cassandra专题

Cassandra 分页 读取数据
文章目录 为什么要分页方案选择TokenJPAPagingState 参考 为什么要分页 如果一个查询得到的记录数太大,一次性返回回来,那么效率非常低,并且很有可能造成内存溢出,使得整个应用都奔溃。所以,在数据量比较大的时候,分页还是非常有必要的。 方案选择 Token Cassandra 提供了Token 函数 来记录上次查询的最后一条数据,但是它需要多个primar

学习分享-分布式 NoSQL 数据库管理系统Cassandra以及它和redis的区别
前言 最近在学习的过程中遇到如何应对海量幂等 Key 所消耗的内存的问题,在网上查找资料了解到Cassandra或许是解决方式之一,所以查找了Cassandra的相关资料及其Cassandra和redis的区别。 什么是Cassandra Cassandra 是一个开源的分布式 NoSQL 数据库管理系统,由 Apache 软件基金会开发。它专为处理大量数据而设计,具有高可用性、无单点故障、
使用Nifi将数据从Kafka传输到Cassandra
转载自:https://xbuba.com/questions/53895448 我想从收集数据Kafka使用Nifi在Cassandra。我为此创建了这样的流程。 我的数据库连接配置是这样的: 这是我对ConvertJsonToSQL处理器的配置:
Cassandra操作和性能优化
转载自:https://blog.51cto.com/eric100/1770036 1. Cassandra操作 本文档操作都是在单数据中心,Vnode上操作 1.1. 添加节点到集群中 1.1.1. 添加非seed单节点 1.在新节点上安装Cassandra,但不要启动 2.修改cassandra.yaml文件: cluster_name –
Cassandra数据类型与Java数据类型对应关系
CQL类型对应Java类型描述asciiStringascii字符串bigintlong64位整数blobByteBuffer/byte[]二进制数组booleanboolean布尔counterlong计数器,支持原子性的增减,不支持直接赋值decimalBigDecimal高精度小数doubledouble64位浮点数floatfloat32位浮点数inetInetAddressipv4

【扩散】Cassandra资料大全入社区大群邀请
前言 Cassandra是全球范围内最流行的宽表数据库,在DB-Ranking,排名前10,自身有着居多优势,但是国内一直缺乏相关中文资料。为了推广Cassandra,Cassandra爱好者特别在一起构建 【Cassandra中文社区:http://cassandra123.com】。本文尽量汇总Cassandra的相关资料(特别是中文的部分),此文章会不断更新,阅读者请关注原文。为了营

cassandra大表读写timeout的配置解决
程序异常如下:Caused by: com.datastax.driver.core.exceptions.WriteTimeoutException: Cassandra timeout during write query at consistency LOCAL_ONE (1 replica were required but only 0 acknowledged the write
Cassandra 备份 - 1 - 节点镜像恢复
之前比较关注如何使用Cassandra,但是真正想大规模使用前提还是需要搞清楚备份机制,确保数据安全。 本文主要内容来自文档 "Cassandra2.2"的翻译。最后部分为真实操作案例。 这里假设你已经了解了Cassandra的压缩、墓碑、数据一致性。 原始文档链接:http://docs.datastax.com/en/cassandra/2.2/cassandra/operations
Cassandra数据迁移-BulkLoad离线工具介绍
该工具通过文件流接口快速导入数据到cassandra集群,是最快地将线下数据迁移到线上cassandra集群方法之一,准备工作如下 线上cassandra集群线下数据,sstable格式或者csv格式。同vpc一台独立的ecs,开放安全组,能访问cassandra集群端口 1. 准备同vpc下客户端ecs 建议独立的ecs,不要和线上cassandra集群混用,混用会影响线上服务。
Cassandra nodetool详解
Cassandra自带一个nodetool工具,安装目录/bin/nodetool nodetool help:帮助信息 [cassandra@node3 bin]$ ./nodetool helpusage: nodetool [(-p <port> | --port <port>)] [(-h <host> | --host <host>)][(-pwf <passwordF
Cassandra nodetool常用操作
nodetool 是cassandra中非常常用的命令,其中包含很多条子命令,本来想一条一条的翻译出来,但是工作量显然很大,所以就只写出简要的而且常用的。 其实,nodetool大部分都是 nodetool -h host -u username -pw password [option] 的格式。 nodetool -h 192.168.30.231 -u ershixiong -p
Apache Cassandra SSTable 存储格式详解
简介: 在 Cassandra 中,当达到一定条件触发 flush 的时候,表对应的 Memtable 中的数据会被写入到这张表对应的数据目录(通过 data_file_directories 参数配置)中,并生成一个新的 SSTable(Sorted Strings Table,这个概念是从 Google 的 BigTable 借用的)。 在 Cassandra 中,当达到一定条件触发

