checkpoints专题

loras和checkpoints的概念和应用
Loras(Low-Rank Adaptation)是一种模型压缩和参数高效利用的技术。它的核心思想是,对于预训练好的大型模型,并不是所有的参数都对最终的性能贡献很大。Loras通过对模型的部分参数进行低秩分解,将其表示为两个低维矩阵的乘积,从而大幅减少了参数的数量。这样既能保持模型的性能,又显著降低了模型的存储和计算开销。 Loras广泛应用于迁移学习和模型压缩场景。在迁移学习中,Loras可
AutoDL中Notebook中无法打开“checkpoints”文件夹
checkpoints是Notebook的关键字,若用户创建文件夹命名为checkpoints,则在JupyterLab上无法打开、重命名和删除。此时可以在Terminal里使用命令行打开checkpoints,或者新建文件夹将checkpoints里的数据移动到新的文件夹下。 操作步骤: 打开Terminal,用命令行进行操作。 方法一:执行cd checkpoints命令打开checkp

21、Flink 的 Checkpoints 使用介绍
Checkpoints 1.概述 Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。 2.Checkpoint 存储 Flink 开箱即用地提供了两种 Checkpoint 存储类型: JobManagerCheckpointStorageFileSystemCheckpointStorage
![IsADirectoryError: [Errno 21] Is a directory: ‘preds/STERE/RGBD_VST/.ipynb_checkpoints‘](https://img-blog.csdnimg.cn/ab50b9bf37db48b189ddccec553dd612.png)
IsADirectoryError: [Errno 21] Is a directory: ‘preds/STERE/RGBD_VST/.ipynb_checkpoints‘
报错: IsADirectoryError: [Errno 21] Is a directory: ‘preds/STERE/RGBD_VST/.ipynb_checkpoints’ 我在评估训练模型的时候显示上面的错误,后面通过网上查资料,发现这个错误是由于我创建了和已有文件夹同名的文件名,所以导致报错,建议使用不同的文件名来创建文件。可以排查一下上一级目录或者上上级目录是不是有重名
Difference Between [Checkpoints ] and [state_dict]
在PyTorch中,checkpoints 和状态字典(state_dict)都是用于保存和加载模型参数的机制,但它们有略微不同的目的。 1. 状态字典 (state_dict): 状态字典是PyTorch提供的一个Python字典对象,将每个层的参数(权重和偏置)映射到其相应的PyTorch张量。它表示模型参数的当前状态。通过使用state_dict()方法,可以获取PyTorch模型的

