bgd专题

【ShuQiHere】SGD vs BGD:搞清楚它们的区别和适用场景
【ShuQiHere】 在机器学习中,优化模型是构建准确预测模型的关键步骤。优化算法帮助我们调整模型的参数,使其更好地拟合训练数据,减少预测误差。在众多优化算法中,梯度下降法 是一种最为常见且有效的手段。 梯度下降法主要有两种变体:批量梯度下降(Batch Gradient Descent, BGD) 和 随机梯度下降(Stochastic Gradient Descent, SGD)。这两者
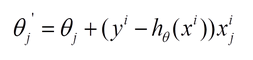
梯度下降、随机梯度下降(SGD)、批量梯度下降(BGD)的对比
转载自:http://blog.csdn.net/lilyth_lilyth/article/details/8973972 梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种不同的迭代求解思路,下面从公式和实现的角度对两者进行分析。 下面的h(x)是要拟合的函数,J(theta)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟

人工智能基础_机器学习014_BGD批量梯度下降公式更新_进一步推导_SGD随机梯度下降和MBGD小批量梯度下降公式进一步推导---人工智能工作笔记0054
然后我们先来看BGD批量梯度下降,可以看到这里,其实这个公式来源于 梯度下降的公式对吧,其实就是对原始梯度下降公式求偏导以后的梯度下降公式,然后 使用所有样本进行梯度下降得来的,可以看到* 1/n 其实就是求了一个平均数对吧.所有样本的平均数. 然后我们看,我们这里* 1/n那么前面还有一个eta ,对吧,那么这个1/n是个常量对吧,我们下面 就和eta进行了合并,可以看到,这里的

人工智能基础_机器学习016_BGD批量梯度下降求解多元一次方程_使用SGD随机梯度下降计算一元一次方程---人工智能工作笔记0056
然后上面我们用BGD计算了一元一次方程,那么现在我们使用BGD来进行计算多元一次方程 对多元一次方程进行批量梯度下降. import numpy as np X = np.random.rand(100,8) 首先因为是8元一次方程,我们要生成100行8列的X的数据对应x1到x8 w = np.random.randint(1,10,size = (8,1)) 然后我们生成8行1列的
机器学习(四):批量梯度下降法(BGD)、随机梯度下降法(SGD)和小批量梯度下降法(MBGD)
本文基于吴恩达老师的机器学习课程。看了吴恩达老师的机器学习课程,收获很多,想把课上学做的笔记结合自己的理解以及找到的一些资料综合起来做一个总结。大家感兴趣也可以自己去看一看吴恩达老师的课,这套课程,被公认为最好的机器学习的入门教程,下面是课程视频链接: 斯坦福大学公开课 :机器学习课程 上一篇博客机器学习(三):线性回归:梯度下降算法讲了用最小二乘法求得损失函数,再用梯度下降算法最小化损失函数
SGD、BGD以及负梯度
梯度下降举例子推导过程 https://www.jianshu.com/p/c7e642877b0e 是loss函数,对上一级的输入求导(可以是单变量的,也可以的是多变量的),然后输出是输入减去梯度 减去(负号)是因为求导是梯度上升最快的方向,减去就是下降最快的方向 一、梯度下降 对噪声数据的拟合函数 与真实值y之间的误差 (1)将J(theta)对theta求偏导,
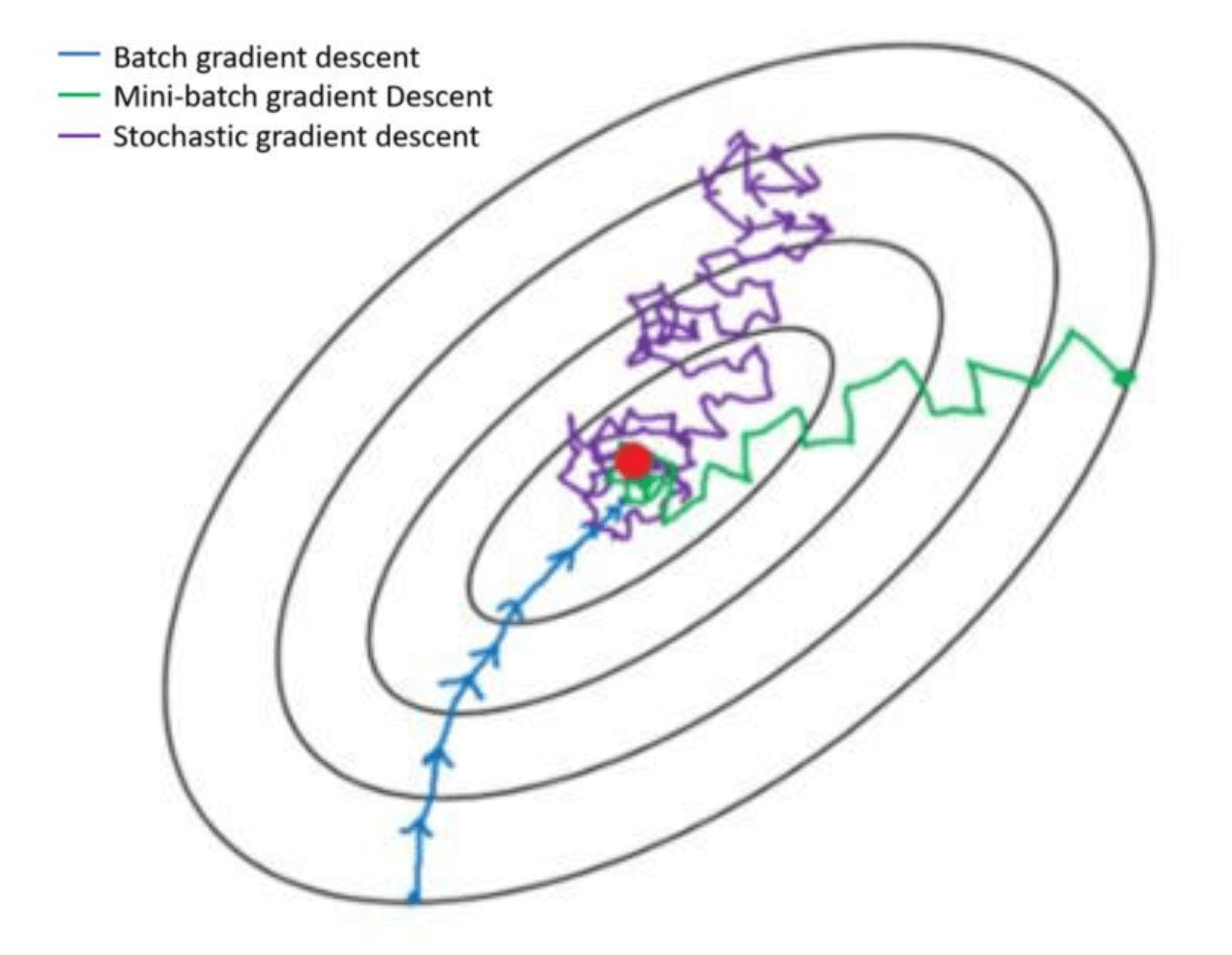
三种梯度下降算法的区别(BGD, SGD, MBGD)
前言 我们在训练网络的时候经常会设置 batch_size,这个 batch_size 究竟是做什么用的,一万张图的数据集,应该设置为多大呢,设置为 1、10、100 或者是 10000 究竟有什么区别呢? # 手写数字识别网络训练方法network.fit(train_images,train_labels,epochs=5,batch_size=128) 批量梯度下降(Batch G
几种优化算法的比较(BGD、SGD、Adam、RMSPROP)
1、BGD(Batch gradient descent) 梯度更新规则:BGD 采用整个训练集的数据来计算 cost function 对参数的梯度: 缺点:由于这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,遇到很大量的数据集也会非常棘手,而且不能投入新数据实时更新模型。 我们会事先定义一个迭代次数 epoch,首先计算梯度向量 params_grad,然后沿着梯