Apache Cassandra性能调优-混合工作负载压缩
这是我们关于使用Apache Cassandra进行性能调整的系列文章中的第三篇。在我们的第一篇文章中,我们讨论了如何使用火焰图直观地诊断性能问题。在第二篇文章中,我们讨论了JVM调优,以及不同的JVM设置如何影响不同的工作负载。 在本文中,我们将深入探讨通常被忽略的表级设置:压缩。可以在创建或更改表时指定压缩选项,如果未指定,则默认启用。当处理写入繁重的工作负载时,默认值很棒,但是对于读

【Cassandra】数据模型
都说Cassandra是列族数据库,这里的列族到底什么含义。 个人觉得,这个“列族”更侧重于数据模型,也就是Cassandra中的Column和columnfamily的概念。它其实只是Cassandra中的一个名词或者术语,并不是我们通常理解的关系型数据库的中列。以下是Cassadra中术语: Column:其实是某一行数据中的某一列,类似一个键值对,包括<name, value, time

Apache Zeppelin 中 Cassandra CQL 解释器
Name Class Description %cassandra CassandraInterpreter 为Apache Cassandra CQL查询语言提供解释器 启用Cassandra解释器 在笔记本中,要启用Cassandra解释器,请单击Gear图标并选择Cassandra。 使用Cassandra解释器 在段

ScyllaDB:用 C++ 重写后的 Cassandra ,性能提高了十倍
转自: http://blog.jobbole.com/93027/ 在 9 月下旬的 Cassandra 峰会上,Avi Kivity、Dor Laor 和 Benny Schnaider 宣布推出 ScyllaDB,宣称是用 C++ 重写后的 Cassandra,性能提高 10 倍,并且延迟极低。新的 ScyllaDB 每个节点每秒能处理 1 百万交易。 Cass

Cassandra HBase和MongoDb性能比较
Cassandra HBase和MongoDb性能比较 这是一篇基于亚马逊云平台上对三个主流的NoSQL数据库性能比较,在读写两个操作不同的组合情况下性能表现不同。 横坐标是吞吐量,纵坐标是延迟,这是一对矛盾,吞吐量越大,延迟越低,代表越好。 1. 纯粹插入,Cassandra领先,见下图: 2.WorkloadA: 读修改操作各占一半情况下的修改性能:MongoDB
Cassandra_Casssandra Cassandra.yaml 性能调优
快速入门:最小化配置集群 cluster_name 集群的名字,默认情况下是TestCluster。对于这个属性的配置可以防止某个节点加入到其他集群中去,所以一个集群中的节点必须有相同的cluster_name属性。 listen_address Cassandra需要监听的IP或主机名,默认是localhost。建议配置私有IP,不要用0.0.0.0。 commitlog_

