caffeine专题

「Spring 缓存最佳实践」Caffeine 与 Redis 分层缓存架构
在现代的应用程序中,缓存是提升系统性能和响应速度的关键手段。Spring 框架为我们提供了非常强大的缓存抽象,使我们可以方便地集成并使用各种缓存技术。本文将重点介绍如何在 Spring 应用中构建基于 Caffeine 和 Redis 的分层缓存架构,并分享一些最佳实践。 缓存层次设计 在构建缓存解决方案时,通常采用分层缓存的设计模式。将本地缓存(如 Caffeine)作为一级缓存,并将远程缓

Caffeine - Caches - Writer
Caffeine - Caches - Writer 写入器可能的用例写入模式分层同步监听器 参考 写入器 LoadingCache<Key, Graph> graphs = Caffeine.newBuilder().writer(new CacheWriter<Key, Graph>() {@Override public void write(Key key, Grap

Caffeine - Caches - Refresh
Caffeine - Caches - Refresh 刷新 刷新 LoadingCache<Key, Graph> graphs = Caffeine.newBuilder().maximumSize(10_000).refreshAfterWrite(1, TimeUnit.MINUTES).build(key -> createExpensiveGraph(key));
Caffeine - Caches - Removal
Caffeine - Caches - Removal 移除明确移除移除监听 移除 术语: 剔除是指基于剔除策略的移除无效只是被调用者手工移除移除是剔除和无效的后续操作 明确移除 在任何时候,您都可以显式的使缓存条目无效,而不必等待条目被剔除。 // individual keycache.invalidate(key)// bulk keyscache.inv
Caffeine - Caches - Eviction
Caffeine - Caches - Eviction 剔除策略基于容量的剔除基于时间的剔除基于引用的剔除 剔除策略 Caffeine提供了三种类型的提出方式:基于容量的剔除、基于时间的剔除和基于引用的剔除。 基于容量的剔除 // Evict based on the number of entries in the cacheLoadingCache<Key, Gr
Caffeine - Caches - Population
Caffeine - Caches - Population 填充策略手动加载自动加载异步手动加载异步自动加载 填充策略 Caffeine提供了4中填充策略:手动加载、同步加载以及异步变体(异步手工、异步加载)。 手动加载 Cache<Key, Graph> cache = Caffeine.newBuilder().expireAfterWrite(10, TimeUn
Caffeine - Home
Caffeine - Home 1. 缓存条目自动加载2. 缓存条目异步加载3. 根据访问频率和新近度的剔除策略4. 基于最后访问时间的剔除策略5. 条目删除(移除)通知6. 条目写入传播到外部资源7. 缓存累积访问量统计 Caffeine是基于Java 8的高性能缓存库,可提供接近最佳的命中率。 缓存与ConcurrentMap类似,但又不尽相同。其中最根本的区别是Concur
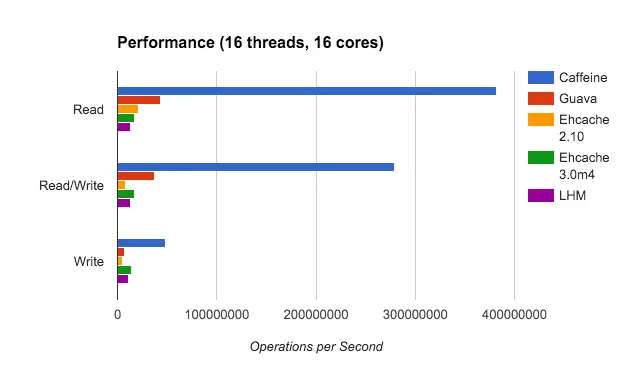
Java本地缓存技术选型(Guava Cache、Caffeine、EhCache)
前言 对一个java开发者而言,提到缓存,第一反应就是Redis。利用这类缓存足以解决大多数的性能问题了,我们也要知道,这种属于remote cache(分布式缓存),应用的进程和缓存的进程通常分布在不同的服务器上,不同进程之间通过RPC或HTTP的方式通信。这种缓存的优点是缓存和应用服务解耦,支持大数据量的存储,缺点是数据要经过网络传输,性能上会有一定损耗。 与分布式缓存对应的是本地缓存,缓

