本文主要是介绍isscc2024 short course2 Performance Compute Environment,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这部分分为4部分:
概览:LLMs和生成式AI

探讨大语言模型(LLMs)和生成式AI的整体环境,及其对硬件加速器设计的影响。
高性能AI加速器的特定考虑因素
广泛的模型和使用案例支持:需要设计能支持多种模型和应用场景的加速器。
系统级优化:强调从系统层面进行优化以提升整体性能。
计算效率的路线图
量化与稀疏性:探讨量化(Quantization)和稀疏性(Sparsity)技术如何提高计算效率。
功率管理:通过优化功率管理来提高性能和能效。
混合信号/模拟计算:探讨混合信号和模拟计算方法在提高计算效率方面的潜力。
通信带宽的路线图
核内、核间、DRAM和加速器间的通信:分析不同层次的通信需求和优化方法。
1. Landscape: LLMs and Generative AI

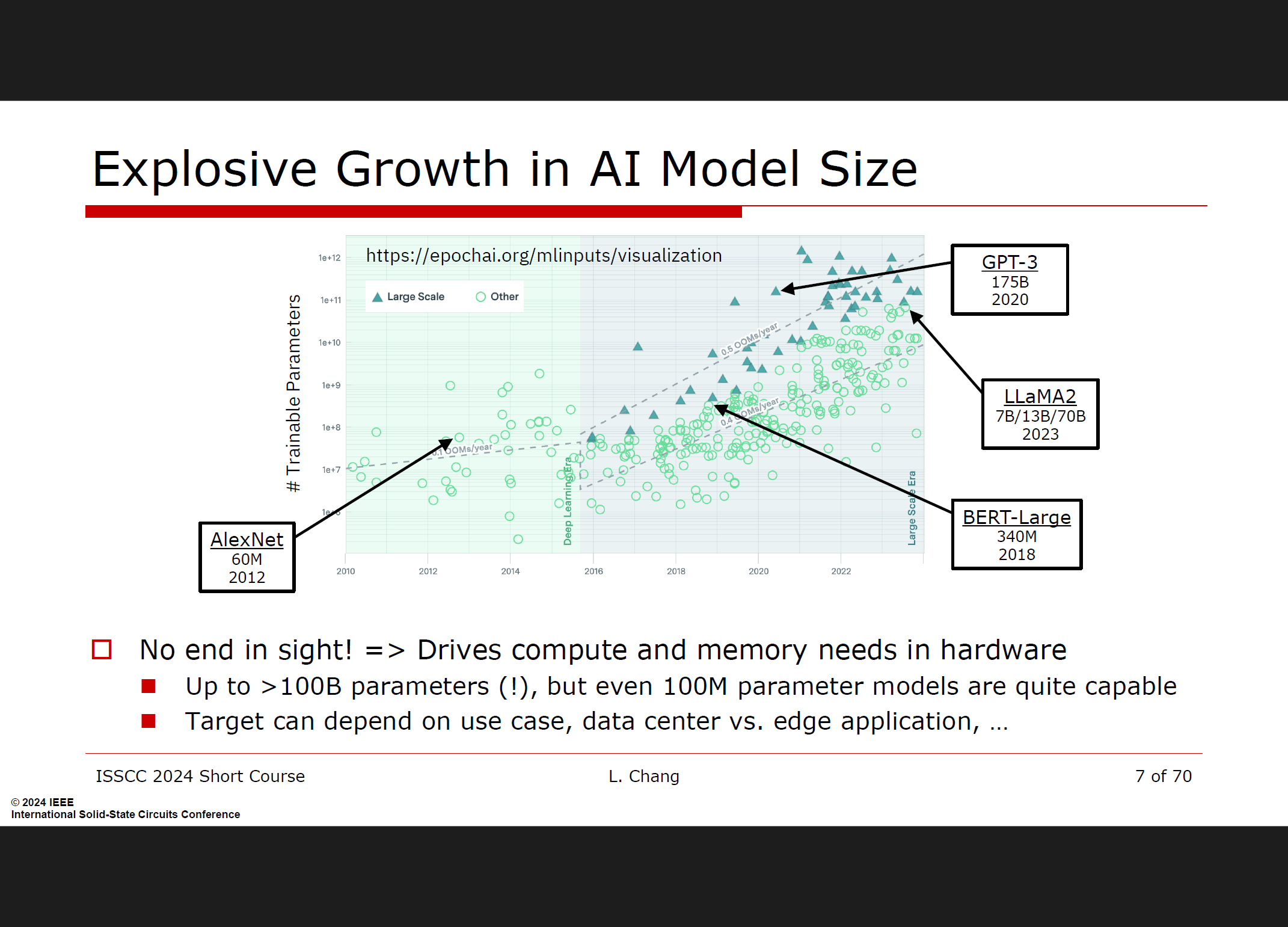
2.Specific considerations for high performance AI accelerators
广泛的模型/用例支持
高性能AI加速器需要支持各种不同的模型和用例,以适应多样化的应用需求。这意味着加速器设计必须灵活,能够处理从卷积神经网络(CNNs)到大语言模型(LLMs)等不同类型的工作负载。

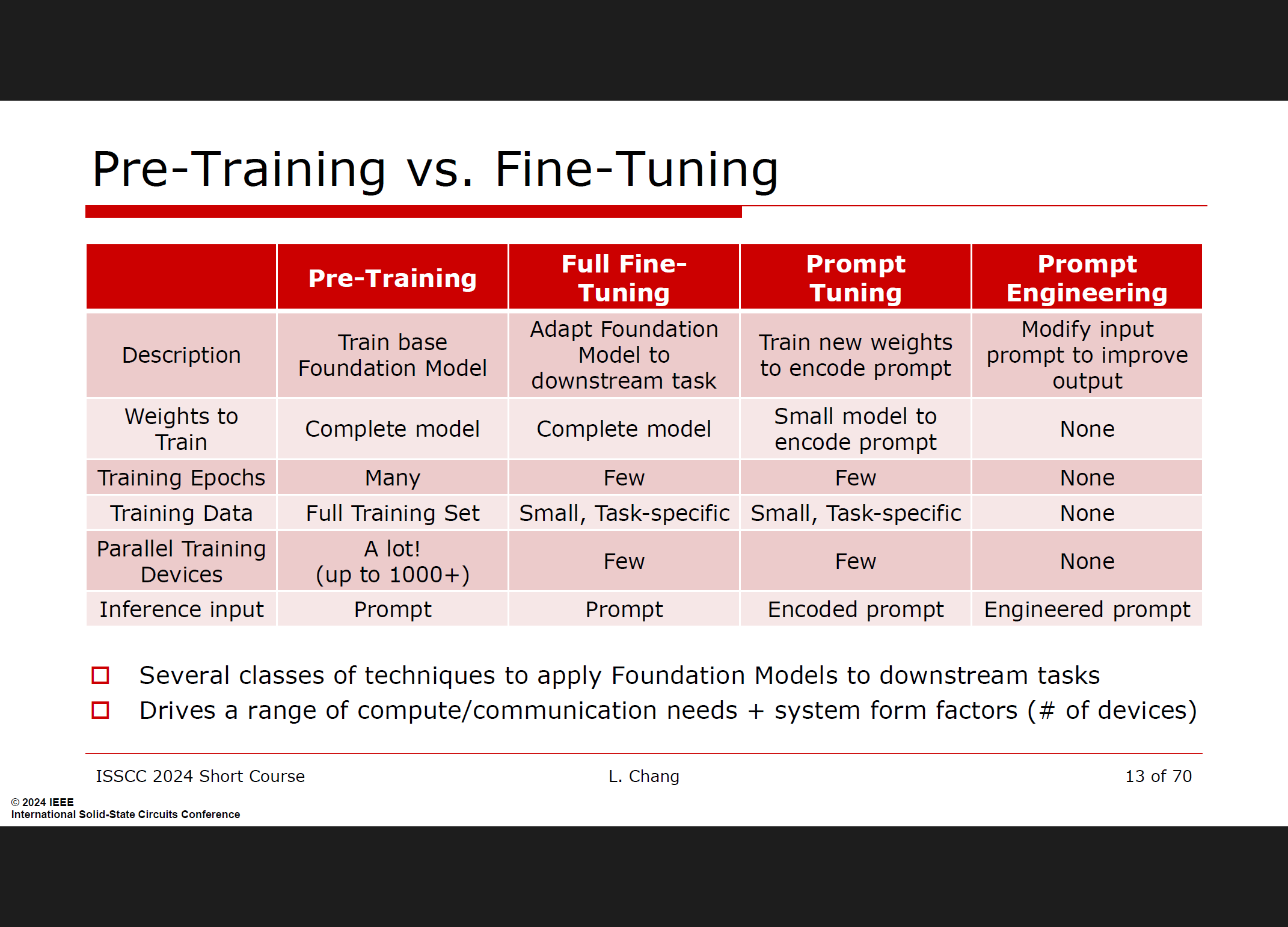

提示工程与数据库检索相结合
RAG技术的核心在于通过结合提示工程和数据库检索,来增强LLMs的能力。这一过程包括以下步骤:
提示工程:优化和设计输入提示,以最大化生成模型的输出质量。
数据库检索:从数据库中检索相关信息,并将这些信息注入到生成模型的提示中,以增强模型在生成新内容时的知识基础。
