本文主要是介绍Redis + Caffeine = 王炸!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在高性能的服务架构设计中,缓存是一个不可或缺的环节。在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库。在提升访问速度的同时,也能降低数据库的压力。
随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与服务性能。于是,就产生了使用本地缓存作为一级缓存,再加上远程缓存作为二级缓存的两级缓存架构。
在先不考虑并发等复杂问题的情况下,两级缓存的访问流程可以用下面这张图来表示:
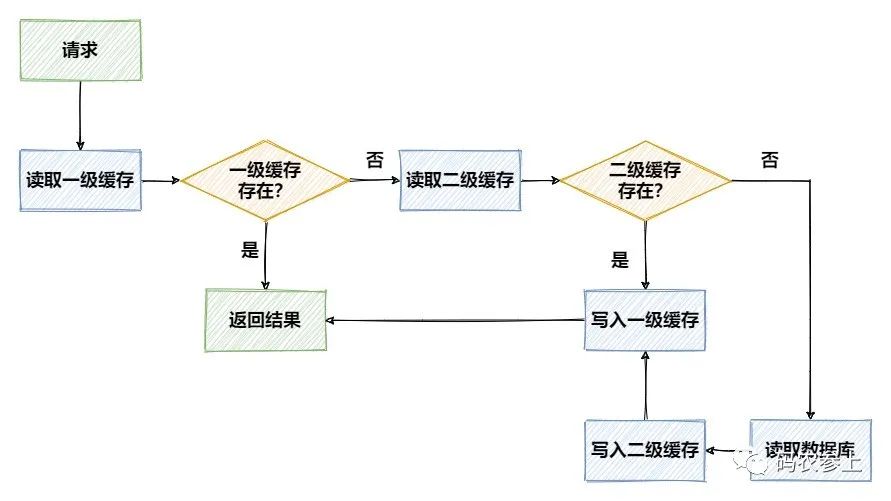
优点与问题
那么,使用两级缓存相比单纯使用远程缓存,具有什么优势呢?
-
本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
-
使用本地缓存能够减少和
Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
但是在设计中,还是要考虑一些问题的,例如数据一致性问题。首先,两级缓存与数据库的数据要保持一致,一旦数据发生了修改,在修改数据库的同时,本地缓存、远程缓存应该同步更新。
另外,如果是分布式环境下,一级缓存之间也会存在一致性问题,当一个节点下的本地缓存修改后,需要通知其他节点也刷新本地缓存中的数据,否则会出现读取到过期数据的情况,这一问题可以通过类似于Redis中的发布/订阅功能解决。
此外,缓存的过期时间、过期策略以及多线程访问的问题也都需要考虑进去,不过我们今天暂时先不考虑这些问题,先看一下如何简单高效的在代码中实现两级缓存的管理。
这或许是一个对你有用的开源项目,mall项目是一套基于 SpringBoot + Vue + uni-app 实现的电商系统(Github标星60K),采用Docker容器化部署,后端支持多模块和微服务架构。包括前台商城项目和后台管理系统,能支持完整的订单流程!涵盖商品、订单、购物车、权限、优惠券、会员、支付等功能!
Boot项目:https://github.com/macrozheng/mall
Cloud项目:https://github.com/macrozheng/mall-swarm
视频教程:https://www.macrozheng.com/video/
项目演示:
准备工作
在简单梳理了一下要面对的问题后,下面开始两级缓存的代码实战,我们整合号称最强本地缓存的Caffeine作为一级缓存、性能之王的Redis作为二级缓存。首先建一个springboot项目,引入缓存要用到的相关的依赖:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
在application.yml中配置Redis的连接信息:
spring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
在下面的例子中,我们将使用RedisTemplate来对redis进行读写操作,RedisTemplate使用前需要配置一下ConnectionFactory和序列化方式,这一过程比较简单就不贴出代码了,有需要本文全部示例代码的可以在文末获取。
下面我们在单机环境下,将按照对业务侵入性的不同程度,分三个版本来实现两级缓存的使用。
V1.0版本
我们可以通过手动操作Caffeine中的Cache对象来缓存数据,它是一个类似Map的数据结构,以key作为索引,value存储数据。在使用Cache前,需要先配置一下相关参数:
@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeineCache(){
r这篇关于Redis + Caffeine = 王炸!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