本地缓存Caffeine在springBoot的简单介绍与使用
Caffeine 是一个高性能的 Java 缓存库,它提供了灵活的缓存策略,比如自动加载、大小限制、时间过期和引用回收等。这个库是基于 Google Guava 缓存设计而来,但在性能上进行了大幅优化,是当前 Java 应用中常用的缓存解决方案之一。 其实就是操作本地缓存而已,用起来和redis差不多,但是会快很多,因为是本地的,没有网络开销。 导入依赖: <depen
文献阅读(80)Caffeine
文章目录 1 缩写 & 引用2 abstract & introduction3 卷积加速器3.1 对带宽的优化 4 自动化流程 题目:Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks时间:2019期刊:TCAD研究机构:Chen Zh
使用SpringAOP+Caffeine实现本地缓存
文章目录 一、背景二、实现1、定义注解2、切面3、缓存工具类 三、测试 一、背景 公司想对一些不经常变动的数据做一些本地缓存,我们使用AOP+Caffeine来实现 二、实现 1、定义注解 import java.lang.annotation.ElementType;import java.lang.annotation.Retention;import java.l
Caffeine--实现进程缓存
本地进程缓存特点 缓存在日常开发中起着至关重要的作用, 由于存储在内存中, 数据的读取速度非常快,能大量减少对数据库的访问,减少数据库的压力. 缓存分为两类: 分布式缓存, 例如Redis: 优点: 存储容量大, 可靠性更好, 可以在集群间共享缺点: 访问缓存存在网络开销场景: 缓存数据量较大, 可靠性要求较高, 需要在集群间共享 进程本地缓存, 例如HashMap, GuavaC
JVM级缓存本地缓存Caffeine
JVM级缓存本地缓存Caffeine和Guava Cache 前言一、创建缓存的代码逻辑二、Caffeine的优化方面淘汰算法W-TinyLFU 三、Caffeine的业务使用总结 前言 最新的 Java 面试题,技术栈涉及 Java 基础、集合、多线程、Mysql、分布式、Spring全家桶、MyBatis、Dubbo、缓存、消息队列、Linux…等等,会持续更新。 一、
Redis + Caffeine = 王炸!!
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。 随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffein

Redis+Caffeine 太强了!二级缓存可以这样实现!
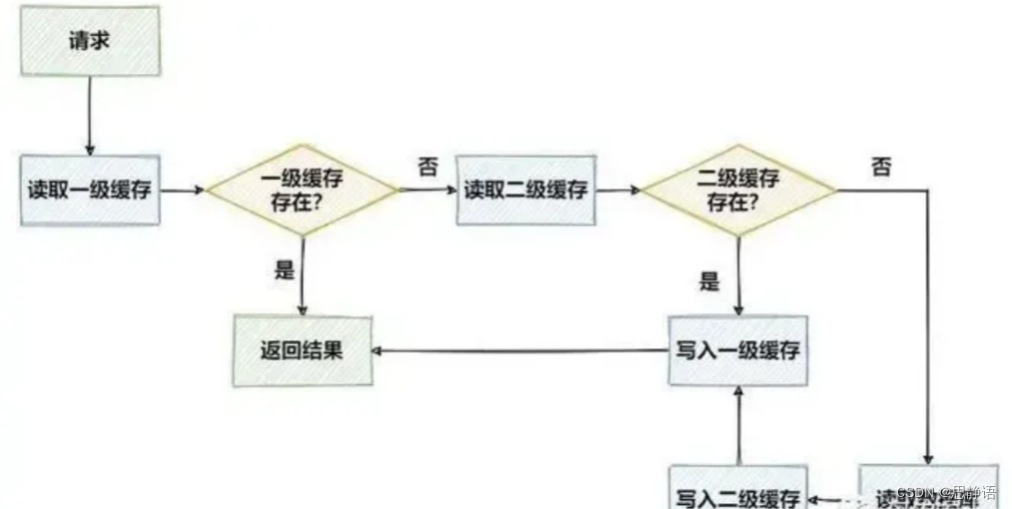
在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。 在一些场景下可能还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。 于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。 二级缓存的访问流程可以用下面这张图来表示:
Caffeine+redis 实现二级缓存
一:目录结构 二:分而治之 redis和caffeine有各自的bean目录 自定义实现的bean(xxxxCache,Manager,Configuration,CacheResolve)等可以放在这里 redis和caffeine有各自的配置目录,分开配置自己的bean,序列化等 分而治之,回归一统:单独配置好Redis,单独配置好Caffeine,最后交给合并缓存(CaffeineR