SGD BGD Adadelta等优化算法比较
在腾讯的笔试题中,作者遇到了这样一道题: 下面哪种方法对超参数不敏感: 1、SGD2、BGD3、Adadelta4、Momentum神经网络经典五大超参数:学习率(Learning Rate)、权值初始化(Weight Initialization)、网络层数(Layers)单层神经元数(Units)、正则惩罚项(Regularizer|Normalization)显然在这里超参数指的是事先指
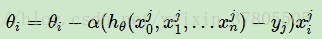
GD\BGD\SGD
在讨论GBDT前,先来看看什么是GD,BGD和SGD GD(Gradient Descent,梯度下降): 求损失函数最小值:梯度下降;求损失函数最大值:梯度上升。 假设线性模型: 其中θ是参数。 损失函数为: 那么每次GD的更新算法为: BGD(Batch Gradient Descent,批量梯度下降): 在更新参数时使用所有的样本来进行更新。 SGD(Sto

Batch Gradient Descendent (BGD) Stochastic Gradient Descendent (SGD)
SGD, BGD初步描述(原文来自:http://blog.csdn.net/lilyth_lilyth/article/details/8973972,@熊均达@SJTU 做出解释及说明) 梯度下降(GD)是最小化风险函数、损失函数(注意Risk Function和Cost Function在本文中其实指的一个意思,在不同应用领域里面可能叫法会有所不同。解释:@熊均达@SJTU)的
三种梯度下降算法的区别(BGD, SGD, MBGD)
前言 我们在训练网络的时候经常会设置 batch_size,这个 batch_size 究竟是做什么用的,一万张图的数据集,应该设置为多大呢,设置为 1、10、100 或者是 10000 究竟有什么区别呢? # 手写数字识别网络训练方法network.fit(train_images,train_labels,epochs=5,batch_size=128) 批量梯度下降(Batch G