Cassandra_ Cassandra 定期删除数据方案 设计
虽然 Cassandra 本身就是针对于 大数据设计的。但是难免会数据量过大,所以可以定期清除下数据。 场景:清除N天之前 visitor 表内的数据。 经过一天,我总共设计了这几种方案。 方案 一·,二 都使用了 TTL, 这里对TTL进行一个简单的介绍。 TTL :生存时长。在 Cassandra 的计算单位 为 Second 秒 方案一: 插入数据的
Cassandra_Cassandra 使用心得 二三说
Cassandra 作为一个比较新兴的数据库,对于大数据量的支持比较好。 但是使用Cassandra 中也有许多需要注意的地方,我来总结一下,本文不定期更新。。。 特点一: Cassandra 作为一个数据库支持 TTL ,生存时长(expire time) 示例: 1.针对每一条数据: INSERT INTO latest_temperatures(weathers
Loki日志系统分布式部署实践之 Cassandra
点击上方 "zhisheng"关注, 星标或置顶一起成长 Flink 从入门到精通 系列文章 1. 说明 Loki 支持文件系统、对象存储、NoSQL,因为对象存储大多都要使用公有云,所以暂时使用 Cassandra 作为存储,目前的实现里它支持 index 和 chunk 2. 基本知识 Cassandra 是一个开源的、分布式、无中心节点、弹性可扩展、高可用、容错、一致性协调、面向列的 No
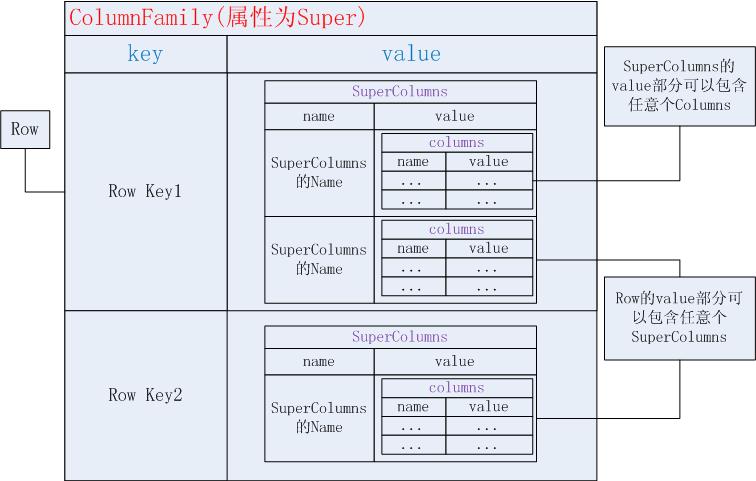
cassandra学习笔记4--Cassandra Java客户端
现在开始深入了解一下cassandra的数据模型。cassandra是一种NoSQL数据库,NoSQL并不是指没有SQL语句,而是指No Relational。cassandra的数据模型结合了Dynamo的key/value和BigTable 的面向列的特点,主要被设计为存储大规模的分布式数据。 PS:图片在这里显示不全,why?要看图片,可以另存为或复制
解剖Cassandra 【3】Index and Search
1。Primary Index 假设我们有这么一个 ColumnFamily, 它是一个地址本,包含 5 行记录,例子如下。 AddressBook = { // 这是一个 ColumnFamily,每一行包含 4 个 columns。 "John":{ //第一行数据的 Row-key。 {name: "street", value: "Howard stree

Cassandra与RDBMS的设计差别
Cassandra的模型和查询方式与RDBMS有很多的不同,记住这些差异非常重要。 没有查询语言 SQL是关系型数据库的标准查询语言,Cassandra却没有查询语言。不过Cassandra确实也有自己的RPC序列化机制,Thrift。通过Thrift API,用户可以访问其中的数据。 没有引用完整性 Cassandra没有引用完整性的概念,因而没有join的概念。在关系型数据库中,你

图灵七月书讯【Cassandra权威指南将在7月末上市】
重点图书推荐 Cassandra权威指南——本书是一本广受好评的Cassandra 图书。与传统的关系型数据库不同,Cassandra 是一种开源的分布式存储系统。书中介绍了它无中心架构、高可用、无缝扩展等引入注目的特点,讲述了如何安装、配置Cassandra 及如何在其上运行实例。 [样章试读] Flash游戏编程基础教程——本本书是Flash 游戏设计方面的入门级图书。全
Cassandra 概况
如果一个概念一开始不是荒诞不羁的话,那它也没什么前途。 ——阿尔伯特 ·爱因斯坦 欢迎阅读《Cassandra 权威指南》。本书的目标是帮助开发者和数据库管理员们理解这种重要的新型数据库,探索它与传统的关系型数据库