最近看到的缓存好文章(3):深入解密来自未来的缓存-Caffeine
1.前言 读这篇文章之前希望你能好好的阅读: 你应该知道的缓存进化史 和 如何优雅的设计和使用缓存? 。这两篇文章主要从一些实战上面去介绍如何去使用缓存。在这两篇文章中我都比较推荐Caffeine这款本地缓存去代替你的Guava Cache。本篇文章我将介绍Caffeine缓存的具体有哪些功能,以及内部的实现原理,让大家知其然,也要知其所以然。有人会问:我不使用Caffeine这篇文章应该对我没

Redis+Caffeine两级缓存,让访问速度纵享丝滑
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。 随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffein

性能利器Caffeine缓存全面指南
第1章:引言 大家好,我是小黑,今天咱们聊聊Caffeine缓存,小黑在网上购物,每次查看商品都要等几秒钟,那体验肯定不咋地。但如果用了缓存,常见的商品信息就像放在口袋里一样,随时取用,速度自然就快多了。这就是缓存的魔力,它通过存储临时数据,减少数据库的重复读写,提升系统的响应速度和性能。 在Java里,Caffeine缓存是一个现代化的、高性能的Java缓存库,用起来既方便又快捷。相
实现多级缓存(Redis+Caffeine)
文章目录 多级缓存的概述多级缓存的优势 多级缓存的概述 在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。 随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了
Caffeine--缓存组件
Caffeine 概念缓存手动加载自动加载手动异步加载自动异步加载 驱逐策略基于容量基于时间基于引用 移除显式移除 概念 Caffeine是一个基于Java8开发的提供了近乎最佳命中率的高性能的缓存库。与ConcurrentMap有点相似。最根本的区别是ConcurrentMap将会持有所有加入到缓存当中的元素,直到它们被从缓存当中手动移除。Caffeine的缓存Cache 通
一个缓存使用的思考:Spring Cache VS Caffeine 原生 API
