asr专题

ASR-语音预处理(二):时域转频域
文章目录 一.时域转频域二.代码:三.程序输出: 一.时域转频域 这节主要介绍如何经过傅里叶变换将音频转到频域,以便于后续的特征提取和识别。先后进行加窗、分帧、FFT和取log操作。 输入:音频矩阵wavsignal ,帧率fs 例:[[1507 1374 1218 … -78 -127 -43]],16000 输出:转成频域后的音频矩阵data_input 二.代码:
ASR-语音预处理(一):音频读取
文章目录 一.音频读取二.代码:三.程序输出: 一.音频读取 这是语音识别系列的第一篇博文,主要介绍音频如何读取以及如何转成矩阵形式。 输入:wav文件 例:A2_1.wav 输出:输入的wav文件所对应的数据矩阵wave_data和帧率framerate。 例:[[1507 1374 1218 … -78 -127 -43]] ,16000 二.代码: #coding

ASR-声学特征提取
文章目录 方法一:MFCC特征提取step 1:A/D转换(采样)step 2:预加重step 3:加窗分帧step 4:DFT+取平方step 5:Mel滤波step 6:取对数step 7:IDFTstep 8:动态特征 方法二:深度学习特征提取step 1:采样step 2:分帧step 3:傅里叶变换step 4:识别字符step 5:获取映射图 方法一:MFCC特征提

ASR-MFCC特征的物理意义
文章目录 一.MFCC简介二.MFCC特征提取过程三.MFCC的物理含义 一.MFCC简介 梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,简称MFCC)是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示: 式中f为频率,单位为Hz。下图展示了Mel频率与线性频率的关系

IEEE T-ASLP | 利用ASR预训练的Conformer模型通过迁移学习和知识蒸馏进行说话人验证
近期,昆山杜克大学在语音旗舰期刊 IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)上发表了一篇题为“Leveraging ASR Pretrained Conformers for Speaker Verification Through Transfer Learning and Knowledge Di

微软发布 Phi-3.5 系列模型,涵盖端侧、多模态、MOE;字节 Seed-ASR:自动识别多语言丨 RTE 开发者日报
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@SSN,@鲍勃 01 有话题的新闻
手把手教学!新一代 Kaldi: TTS Runtime ASR 实时本地语音识别 语音合成来啦
简介 本文向大家介绍如何在新一代 Kaldi的部署框架 **sherpa-onnx**中使用 TTS。 注:sherpa-onnx 提供的是一个TTS runtime, 即部署环境。它并不支持模型训练。 本文使用的测试模型,都是来源于网上开源的 VITS 预训练模型。 我们提供了 ONNX 导出的支持。如果你也有 VITS 预训练模型,欢迎尝试使用 sherpa-onnx 进行部署。