通过这种结合,RAG能够有效地利用外部数据库的最新信息,补充模型在预训练阶段可能未包含的数据,从而提升模型的响应准确性和相关性。
硬件需求与挑战
实现RAG需要AI系统具备高效的数据库管理能力,这对硬件提出了新的要求:
数据库处理:系统需要高效的数据库访问和管理能力,以便快速检索和处理大规模数据。
通信架构:为支持数据库与生成模型之间的高效通信,硬件设计必须考虑低延迟和高带宽的通信架构。
存储管理:大规模数据库的存储管理需要优化,以确保数据检索的快速和高效。
系统级优化
优化不仅限于单个硬件组件,还必须考虑整个系统的优化。这包括硬件与软件的协同设计,通过系统级的调整来提高整体性能和效率。例如,数据的有效传输和存储、计算资源的高效调度等都是系统级优化的重要方面。
计算效率的路线图
量化与稀疏性:通过减少计算精度(量化)和利用稀疏性来提高计算效率。这些技术可以显著减少计算资源的需求,同时保持模型性能。
功率管理:优化功耗是提高计算效率的关键,通过先进的电路设计和功率管理技术来减少能耗。
混合信号/模拟计算:采用混合信号和模拟计算方法可以进一步提高计算效率,尤其是在特定应用场景下。
通信带宽的路线图
为了实现高性能计算,加速器需要高效的通信架构,以支持不同层次的通信需求,包括核内通信、核间通信、DRAM通信和加速器间通信。优化这些通信路径可以显著提高系统的整体性能和可扩展性。
总结
为了实现高性能AI加速器,设计需要考虑广泛的模型支持、系统级优化、计算效率和通信带宽等多方面因素。这些考虑因素共同作用,帮助克服单芯片性能的限制,实现更大规模、更高效的计算能力。
3.Roadmap: Compute efficiency
在高性能AI加速器的架构和设计方法中,计算效率的规划是关键部分,涉及以下几个方面:
量化与稀疏性
量化:通过减少计算精度,可以显著提升AI性能。具体方法包括将训练的浮点精度从fp32降低到bfloat16,甚至是fp8;推理中使用fp16和int8,并逐步向int4发展。

