本文主要是介绍cassandra学习笔记4--Cassandra Java客户端,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、cassandra数据模型的特点
1.它基于key-value模型
cassandra的数据库由ColumnFamilies组成,一个ColumnFamily是一个key-value键值对的集合。若和关系型数据库类比,ColumnFamily相当于表,而里面的key-value键值对相当于表里的一条记录。
2.它的key-value模型有多层嵌套
ColumnFamily里的每条记录都是一个key-value对,value部分存放的是无限制的Columns。每个Column都有一个Column Name和value,因此Column实际也是一个key-value对。但Column的value部分已经是最基本的数据存储单元,不能再向下嵌套了。在这种嵌套下,ColumnFamily的每条记录都包含一个key和一个由Columns组成的value(至少有一个Column),也就是说ColumnFamily的value只是一个中间人,实际存储数据的是value里的Columns。如下图所示。

上面所说的是双层嵌套,还有一种三层嵌套。在这种情况下,ColumnFamily每条记录的value部分不是Columns,而是一种被称为SuperColumn的结构。SuperColumn的key是SuperColumn name,它的value部分可以存储多个Columns,如下图所示:

这样就有以下三种嵌套:
- ColumnFamily: key - value(SuperColumn)
- SuperColumn: key(SuperColumn name) - value(Column)
- Column: key(Column name) - value
SuperColumn里不能再存储SuperColumn,因此cassandra的嵌套最多为三层。
3.Column和SuperColumn的name部分都可以用来存储实际数据
首先,它们的name部分可以用来当做属性名。比如在一个存储用户邮箱的记录里,它是这样的:
- Column name=Email,value="fykhlp@163.com";
这是我们在传统关系型数据库里所习惯和使用的。但在cassandra里,name部分也可以直接用来存储实际数据。比如在一个只用来存储用户邮箱的记录里,我们可以这样:
- Column name="fykhlp@163.com",value=null;
这得益于(a)cassandra的非结构化数据存储,数据的存储不需要固定的位置(b)name部分也是使用字节流存储(关系型数据库的字段名必须是字符),因此可以存储任何类型的数据。
4.Column和SuperColumn按照name的顺序存储
需要注意的是,cassandra并不是按照value的顺序存储数据,而是按照name。关于这点下文会详细说明。
二、cassandra数据模型的构成
在这一部分,将详细讲解cassandra数据模型的各个组成部分。
1.Column
Column是数据存储的最小单位。它是一个包括name、value和timestamp(时间戳)的元祖。下面是一个Column的示例:
- {
- name:"age",
- value:24,
- timestamp:123456789
- }
方便书写,后文将省略时间戳,我们将Column看成一个name-value对。name和value都是字节流,长度没有限制。
2.SuperColumn
一个SuperColumn是一个真正的name-value对,它没有时间戳。而且它的value部分可以包含无限个Column,并且用Column的name部分作为关键字。下面是一个SuperColumn的示例:
- {
- name:"homeAddress"
- //value部分是多个Columns
- value:
- //这里的key是Column的name部分
- street:{name:"street",value:"XiTuCheng road"},
- city:{name:"city",value:"BeiJing"},
- zip:{name:"zip",value:"410083"},
- }
在后面,不再写出name和value,上文将简写为:
- homeAddress:{
- street:"XiTuCheng road",
- city:"BeiJing",
- zip:"410083",
- }
3.Row
在介绍下文的ColumnFamily前,我们先熟悉一下Row。在cassandra里,每个ColumnFamily都存在一个单独的文件里,这个文件以Row为单位存储并排序。因此,我们应尽量将相关的Column放在同一个ColumnFamily里。
ColumnFamily的组成是一行行的Row,一个Row就是一个key-value对,key决定数据将被存在哪台机器上(笔记二的token部分有解释),value部分就是Columns或SuperColumns。
4.ColumnFamily
ColumnFamily是一个可以包含无数个Row的结构,又因为Row的value部分是Columns或SuperColumns,因此ColumnFamily实际是Columns和SuperColumns的容器。ColumnFamily对应关系型数据库里的“表”。下面给出ColumnFamily和Row的一个简单示例(使用Column):
- User={//这是一个ColumnFamily,名字是User
- zhangsan:{//这是一个Row,Row的key是zhangsan
- //下面的value可以有无限制的Columns,这里有两个
- username:"zhangsan",
- email:"zhangsan@163.com",
- },//这个Row结束了
- lisi:{//这是第二个Row,Row的key是lisi
- //value部分,依然是Columns,lisi有三个
- username:"lisi",
- email:"lisi@163.com",
- phone:"123456"
- },//Row结束
- }
又如下图所示:

