本文主要是介绍Cassandra_Cassandra 使用心得 二三说,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Cassandra 作为一个比较新兴的数据库,对于大数据量的支持比较好。
但是使用Cassandra 中也有许多需要注意的地方,我来总结一下,本文不定期更新。。。
特点一:
Cassandra 作为一个数据库支持 TTL ,生存时长(expire time)
示例:
1.针对每一条数据:
INSERT INTO latest_temperatures(weatherstation_id,event_time,temperature)
VALUES (’1234ABCD’,’2013-04-03 07:02:00′,’73F’) USING TTL 20;
2.针对表级别设置每条数据的默认生存周期:
创建表
CREATE TABLE test_ttl(
id int PRIMARY KEY,
value text
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 30
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
插入数据:
INSERT INTO test_ttl(id,value)
VALUES (1, '2013-04-03');
校验数据:
SELECT * FROM test.test_ttl;
修改默认的生命时长:
ALTER TABLE test.test_ttl WITH default_time_to_live = 120;
更多有关于生存周期的设计方案,请参考我的博文
特点二:
Cassandra where 中的筛选条件 的 column . 一定要在上面预先做索引. 否则是不能作为筛选条件的。
示例
CREATE TABLE test_index(
id int PRIMARY KEY,
value text
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
插入数据:
INSERT INTO test_index(id,value) VALUES (2, 'GoGo');
查询数据:
SELECT * FROM test_index WHERE value='GoGo';
此时会出错:

------------------------------
特点三:
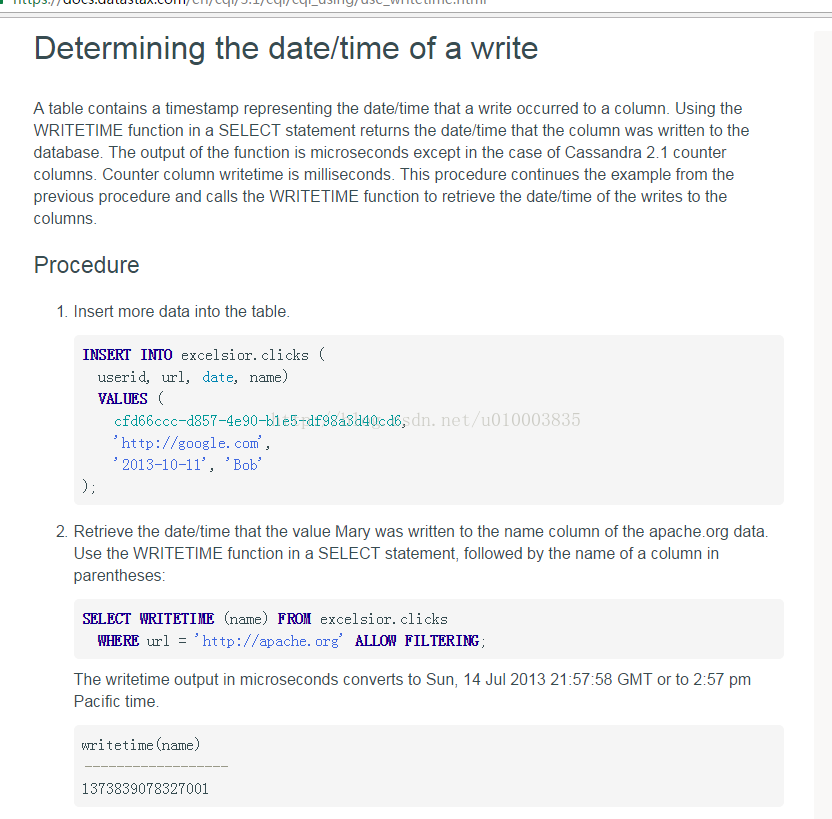
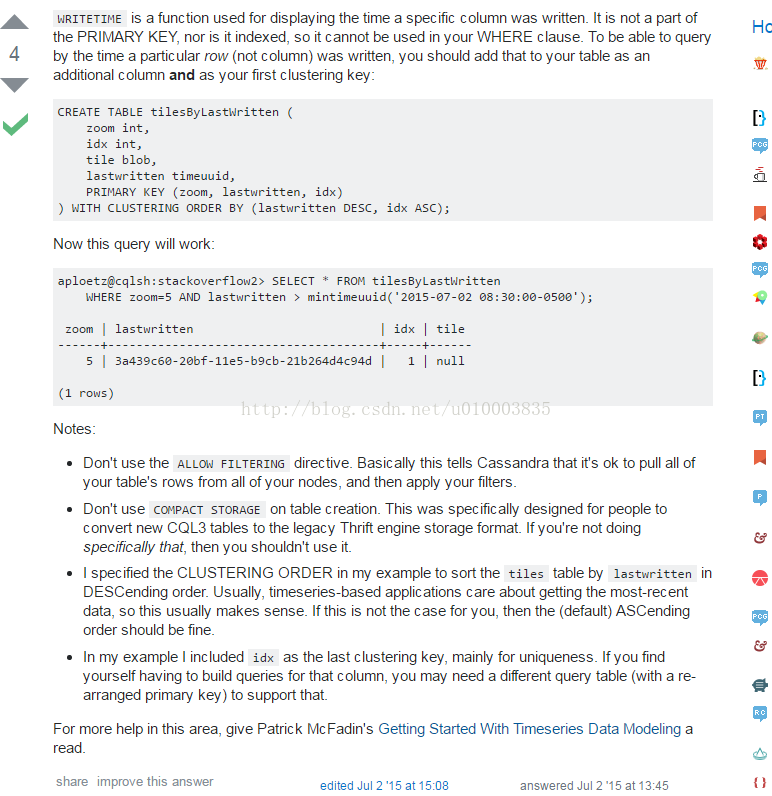
Cassandra 每个列会有自身的 wirtetime 属性, 但是由于 writetime 属性 上面没有索引, 所以不能作为筛选条件。
Tips: 运用writetime 的时候只能在 non pk (not PRIMARY KEY ) 上
示例
CREATE TABLE test_index(
id int PRIMARY KEY,
value text
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
INSERT INTO test_index(id,value) VALUES (2, 'GoGo');
错误:
SELECT WRITETIME(id) FROM test_index WHERE id=2;

正确:
SELECT WRITETIME(value) FROM test_index WHERE id=2;

WRITETIME 可以转换为 unix 时间戳, 只要截取前10位即可
1481268509217414 -> 1481268509

更多关于 WRITETIME 的介绍:
https://docs.datastax.com/en/cql/3.1/cql/cql_using/use_writetime.html
http://stackoverflow.com/questions/31184376/how-to-filter-cassandra-result-based-on-writetime
这篇关于Cassandra_Cassandra 使用心得 二三说的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






