本文主要是介绍Python爬虫,爬取百度百科词条,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
看了慕课网的一个网络爬虫教程。模仿着写了一个简单的爬取百度百科的例子。
(1)安装Beautifulsoup4
Beautifulsoup是Python的一个网页解析库,使用起来很方便。http://cuiqingcai.com/1319.html这个链接是介绍如何使用。这个库是需要安装的,进入Pthon安装目录下面的Scripts目录,执行pip install beautifulsoup进行安装。
(2)爬虫具体实现
爬虫分为5个模块,调度模块、网页下载模块、网页解析模块、URL管理模块、输出模块。
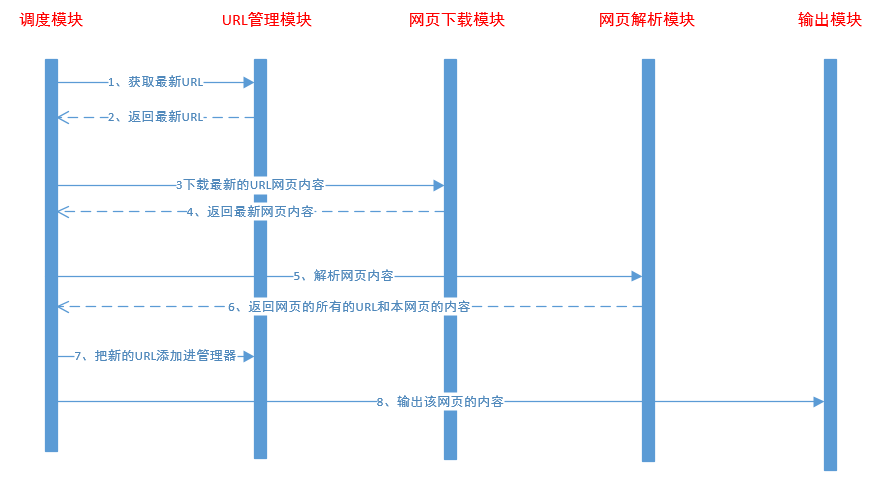
URL管理模块,负责保存最新的网页URL,每次取出最新的URL进行爬取。
#coding=utf8
class UrlManager(object):def __init__(self):self.new_urls = set()self.old_urls = set()#添加新的urldef _add_new_url(self, url):if url is None:returnif url not in self.new_urls and url not in self.old_urls:self.new_urls.add(url)#批量添加url这篇关于Python爬虫,爬取百度百科词条的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




