尤其是Deep Learning的综述文章,谈到了ConvNet的Baseline,Caffe和Torch之间的分歧,ArXiv论文热,以及百度的ImageNet违规事件等。原文标题为:Deep down the rabbit hole: CVPR 20
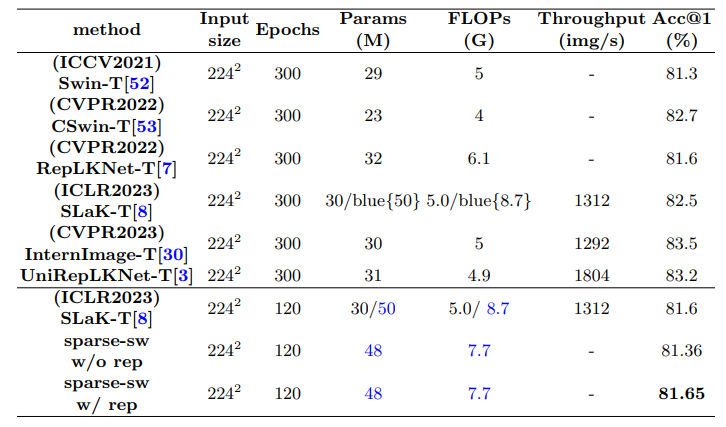
新一代大核卷积反超ViT和ConvNet!同参数量下性能、精度、速度完胜
大核卷积网络是CNN的一种变体,也是深度学习领域的一种重要技术,它使用较大的卷积核来处理图像数据,以提高模型对视觉信息的理解和处理能力。 这种类型的网络能够捕捉到更多的空间信息,因为它的大步长和大感受野可以一次性覆盖图像的更多区域。比如美团提出的PeLK网络,内核大小可以达到101x101,同参数量下性能反超 ViT,目前已被CVPR 2024收录。 更值得一提的,大核卷积网络不仅在性能上有所

MutualNet:通过从网络宽度和分辨率互学习的自适应ConvNet
MutualNet: Adaptive ConvNet via Mutual Learning from Network Width and Resolution 文章目录 摘要1. 引言2. 相关工作3. 方法3.1 预备知识3.2 重新思考高效的网络设计3.3 互学习框架 4. 实验4.1 ImageNet分类评估 摘要 我们提出了宽度-分辨率互学习的方法(Mut

DeepLearning in Pytorch|手写数字识别器_minst_convnet
目录 概要 一、代码概览 二、使用步骤 1.引入库 2.超参数的定义和数据集的预处理 3.构建网络 4.训练 5.测试 三、剖析 1.各层运算 2.健壮性实验 总结 概要 系列文章为《深度学习原理与Pytorch实践》学习笔记 Pytorch 2.2.1 (CPU) Python 3.6.13|Anaconda 环境 一、代码概览 手写数字识别器_minst_convne

阅读文献:LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference 1.四个问题 要解决什么问题 在高速状态下,平衡图像分类方法的精度和效率 用什么方法解决 提出一种网络模型LeViT方法,在ViT模型基础上,引入卷积模块而不是学习类卷积特征的转换器组件,用特征金字塔替换Transformer中用以的结构(类似LeNet架

图像语意分割训练Cityscapes数据集SegNet-ConvNet神经网络详解
前言:经过几个月的学习研究,在神经网络中训练多分类语意分割模型识别城市街景信息,终于在最近得到了理想中的实验结果。在我陷入对细节参数调整不当及诸多问题时,苦于没有一篇能够“面向新手编程”的博客。因而我在能够在解决一系列问题到达终点后总结这一路踩过的坑,希望对后来者有所帮助。 接下来就是用我训练完成的神经网络模型结合我所学专业(风景园林)研究领域问题完成论文撰写,希望能够投稿核心期刊成功。^ _^
UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大内核ConvNet
摘要 https://arxiv.org/abs/2311.15599 大核卷积神经网络(ConvNets)最近受到了广泛的研究关注,但存在两个未解决的关键问题需要进一步研究。(1)现有大核ConvNets的架构在很大程度上遵循传统ConvNets或Transformers的设计原则,而大核ConvNets的架构设计仍未得到充分解决。(2)随着Transformer 在多种模式下的主导地位,尚待
cuda-convnet 的运行环境设置
这段时间学习deep learning,下载了cuda-convnet 学习CNN。想要运行这个代码,需要GPU的机器,同时需要安装cuda以及python等。从裸机到运行成功,花费了一些时间。因第一次安装,没有头绪,未将出错情况一一记下。这次先写下基本流程记以及问题的解决方法链接,具体细节等下次安装时,再逐步整理。 硬件: (1) cpu:
![[ConvNet]卷积神经网络概念解析](https://img-blog.csdnimg.cn/be88cb9e3eaf489a97be41c05877bba3.png)
[ConvNet]卷积神经网络概念解析
在初步接触了深度学习以后,我们把目光投向对于一些图像的识别。 其实在d2l这本书中,我们接触过用深度神经网络去识别一个图像,并且对其进行一个分类操作,核心原理是将图像展开成一维tensor,然后作为特征进行检测。 其实理论是这个思路和方式都没有问题,怀就坏在这个图片的大小可能是不固定的,如果是288×288×3的图片,展开成张量然后拿去训练,那么特征值的数目就会很恐怖,对构建神经网络产生了一个