本文主要是介绍Ceph集群RBD块存储:快照与Copy-on-Write克隆的基本操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.RBD块存储镜像克隆概念
- 2.copy-on-write克隆的基本使用
- 2.1.在块存储中创建一个快照
- 2.2.将快照配置成保护模式
- 2.3.基于快照克隆出镜像
- 2.4.使用克隆的镜像
- 2.5.查看一个快照下有哪些克隆的镜像
1.RBD块存储镜像克隆概念
镜像克隆官方文档:https://docs.ceph.com/en/pacific/rbd/rbd-snapshot/#getting-started-with-layering
像阿里云、OpenStack等等虚拟化平台,创建一个虚拟机的速度都非常的快,这个原理就和RBD块存储的镜像克隆有关,这个机制叫做copy-on-write,简称COW。
copy-on-write机制其实就是将一个快照快速克隆成了一个写时复制镜像,快照是只读的,写数据都是在克隆的镜像里进行的,使用这个克隆的镜像就可以快速创建出虚拟机。
镜像克隆分为完整克隆和链接克隆两种,完整克隆的速度比较慢 ,链接克隆的速度非常快,相当于Windows中的快捷方式。
链接克隆是基于父镜像(快照)中快速创建出来的一个链接镜像(写时复制镜像),链接镜像读取数据是从父镜像中进行的,写数据是在链接镜像中进行的,通过链接克隆可以快速的克隆出很多个镜像,并行这些镜像都可以直接使用。
链接镜像与父镜像存在依赖关系,一定要将父镜像保护好,如果父镜像丢失,就会导致链接镜像无法使用。
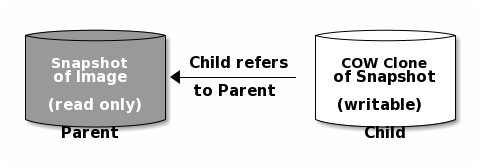
父镜像指的是块设备的快照,从快照中克隆出来的镜像就是子镜像,也就是链接镜像。
父镜像都是只读类型的,将块设备进行快照的创建和保护快照,就可以创建出任意数量的写时复制克隆,也就是链接镜像。
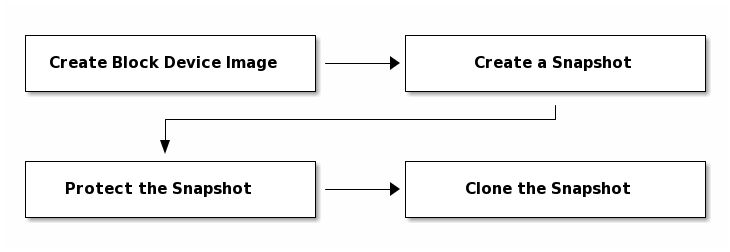
克隆镜像的流程如下:
首先创建出块设备文件,然后基于块设备文件创建一个快照,将快照添加一个保护机制,防止快照被删除,最后从快照中克隆镜像。
copy-on-write克隆常应用于快速创建虚拟机,作为虚拟机使用的iso镜像文件,基于一个环境配置完好的快照,将这个快照通过链接克隆的方式,快速克隆出n个镜像,秒级创建出虚拟机。
2.copy-on-write克隆的基本使用
2.1.在块存储中创建一个快照
[root@ceph-node-1 ~]# rbd snap create pool-test/rbd-storage.img@snap-system-image[root@ceph-node-1 ~]# rbd snap ls pool-test/rbd-storage.img
SNAPID NAME SIZE PROTECTED TIMESTAMP 6 snap-system-image 10 GiB Sat Apr 9 15:09:09 2022
2.2.将快照配置成保护模式
配置成保护模式后,快照将无法删除。
基于快照做克隆,一定要将快照完完整整的保护好,一旦丢失,克隆出来的镜像也无法使用。
[root@ceph-node-1 ~]# rbd snap protect pool-test/rbd-storage.img@snap-system-image
尝试删除快照,发现无法删除。
[root@ceph-node-1 ~]# rbd snap remove pool-test/rbd-storage.img@snap-system-image
Removing snap: 2022-04-09 15:12:10.684 7f4652554c80 -1 librbd::Operations: snapshot is protected0
% complete...failed.
rbd: snapshot 'snap-system-image' is protected from removal.
取消的命令格式:rbd snap unprotect {快照名称}
2.3.基于快照克隆出镜像
[root@ceph-node-1 ~]# rbd clone pool-test/rbd-storage.img@snap-system-image pool-test/vm1-clone.img
[root@ceph-node-1 ~]# rbd clone pool-test/rbd-storage.img@snap-system-image pool-test/vm2-clone.img[root@ceph-node-1 ~]# rbd -p pool-test ls
ceph-trash.img
rbd-storage.img
vm1-clone.img
vm2-clone.img
克隆的速度非常快,可以查看镜像的信息,发现会包含父镜像的信息,也就是来源于哪个快照克隆的。
[root@ceph-node-1 ~]# rbd info pool-test/vm1-clone.img
rbd image 'vm1-clone.img':size 10 GiB in 2560 objectsorder 22 (4 MiB objects)snapshot_count: 0id: 8ab1b874b899block_name_prefix: rbd_data.8ab1b874b899format: 2features: layeringop_features: flags: create_timestamp: Sat Apr 9 15:14:10 2022access_timestamp: Sat Apr 9 15:14:10 2022modify_timestamp: Sat Apr 9 15:14:10 2022parent: pool-test/rbd-storage.img@snap-system-image #父镜像overlap: 10 GiB
2.4.使用克隆的镜像
1.将镜像映射成裸磁盘
[root@ceph-node-1 ~]# rbd device map pool-test/vm1-clone.img
/dev/rbd12.直接挂在无需格式,因为里面有父镜像的数据
[root@ceph-node-1 ~]# mount /dev/rbd1 /mnt
[root@ceph-node-1 ~]# ls /mnt
file1 file10 file2 file3 file4 file5 file6 file7 file8 file9 lost+found
2.5.查看一个快照下有哪些克隆的镜像
[root@ceph-node-1 ~]# rbd children pool-test/rbd-storage.img@snap-system-image
pool-test/vm1-clone.img
pool-test/vm2-clone.img
这篇关于Ceph集群RBD块存储:快照与Copy-on-Write克隆的基本操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




