coalesce专题

MySQL中COALESCE函数示例详解
《MySQL中COALESCE函数示例详解》COALESCE是一个功能强大且常用的SQL函数,主要用来处理NULL值和实现灵活的值选择策略,能够使查询逻辑更清晰、简洁,:本文主要介绍MySQL中C... 目录语法示例1. 替换 NULL 值2. 用于字段默认值3. 多列优先级4. 结合聚合函数注意事项总结C
MySQL中的COALESCE()函数用法,返回第一个非 NULL 的参数
COALESCE() 是 MySQL 中的一个非常有用的函数,它返回第一个非 NULL 的参数。这个函数可以接受多个参数,并从左到右检查每个参数,返回第一个非 NULL 的值。如果所有提供的参数都是 NULL,则 COALESCE() 返回 NULL。 COALESCE() 函数的基本语法 COALESCE(val1, val2, val3, ..., valN) 这里,val1,
MySQL中的COALESCE()函数用法
MySQL中的COALESCE()函数用于返回参数列表中的第一个非null值。 其语法如下: COALESCE(value1, value2, ..., valueN) 其中,value1、value2、…、valueN为数值或表达式。如果value1的值不为null,该值就会被返回;否则,继续比较value2的值,如果value2的值不为null,就返回value2的值,以此类推,直到找

spark 大型项目实战(三十九): 算子调优之filter过后使用coalesce减少分区数量
下面给出一种filter 的情况 默认情况下,经过了这种filter之后,RDD中的每个partition的数据量,可能都不太一样了。(原本每个partition的数据量可能是差不多的) 问题: 1、每个partition数据量变少了,但是在后面进行处理的时候,还是要跟partition数量一样数量的task,来进行处理;有点浪费task计算资源。 2、每个partition的数据量不

Oracle COALESCE函数 ISNULL 函数
COALESCE 是sql标准,语法 COALESCE ( expression [ ,...n ] )返回表达式中第一个非空表达式,如有以下语句: SELECT COALESCE(NULL,NULL,3,4,5) FROM dual其返回结果为:3 出处:http://zhidao.baidu.com/question/465040687.html?qbl=relate_question_0
DB2里面的coalesce函数
coalesce:返回其参数中第一个非空表达式 语法:coalesce(expression1,expression2,……,expression[n]) 所有表达式必须类型相同,或者可以隐式转换为相同类型; 返回类型 将相同的值作为 expression 返回。 注释 如果所有自变量均为 NULL,则 COALESCE 返回 NULL 值。 COALES