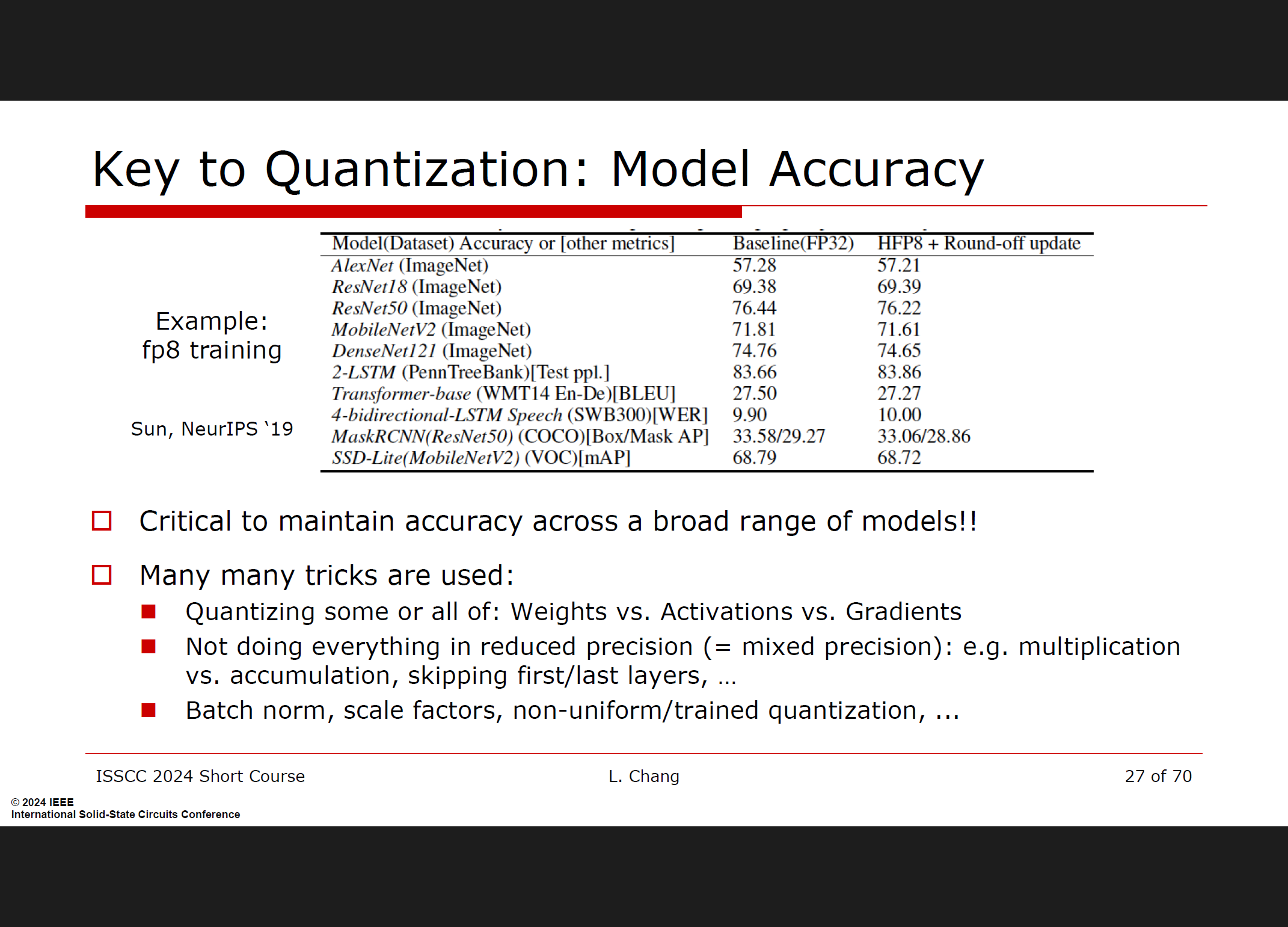
稀疏性:利用模型中的稀疏性可以减少计算和存储需求,从而提高效率。


电源管理
电源管理技术对于优化计算性能和能效至关重要。有效的电源管理可以在不牺牲性能的情况下,显著降低功耗,提高计算密度。
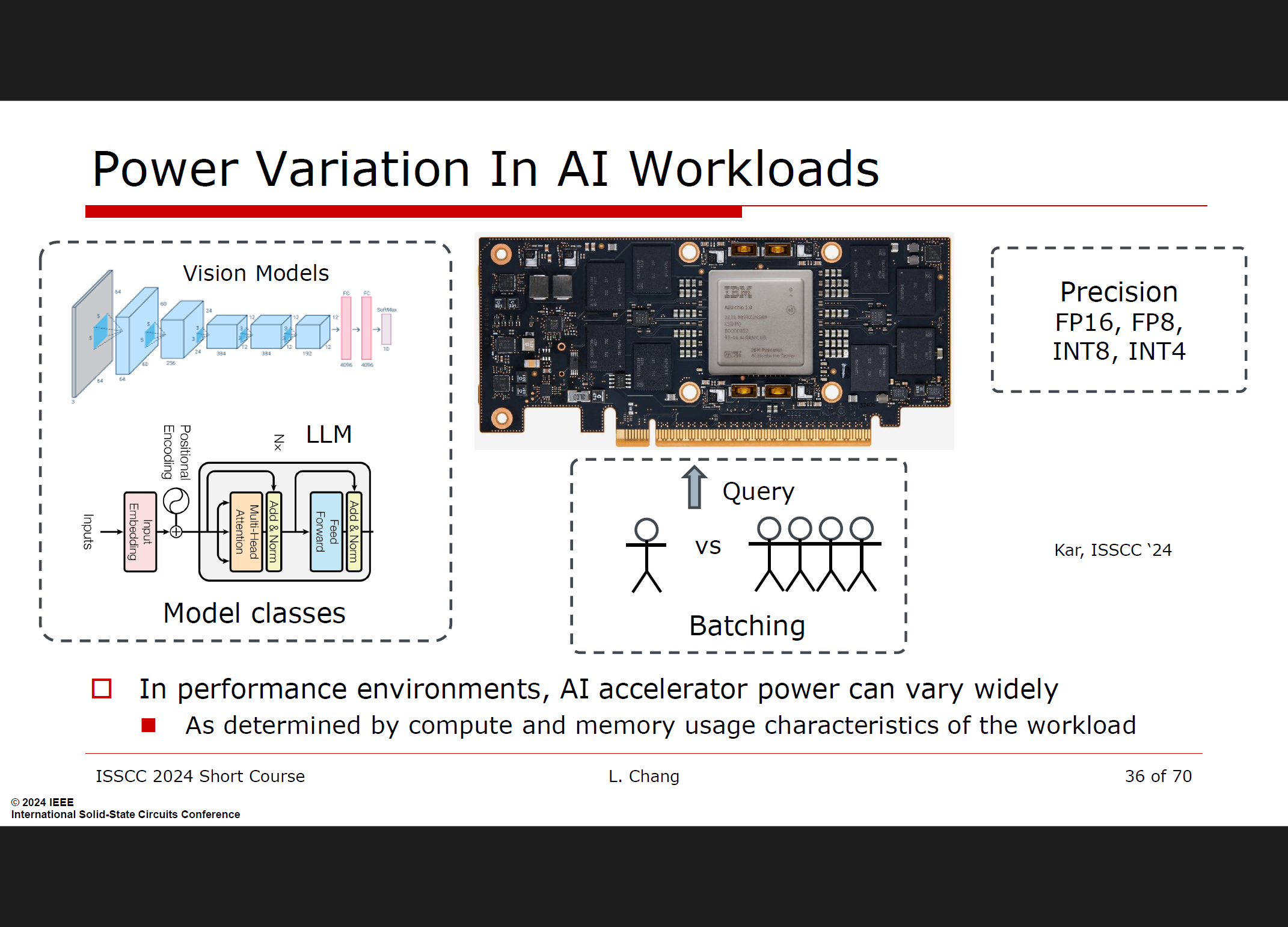

混合信号/模拟计算
混合信号和模拟计算技术有潜力大幅提升计算效率和能效。通过这些技术,可以在不增加过多数字电路复杂度的情况下,达到更高的性能和能效比。比如通过存内计算等新型计算方式。

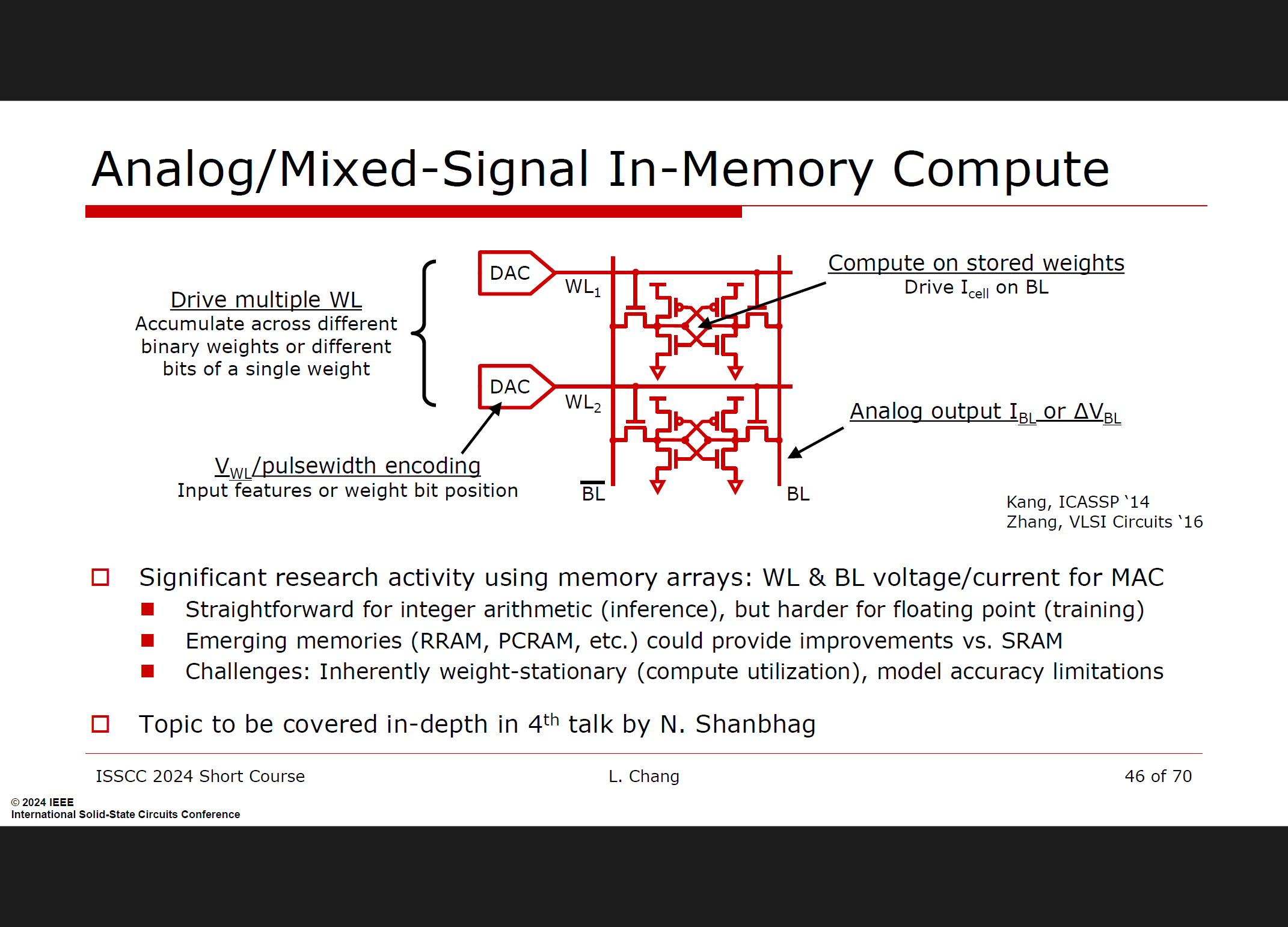
计算效率工作方向
密集矩阵乘法:作为AI计算的核心,重点在于提高计算引擎的功率和性能。
广泛模型与操作支持:优化不同模型和操作的计算效率,包括传统机器学习模型和大规模语言模型(LLMs)。