顶顶通呼叫中心中间件-asr录音路径修改(mod_cti基于FreeSWITCH)
顶顶通呼叫中心中间件-asr录音路径修改(mod_cti基于FreeSWITCH) 录音路径模板。如果不是绝对路径,会把这个路径追加到FreeSWITCH的recordings后面。支持变量,比如日期 ${strftime(%Y-%m-%d)}。最后一个录音文件路径会保存到变量 ${cti_asr_last_record_filename} 一、机器人话术编辑器修改asr录音路径 1、全局修
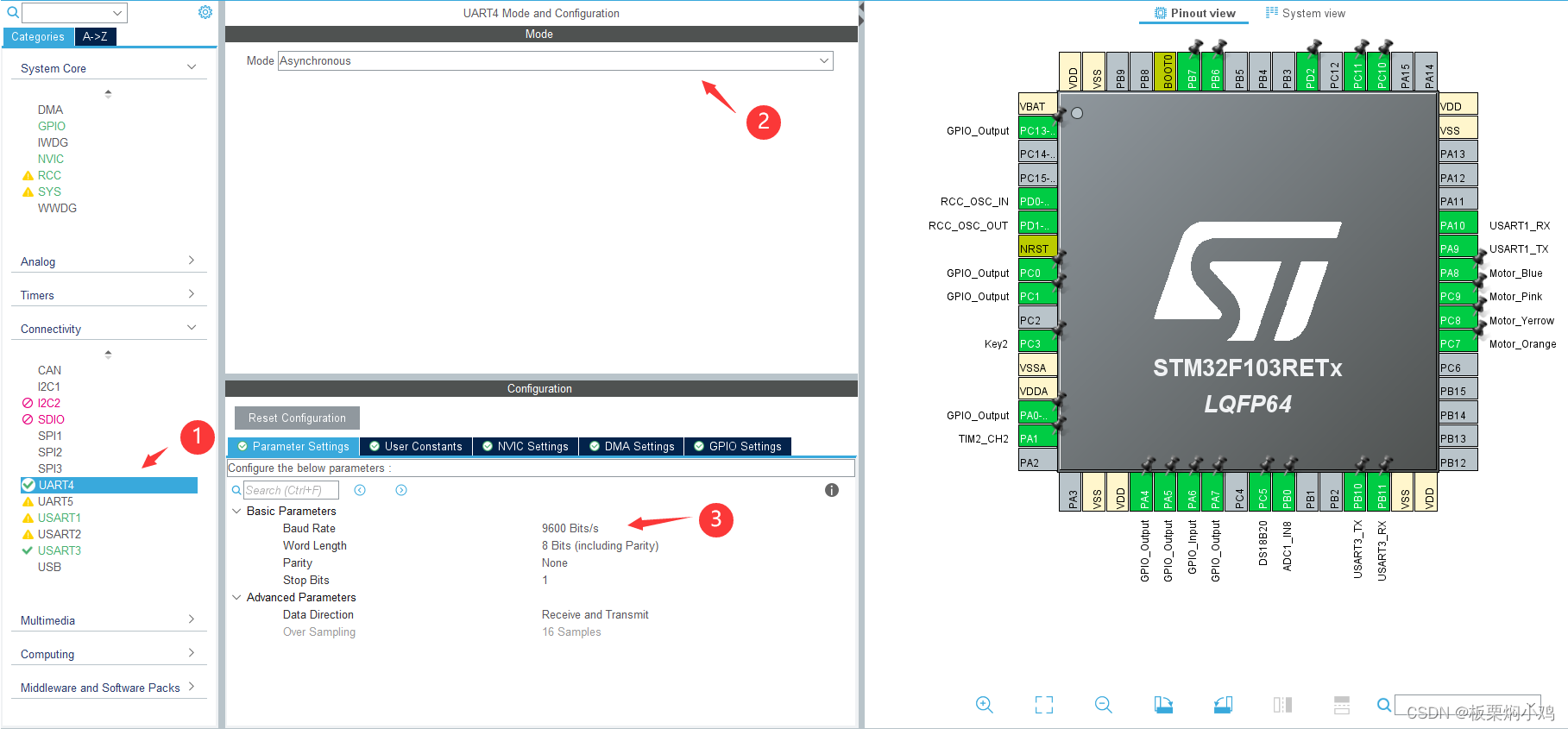
手把手从0到1教你做STM32+FreeRTOS智能家居--第10篇之ASR-PRO语音识别模块
前言 先看实验效果,通过ASR-PRO语音智能识别控制模块,来控制STM32单片机实现对应的控制功能。因为后台好多小伙伴私信问用的是什么语音模块,并且很少在网上看到如何使用此模块相关的文章,所以我将会在本篇文章详细介绍一下此模块相关的信息和具体的操作流程和应用代码。 stm32语言识别 一、硬件设计 本篇文章用到的语音识别模块是信泰微电子的ASR-PRO语音智能识别模块,有需要