最近在学习本地缓存发现,在 Spring 技术栈的开发中,既可以使用 Spring Cache 的注解形式操作缓存,也可用各种缓存方案的原生 API。那么是否 Spring 官方提供的就是最合适的方案呢?那么本文将通过一个案例来为你揭晓。 Spring Cache Since version 3.1, the Spring Framework provides support for tra
Java内存缓存神器:Caffeine(咖啡因)
文章目录 一、Caffeine简介二、缓存加载1、手动加载2、自动加载3、手动异步加载(需要额外的包)4、自动异步加载 三、缓存清理1、基于容量2、基于时间3、基于引用 四、缓存移出1、手动移出2、移出监听器 五、刷新缓存 一、Caffeine简介 官网:https://github.com/ben-manes/caffeine/wiki/Home-zh-CN Caffeine
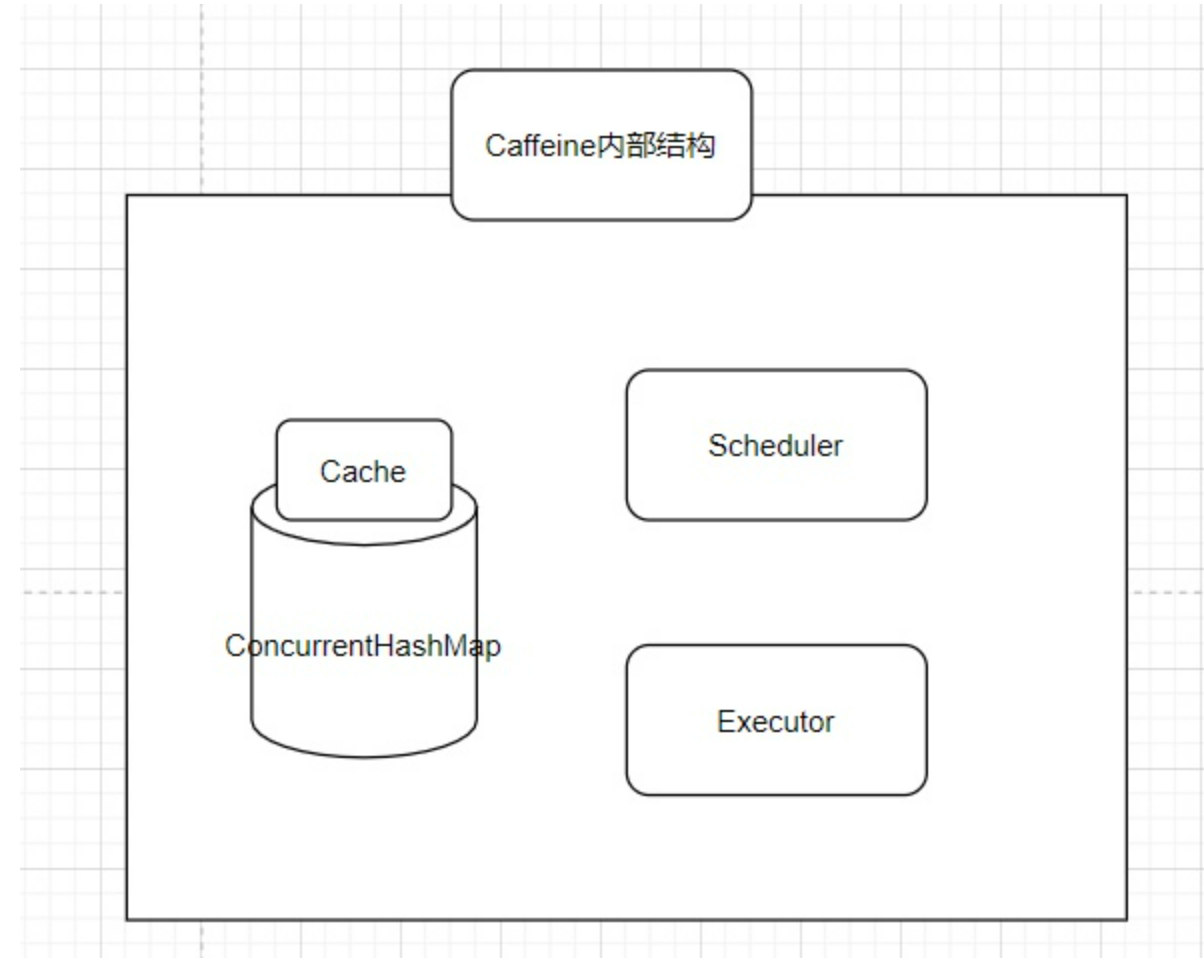
Java 的高性能缓存库-caffeine!
在项目中用到的除了分布式缓存,还有本地缓存,例如:Guava、Encache,使用本地缓存能够很大程度上提升程序性能,本地缓存是直接从本地内存中读取,没有网络开销。 今天给大家介绍一个高性能的 Java 缓存库 – Caffeine 。 简介 Caffeine是基于Java8 的高性能缓存库,借鉴了 Guava 和 ConcurrentLinkedHashMap 的设计经验,拥有更高的缓存命
Caffeine:为每个元素动态设置过期时间
Caffeine:为每个元素动态设置过期时间 Caffeine 是一个开源的 Java 缓存库,它提供了一个高效且易于使用的缓存解决方案,可以帮助 Java 开发人员快速实现缓存功能,提升应用程序的性能和响应速度。Caffeine 支持多种缓存策略,并具有高性能、低延迟和低内存占用的特点,是 Java 开发人员在构建高性能应用程序时不可或缺的工具之一。 对于Caffeine的缓存过期设置来说,
springboot集合caffeine实现本地缓存(模板,可直接cv)
CacheConfig 配置 要在项目中使用下本地缓存,方便更快的调用数据, 查询了很多文档发现都比较冗余,于是自己摸索了好一会才整理出一套能用的模板。文末附上了完整代码 引入pom.xml <dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId></depe