电源管理:积极的电路技术在电源管理中发挥重要作用。
混合信号/模拟计算:未来创新需要跨越传统硬件和软件的边界进行互动。
量化技术的关键点
模型精度:在不同模型中保持高精度至关重要。采用多种量化技巧,如仅量化权重或激活、混合精度计算等,以确保模型在量化后的准确性。
量化示例
训练量化:例如,将训练的浮点精度降低到fp8,以提高训练效率和内存利用率。
结论
AI计算效率的提升需要在量化、稀疏性、电源管理和混合信号计算等方面进行系统级优化。未来的创新需要跨越传统硬件和软件的边界,以实现高性能和高效能的AI计算
4.Roadmap: Communication bandwidth
-
通信带宽的重要性:随着人工智能模型的不断增长,对计算和内存的需求也在迅速增加。这就需要硬件加速器之间以及与主存储器(DRAM)之间有高效的通信带宽来支持这些需求。

-
通信层次:通信带宽的路线图被分为几个层次,从核心内部的通信(Within core)到核心之间的通信(Core-to-core),再到与动态随机存取存储器(DRAM)的通信,最后是加速器之间的通信(Accelerator-to-accelerator)。


-
核心内部通信:为了提高计算效率,核心内部的通信需要被优化,以减少数据传输的延迟和提高数据传输的带宽。

-
核心间通信:随着系统规模的扩大,核心间通信也变得重要。这要求有高效的互连技术来支持不同处理器核心之间的数据交换。

-
与DRAM的通信:由于机器学习模型通常需要大量的数据存储和访问,因此与DRAM的通信带宽成为了一个关键因素。需要有足够的带宽来支持快速的数据读取和写入操作。

-
加速器间通信:在分布式系统中,多个硬件加速器需要协同工作。因此,加速器之间的通信带宽也非常重要,它影响着整个系统的性能和扩展能力。
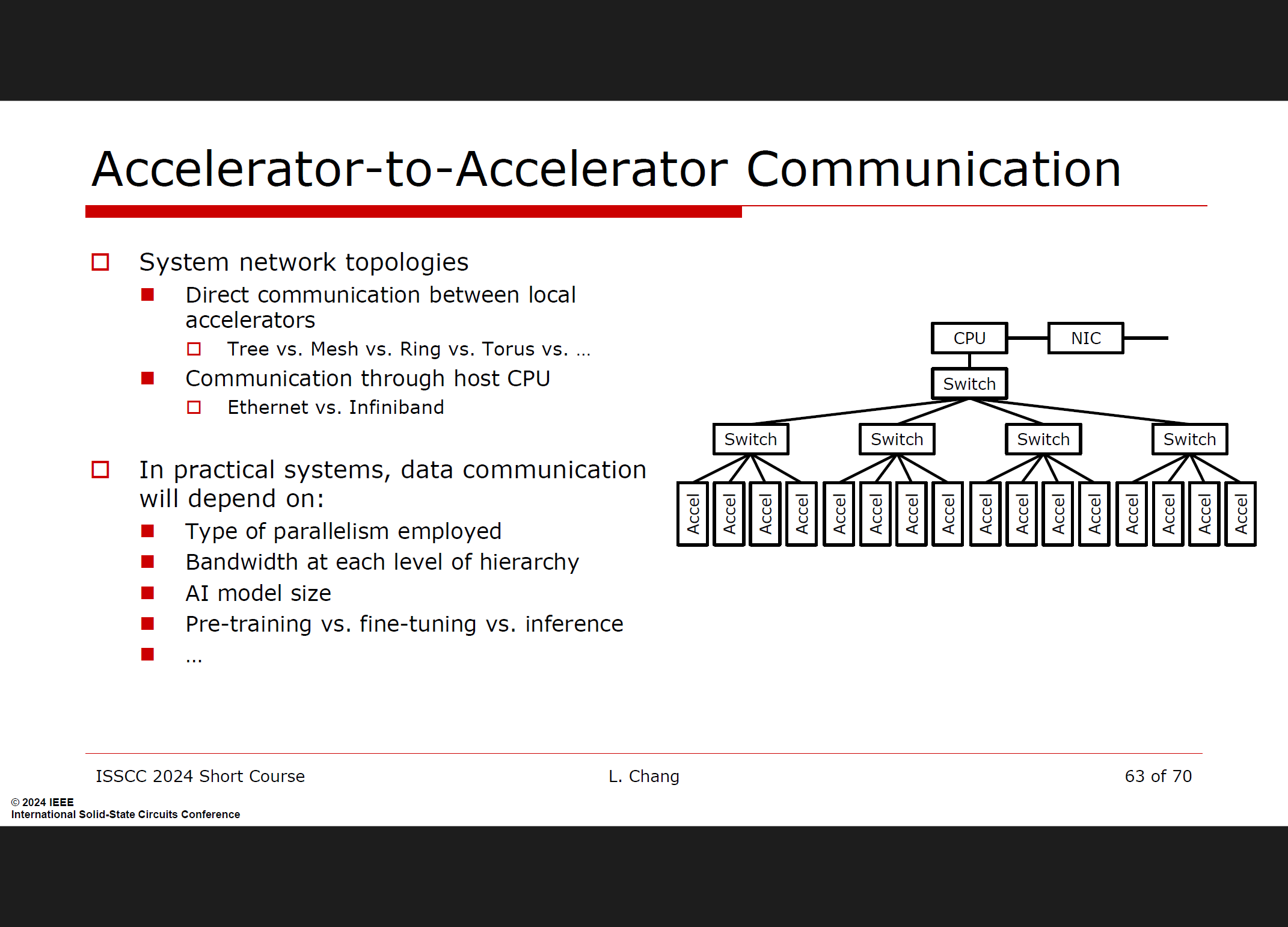
-
系统级优化:为了实现高性能的AI加速器,需要在系统级别上对通信带宽进行优化。这包括选择合适的网络拓扑结构、通信协议以及数据传输机制。