在这个层面没有设计模式的要求,Row没有预先定义它们应该包含的Columns列表,就如上面的示例,李四可以随意的多一个phone的Column。一个Row可能有成千上万个Columns而另一个Row可能只有一个Column。cassandra在这一点上有无法比拟的灵活性。
5.属性为Super的ColumnFamily
上面的示例是一个type为标准的(Standard)ColumnFamily,另外也有Super的ColumnFamily,这取决于我们创建ColumnFamily时的定义。顾名思义,一个类型为Super的ColumnFamily的Row存储的不是Columns,而是SuperColumns。在这种情况下,一个Row的value部分有若干个SuperColumns,一个SuperColumns的value部分又有若干个Columns。如下图所示:
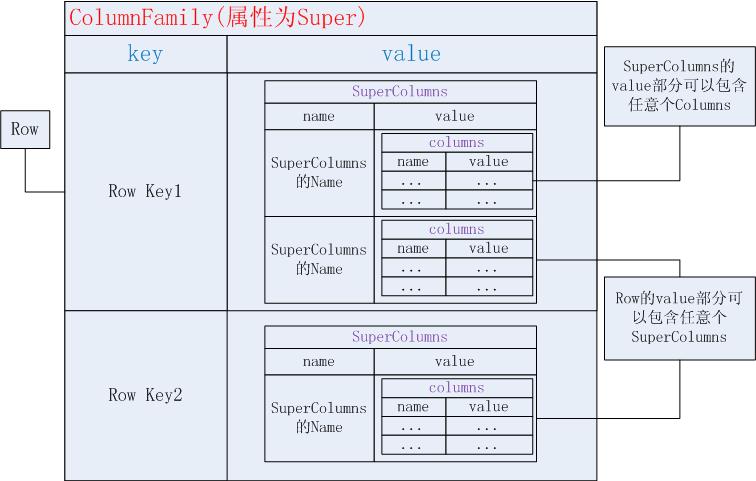
为什么要有SuperColumn呢?SuperColumn提供了比普通Column多一级的一对多关系。Column只能让一个key存储一组相关联的Columns,而这个能让一个key存储多组相关联的Columns。
这里给出一个应用:假设我们提供一种网上地址本的服务,用户可以在这保存他的朋友们的地址,而地址又是由不同的属性如邮编、街道、城市等组成。这时候我们可以采用SuperColumn。对于ColumnFamily,它的key使用的是用户自己的名字,value部分是若干SuperColumns。每个SuperColumns的name部分是用户某个朋友的名字,value部分是若干Columns,存储地址的各个属性。下面是示例:
- AddressBook={//这是一个SuperColumnFamily,名字是AddressBook
- zhangsan:{//这是一个Row,key是zhangsan,张三的地址本
- //下面是Row的Value部分,可以有任意个SuperColumns
- lisi:{//这是SuperColumn的name
- //下面是Columns,表示地址
- street:"XiTuCheng road",
- zip:"410083",
- city:"BeiJing"
- },
- wangwu:{//另一个SuperColumn
- street:"XiTuCheng road",
- zip:"410083",
- city:"BeiJing"
- },
- zhaoliu:{//SuperColumn
- street:"XiTuCheng road",
- zip:"410083",
- city:"BeiJing"
- },
- .......
- }//end the row of zhangsan
- lisi:{//这是另一个Row,key是lisi,李四的地址本
- wangwu:{//SuperColumn
- street:"XiTuCheng road",
- zip:"410083",
- city:"BeiJing"
- },
- zhangsan:{//SuperColumn
- street:"XiTuCheng road",
- zip:"410083",
- city:"BeiJing"
- },
- .......
- }
- }
6.KeySpace
KeySpace是最外层的容器,也是最大的容器,通常一个应用程序对应一个KeySpace。所有的ColumnFamily都位于一个KeySpace里面,它相当于关系数据库里的DB。
三、cassandra的数据排序
前面所介绍的是cassandra里各种数据容器的概念,现在来看看数据模型的另外一个关键地方即数据是如何排序的。cassandra和关系型数据库不同,你无法在取出数据时指定一种排序(order by)。数据在你存储到集群,被写入数据库时已经按照预定的规则被排好序。当你取出数据时,它们的顺序已经确定了。
如前问所说,cassandra是按照name而不是value进行排序。cassandra在写入数据的时候,每个row中的所有Columns会按照name自动排好序。排序的规则由ColumnFamily的CompareWith选项确定,可选的有:BytesType,UTF8Type,LexicalUUIDType,TimeUUIDType,AsciiType和LongType。这些选项将Column Name看作不同的数据类型来排序,如LongType将它视为64bit Long类型。如下面给出的例子:
- {name: 123, value: “hello there”},
- {name: 832416, value: “kjjkbcjkcbbd”},
- {name: 3, value: “101010101010″},
- {name: 976, value: “kjjkbcjkcbbd”}
采用LongType排序类型,结果是:
- {name: 3, value: “101010101010″},
- {name: 123, value: “hello there”},
- {name: 976, value: “kjjkbcjkcbbd”},
- {name: 832416, value: “kjjkbcjkcbbd”}
采用UTF8Type排序类型,结果是:
- {name: 123, value: “hello there”},
- {name: 3, value: “101010101010″},
- {name: 832416, value: “kjjkbcjkcbbd”},
- {name: 976, value: “kjjkbcjkcbbd”}
这些排序规则也适用于SuperColumns在Row内的排序,但对于SuperColumn内的Columns,用来定义排序规则的参数不再是Row和SuperColumn里的CompareWith,而是CompareSubcolumnsWith。
我们可以自定义排序规则,实现接口org.apache.cassandra.db.marsha1.IType即可。
这篇关于cassandra学习笔记4--Cassandra Java客户端的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



