blip2专题
BLIP和BLIP2 论文讲解
文章目录 BLIPIntroductionMethod模型架构预训练目标字幕和过滤(Capfilt) BLIP2IntroductionMethod模型结构Q-Former预训练第一阶段Q-Former预训练第二阶段 BLIP 论文: 《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-L
多模态视觉语言模型:BLIP和BLIP2
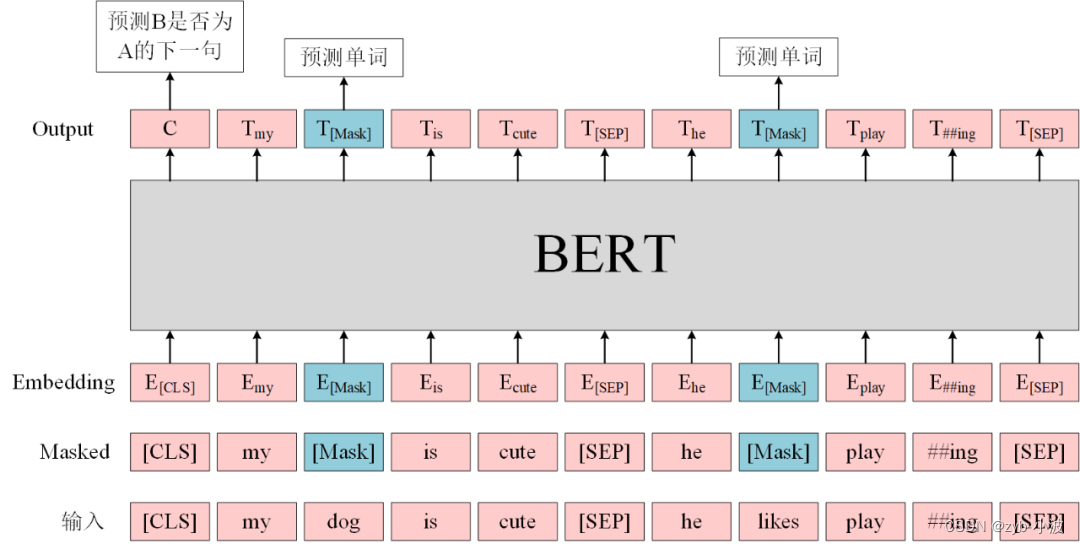
1. BLIP BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation BLIP的总体结构如下所示,主要包括三部分: 单模态编码器(Image encoder/Text encoder):分别进行图像和文本编码,文本编码器和BERT一样在输

coca、blip、blip2在image caption中的实验效果对比
coca脚本 # pip install open_clip_torch transformersimport open_clipimport torchfrom PIL import Imagemodel, _, transform = open_clip.create_model_and_transforms(model_name="coca_ViT-L-14",pretrained=

BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
BLIP2——采用Q-Former融合视觉语义与LLM能力的方法 FesianXu 20240202 at Baidu Search Team 前言 大规模语言模型(Large Language Model,LLM)是当前的当红炸子鸡,展现出了强大的逻辑推理,语义理解能力,而视觉作为人类最为主要的感知世界的手段,亟待和LLM进行融合,形成多模态大规模语言模型(Multimodal L

VLM 系列——BLIP2——论文解读
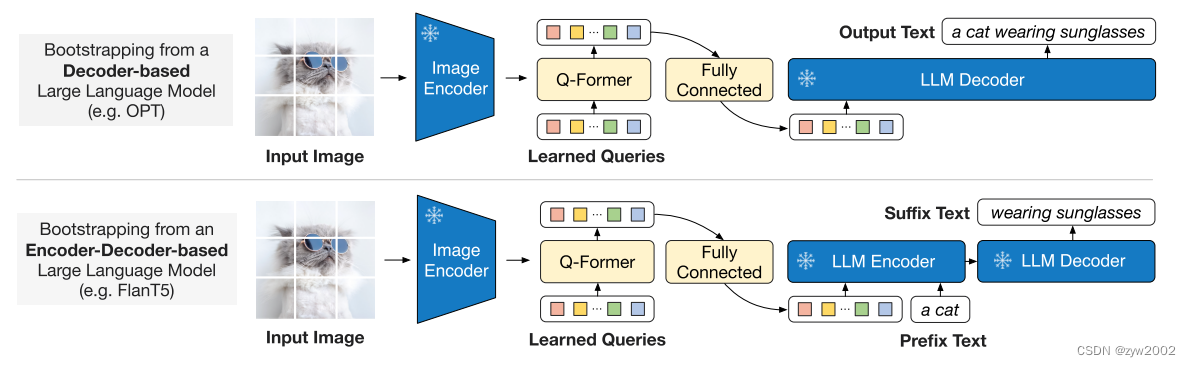
一、概述 1、是什么 BLIP2 全称《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models 》, 是一个多模态视觉-文本大语言模型,隶属BLIP系列第二篇,可以完成:图像描述、视觉问答、名画名人等识别(问答、描述)。支持单幅图片输
使用blip2进行图片输入文本输出
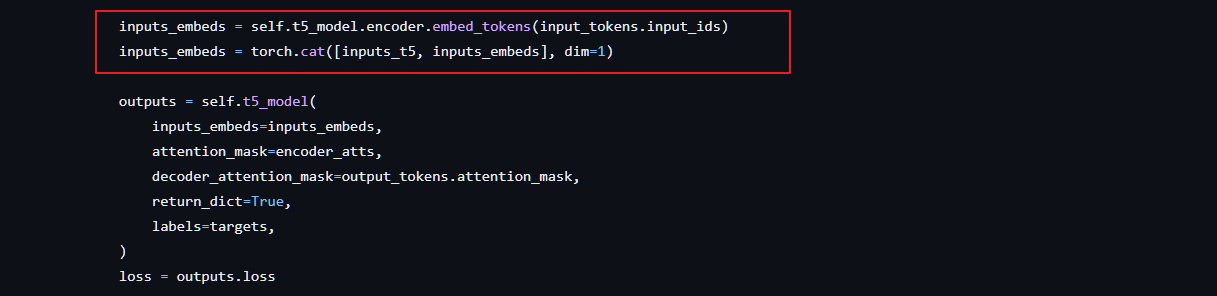
多模态的重要模型blip2,官方提供模型可以直接用来图片生成文本 github地址:https://github.com/salesforce/LAVIS/tree/main/projects/blip2 个人相当于跑了一下blip2的demo,记录下过程,供今后需要参考: 1、首先是环境安装,跟着官网走:https://github.com/salesforce/LAVIS/tree/7f00
BLIP2中Q-former详解
简介 Querying Transformer,在冻结的视觉模型和大语言模型间进行视觉-语言对齐。 为了使Q-Former的学习达到两个目标: 学习到和文本最相关的视觉表示。 这种表示能够为大语言模型所解释。 需要在Q-Former结构设计和训练策略上下功夫。具体来说, Q-Former是一个轻量级的transformer,它使用一个可学习的query向量集,从冻结的视觉模型提取
BLIP2模型加载在不同设备上
背景 现在大语言模型越来越大,占用的内存越来越多,这导致内存较小的设备无法体验大模型的效果。transformer提供了将一个大模型分别加载在gpu和cpu上的方法。 加载方法 以多模态模型BLIP2为例,将其语言模型放在gpu上,其余部分放在cpu上。配置加载预加载模型的device_map.device_map可以设置为auto,则根据设备的显存情况,自动加载在gpu或者cpu上。使用B