ASR语音转录Prompt优化
ASR语音转录Prompt优化 一、前言 在ASR转录的时候,我们能很明显的感受到有时候语音识别不是很准确,这过程中常见的文本错误主要可以归纳为以下几类: 同音错误(Homophone Errors) 同音错误发生在不同词语发音相似或相同的情况下。ASR系统可能难以区分这些词语的具体含义,从而导致错误的词语被识别。例如,中文里的“海”和“还”在某些方言或口音中发音相近,可能会被错误地互换。
中文语音识别实战(ASR)
写在前面的话 本博客主要介绍了 1. 语音识别基础知识 2. 中文语音识别数据集 3. 语音识别常用模型方法 4. 自己训练一个中文语音识别模型 主意: 代码中所涉及的模型及数据集,均可从huggingface下载得到,代码中的路劲,需要根据自身实际情况稍做调整。 目录 语音识别基础 数据集 模型 wav2vec whipser 训练代码 工具代码 推理代码
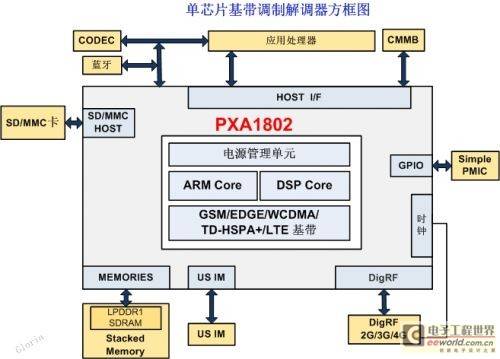
ASR 1802就是Marvell PXA 1802吗?找一篇资料参照一下
ASR 1802就是Marvell PXA 1802吗?我找一篇资料参照一下 Marvell PXA 1802 LTE多模单芯片完全解密 原文连接:http://news.eeworld.com.cn/xfdz/2012/1019/article_16243.html 移动通信进入LTE(长期演进)时代,必然带来技术上的创新。LTE技术的采用,能提升频谱效率,使用户享用超高数据率
ASR工业化语音模型总结
1、wenet模型:WeNet语音识别实战-CSDN博客 git地址:GitHub - wenet-e2e/wenet: Production First and Production Ready End-to-End Speech Recognition Toolkit 生产应用方式为:使用pytorch训练,使用c++部署。