-
未来发展:随着AI模型的持续增长和新的AI技术的出现,通信带宽的需求将会继续增加。因此,未来的硬件设计需要考虑更高的通信带宽和更高效的数据传输技术。需要在封装等层级进行优化。
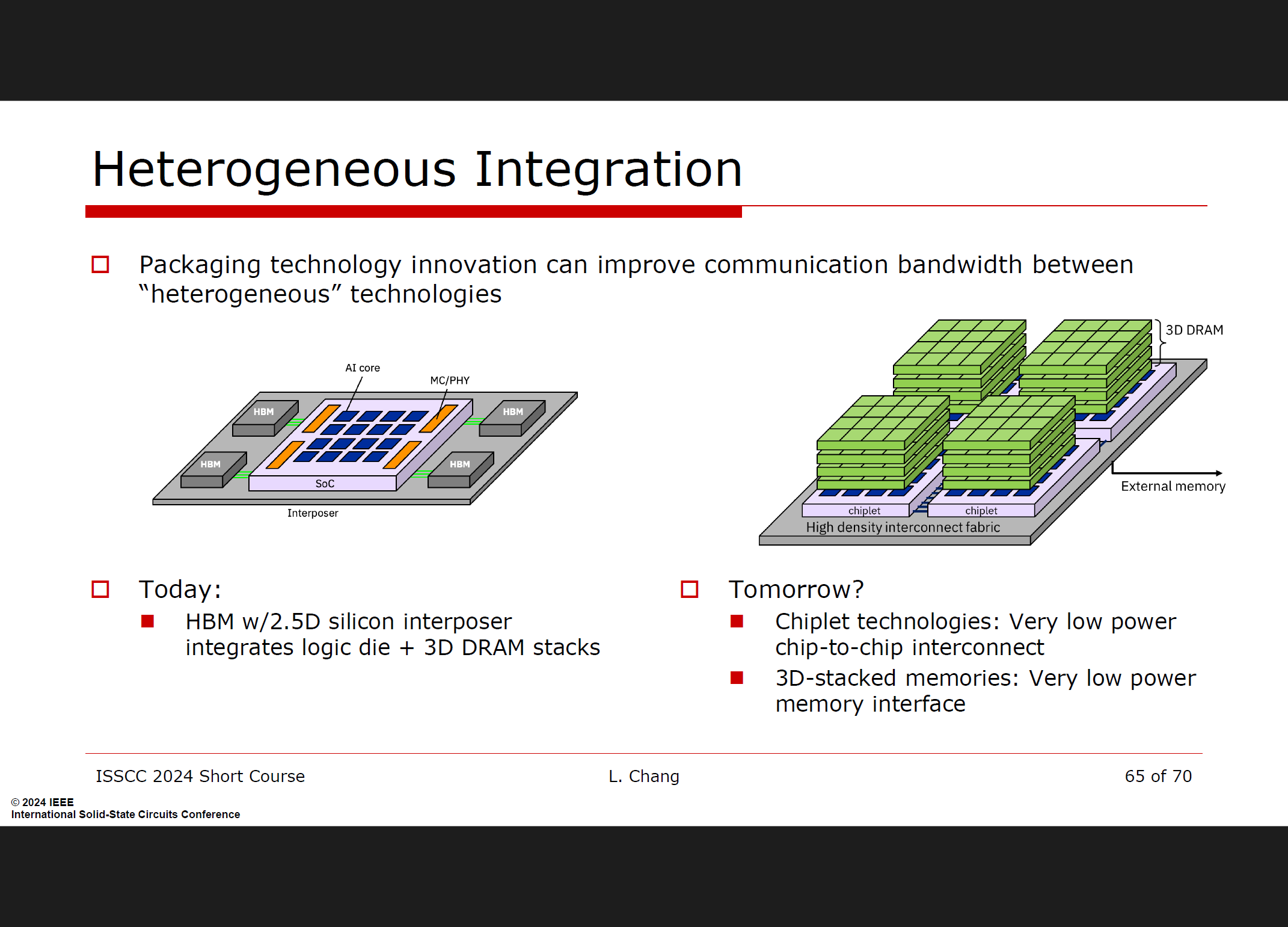
总的来说,通信带宽在高性能计算环境中对于机器学习硬件加速器的性能至关重要。需要从系统级别对不同层次的通信带宽进行优化,以支持不断增长的AI模型和计算需求。
这篇关于isscc2024 short course2 Performance Compute Environment的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[LeetCode] 820. Short Encoding of Words](/front/images/it_default.gif)