flink generic log-based incremental checkpoints 设计
背景 flink 在1.15版本后开始提供generic log-based incremental checkpoints的检查点方案,目的在于减少checkpoint的耗时,尽量缩短端到端的数据处理延迟,本文就来看下这种新类型的checkpoint的设计 generic log-based incremental checkpoints 设计 generic log-based incr
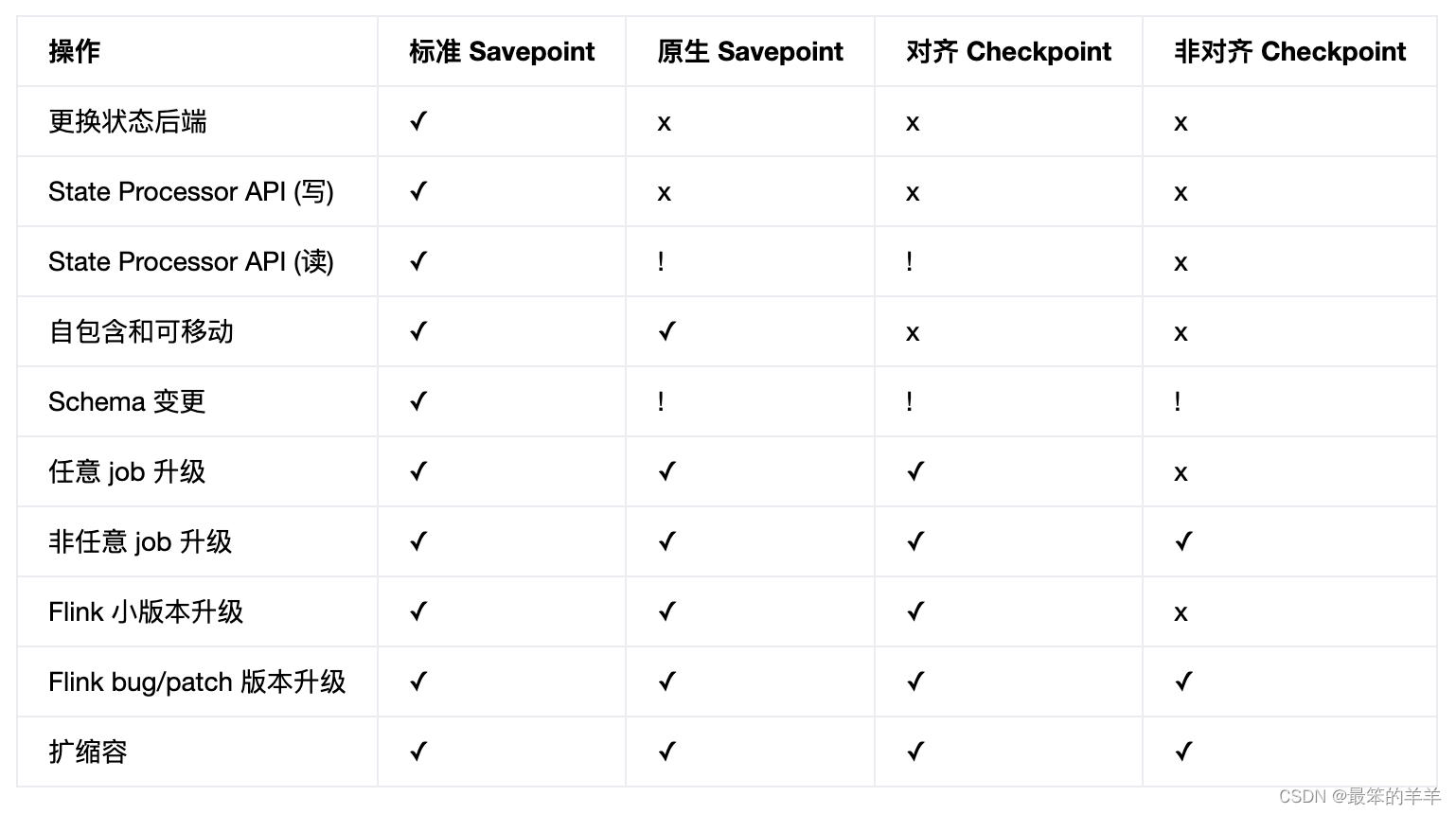
Flink系列之:Checkpoints 与 Savepoints
Flink系列之:Checkpoints 与 Savepoints 一、概述二、功能和限制 一、概述 从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。 Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 Checkpoint 的生命周期 由 Flink 管理, 即 Flin

Flink系列之:Checkpoints
Flink系列之:Checkpoints 一、概述二、保留Checkpoint三、目录结构四、通过配置文件全局配置五、创建 state backend 对单个作业进行配置六、从保留的checkpoint 中恢复状态 一、概述 Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。 二、保留
Flink系列之:Checkpoints 与 Savepoints
Flink系列之:Checkpoints 与 Savepoints 一、概述二、功能和限制 一、概述 从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。 Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 Checkpoint 的生命周期 由 Flink 管理, 即 Flin

paddleocr学习笔记(五)将训练模型(checkpoints模型)转化为推理模型(inference模型)
这个主要参考PaddleOCR下的 /doc/doc_ch/inference.md 先按照这里的教程学习模型转化: 一、训练模型转inference模型 检测模型转inference模型 下载超轻量级中文检测模型: wget -P ./ch_lite/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.