自动语音识别技术(ASR)在聋哑儿童计算机辅助教学中的开发与应用
自动语音识别技术(ASR)在聋哑儿童计算机辅助教学中的开发与应用 RDTE OF CAI FOR THE DEAF&DUMB CHILDREN BASED ON ASR 一、 课题来源及研究的目的和意义; 据有关机构抽样调查,我国有残疾人约6000万,其中聋哑人约有1300万,18岁以下应受教育的聋哑人约达100万,这是一个庞大的弱势群体。他们在学习
通过串口中断的方式进行ASR-01S模块与STM32通信(问题与解决)
前言: 最近在做一个智能家居的项目,需要实现语音控制的功能,于是我选用了ASR-01S模块与STM32通信,这个模块最大的好处在于有配套的编程软件和语音库,不用自己训练且编程简单(少儿编程的程度)。ASR-01S的代码架构在这不多说,总之在收到语音后它会通过串口发送一串命令给STM32,STM32收到后通过串口中断的方式进行一系列操作。但没想到在这块看起来很简单的地方翻车了(太丢人了。。。),经
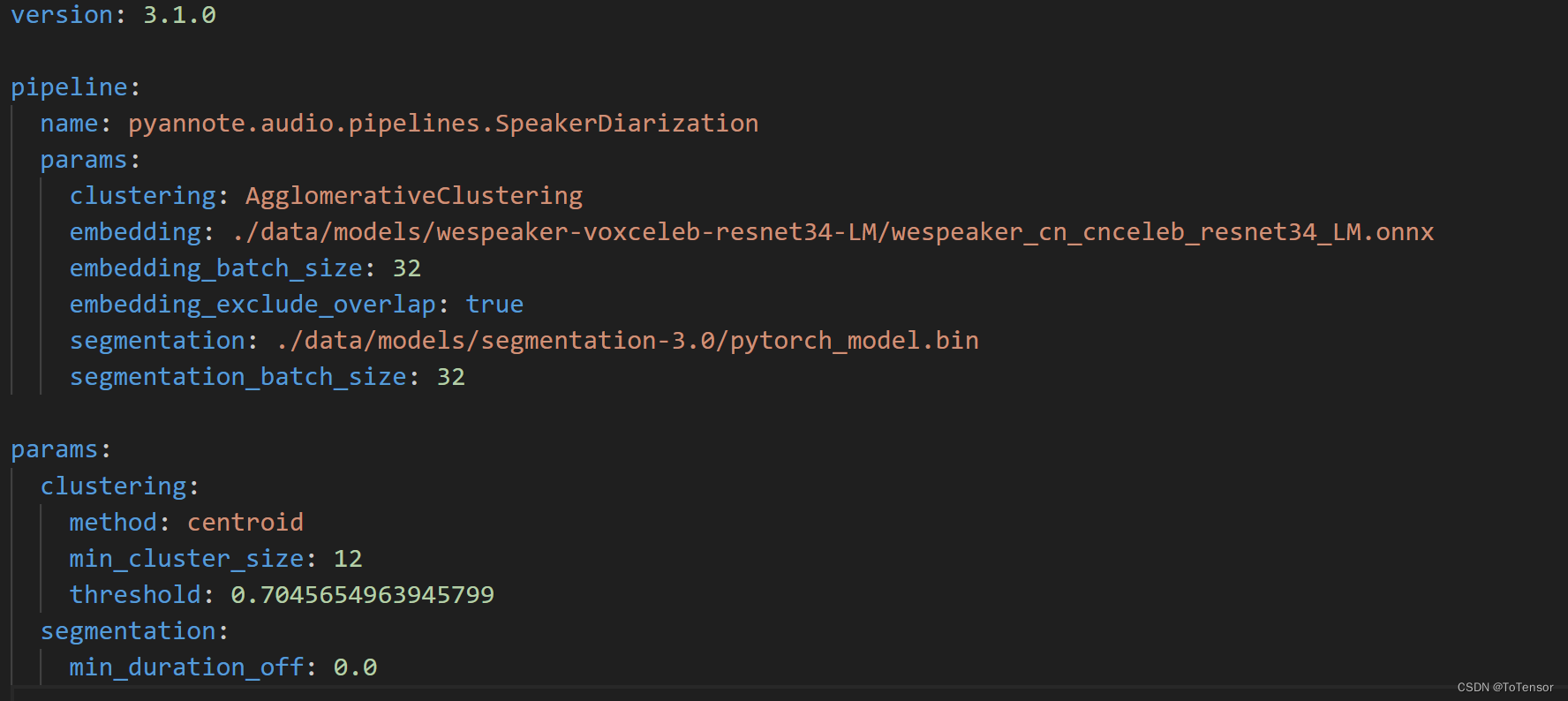
Fastwhisper + Pyannote 实现 ASR + 说话者识别
文章目录 前言一、faster-whisper简单介绍二、pyannote.audio介绍三、faster-whisper + pyannote.audio 实现语者识别四、多说几句 前言 最近在研究ASR相关的业务,也是调研了不少模型,踩了不少坑,ASR这块,目前中文普通话效果最好的应该是阿里的modelscope上的中文模型了,英文的话,还是非whisper莫属了,而且w