SQL中的COALESCE,NVL,Decode的作用
1.COALESCE COALESCE 是 SQL 中的一个函数,用于返回参数列表中第一个非 NULL 的表达式的值。具体来说,COALESCE 函数接受一个参数列表,如果参数列表中的第一个参数不为 NULL,则返回该参数的值;如果第一个参数为 NULL,则继续检查下一个参数,直到找到第一个非 NULL 的参数,然后返回该参数的值。如果参数列表中所有参数均为 NULL,则返回 NULL。 使用
spark partition 理解 / coalesce 与 repartition的区别
一.spark 分区 partition的理解: spark中是以vcore级别调度task的。 如果读取的是hdfs,那么有多少个block,就有多少个partition举例来说:sparksql 要读表T, 如果表T有1w个小文件,那么就有1w个partition这时候读取效率会较低。假设设置资源为 --executor-memory 2g --executor-cores 2 --n
转 COALESCE 函数 和CASE语句
[color=brown]COALESCE 函数 功能 返回列表中的第一个非空表达式。 语法 COALESCE ( expression, expression [ , ...] ) 参数 expression 任意表达式。 标准和兼容性 SQL/92 SQL/92。 SQL/99 核心特性。 示例 下面的语句返回值 34。 SELECT COALESCE( NUL
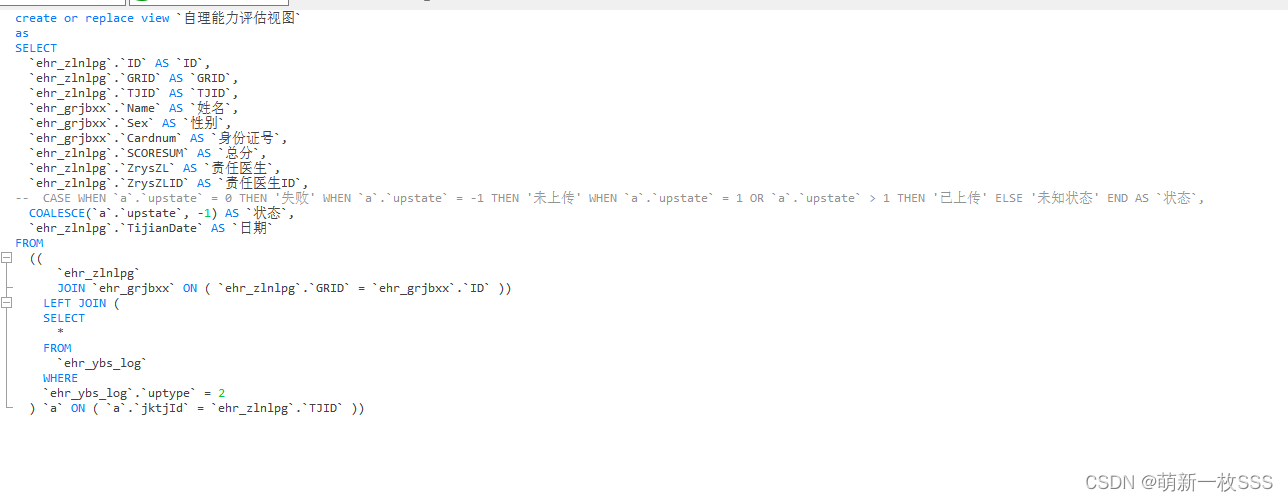
mysql中 COALESCE和CASE WHEN的使用以及创建或替换视图
create or replace view `自理能力评估视图` as SELECT `ehr_zlnlpg`.`ID` AS `ID`, `ehr_zlnlpg`.`GRID` AS `GRID`, `ehr_zlnlpg`.`TJID` AS `TJID`, `ehr_grjbxx`.`Name` AS `姓名`, `ehr_grjbxx`.`Sex
sql中COALESCE函数详解
在SQL中,COALESCE函数是一个非常有用的函数,用于从其参数列表中返回第一个非NULL值。如果所有给定的参数都是NULL,那么COALESCE函数将返回NULL。这个函数可以接受多个参数,使其在处理可能出现的NULL值时非常灵活和强大。 语法 COALESCE(expression1, expression2, ..., expressionN) expression1, expre
MySQL语句 |条件语句 IFNULL 和 COALESCE 的区别
在MySQL中,IFNULL和COALESCE都是用来处理NULL值的函数,但它们之间存在一些重要的差异。 函数定义 IFNULL(expr1, expr2): 如果expr1为NULL,则返回expr2,否则返回expr1。COALESCE(value1, value2, ..., valueN): 返回参数列表中的第一个非NULL值。 参数数量 IFNULL接受两个参数。COALESC
PostgreSQL函数coalesce
COALESCE函数是返回参数中的第一个非null的值,它要求参数中至少有一个是非null的,如果参数都是null会报错。 select COALESCE(null,null); -- 结果得到''select COALESCE(null,null,'a',''); -- 结果得到aselect COALESCE(null,null,'','a'); -- 结果得到''sel
R语言 coalesce 函数
两个主要功能, 替换NA x <- c(2, 1, NA, 5, 3, NA) # Create example vectorcoalesce(x, 999) # Apply coalesce function# 2 1 999 5 3 999 x中的NA被替换成了999。 对比并替换 这个功能更有用。 y <- c(1,

70.Spark大型电商项目-用户访问session分析-算子调优之filter过后使用coalesce减少分区数量
目录 filter过后使用coalesce减少分区数量 问题 针对上述的两个问题,我们希望应该能够怎么样? 本篇文章记录用户访问session分析-算子调优之filter过后使用coalesce减少分区数量。 filter过后使用coalesce减少分区数量 默认情况下,经过了这种filter之后,RDD中的每个partition的数据量,可能都不太一样了。(原本每个pa

SQL SERVER 多字段不为空COALESCE用法
有时候我们需要对多个字段进行非空判断,显示几个字段中不为空(最前边)的那个,字段少的时候,我们可以使用CASE WHEN做判断,但是多的时候写起来就比较麻烦了,这时候我们可以用COALESCE,测试数据: --测试数据 if not object_id(N'Tempdb..#T1') is null drop table #T1 Go Create table #T
SQL(COALESCE)
zstarling 非空值查找及替换COALESCE 非空值查找及替换COALESCE 新语法SQL COALESCE(staff_no,staff_no1,) 详解 在SQL中,COALESCE函数用于返回一组表达式中的第一个非NULL值。它接受两个或多个参数,并按参数顺序依次判断每个参数是否为NULL,返回第一个非NULL值。 该接受任意数量的参数,并返回第一个非空参
mysql left join 空值改默认值 coalesce
select A.*,coalesce(B.bEnable,0) as bEnable from data_dictionary A left join role_auth B on A.sCode=B.sAuthCode and B.sRoleCode=‘001’ where A.iType=1
Flinksql bug :Illegal mixing of types in CASE or COALESCE statement
报错信息 org.apache.flink.table.api.ValidationException: SQL validation failed. From line 66, column 23 to line 68, column 46: Illegal mixing of types in CASE or COALESCE statement org.apache.calcite.run
浪尖说spark的coalesce的利弊及原理
浪尖的粉丝应该很久没见浪尖发过spark源码解读的文章,今天浪尖在这里给大家分享一篇文章,帮助大家进一步理解rdd如何在spark中被计算的,同时解释一下coalesce降低分区的原理及使用问题。 主要是知识星球有人问到过coalesce方法的使用和原理的问题,并且参考阅读了网上关于coalesce方法的错误介绍,有了错误的理解,所以浪尖忙里偷闲给大家解释一下。 浪尖这里建议多看看spark源码