FreeSWITCH源码分析和分享之ASR解析
asr_interface的工作流程 调用detect_speech这个APP,FreeSWITCH的核心代码中会注册ASR的监听(bugging)处理,并注册监听回调函数。 一、监听回调函数初始化时启动 创建一个线程A。A线程主要是处理识别结果。 在线程中可以看到,只要channel没有销毁,呼叫状态没有进入CS_HANGUP状态,就会执行一个死循环,等待条件变量被唤醒。 当条件变量被唤
【正在更新】从零开始认识语音识别:DNN-HMM混合系统语音识别(ASR)原理
摘要 | Abstract TO-BE-FILLED 1.前言 | Introduction 近期想深入了解语音识别(ASR)中隐马尔可夫模型(HMM)和深度神经网络-隐马尔可夫(DNN-HMM)混合模型,但是尽管网络上有许多关于DNN-HMM的介绍,如李宏毅教授的《深度学习人类语言处理》[1],一些博主的语音识别系列文章[2],斯坦福大学HMM课件[3]。但

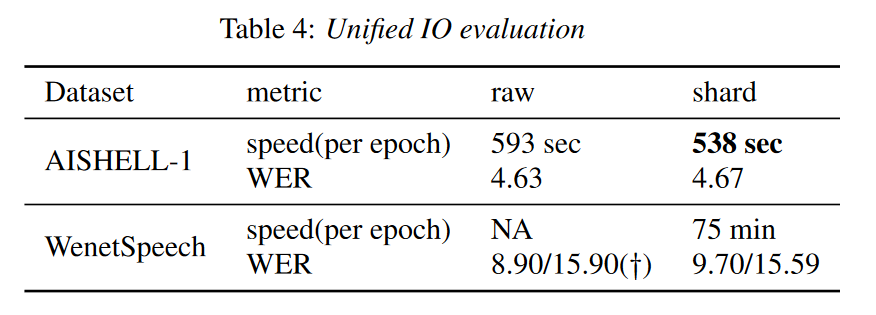
WeNet2.0:提高端到端ASR的生产力
摘要 最近,我们提供了 WeNet [1],这是一个面向生产(=工业生产环境需求)的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时(built-in runtime)来处理流式和非流式解码模式。 为了进一步提高 ASR 性能并满足各种生产需求,在本文中,我们介绍了 WeNet 2.0 的四个重要更新。 我们提出了 U2++,这是一个具有双
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理
Unity 工具 之 Azure 微软连续语音识别ASR的简单整理 目录 Unity 工具 之 Azure 微软连续语音识别ASR的简单整理 一、简单介绍 二、实现原理 三、注意实现 四、实现步骤 五、关键脚本 一、简单介绍 Unity 工具类,自己整理的一些游戏开发可能用到的模块,单独独立使用,方便游戏开发。 本节介绍,这里在使用微软的Azure 进行语音合成的

音频深度学习变得简单:自动语音识别 (ASR),它是如何工作的
一、说明 在过去的几年里,随着Google Home,Amazon Echo,Siri,Cortana等的普及,语音助手已经无处不在。这些是自动语音识别 (ASR) 最著名的示例。此类应用程序从某种语言的语音音频剪辑开始,并将说出的单词提取为文本。因此,它们也称为语音转文本算法。 当然,像Siri和上面提到的其他应用程序,走得更远。他们不仅提取文本,
Jetson Orin安装riva以及llamaspeak,使用 Riva ASR/TTS 与 Llama 进行实时交谈,大语言模型成功运行笔记
NVIDIA 的综合语音 AI 工具包 RIVA 可以处理这种情况。此外,RIVA 可以构建应用程序,在本地设备(如 NVIDIA Jetson)上处理所有这些内容。 RIVA 是一个综合性库,包括: 自动语音识别 (ASR)文本转语音合成 (TTS)神经机器翻译 (NMT)(语言到语言的翻译,例如英语到西班牙语)自然语言处理 (NLP) 服务的集合,例如命名实体识别 (NER)、标点符号和意
语音asr是什么意思_ASR的完整形式是什么?
语音asr是什么意思 ASR:自动语音识别 (ASR: Automated Speech Recognition) ASR stands for Automated Speech Recognition. With the help of this technology, spoken words can be easily converted to written text. What ac