本文主要是介绍AI整体架构设计4:理解AI云原生,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

泛AI架构设计这个专栏主要关注围绕着AI运用于实际的业务场景所需的系统架构设计,包括业务数据治理、模型训练与管理、模型部署与调度。整体基于云原生技术,旨在通过开源领域的LLMOps或者MLOps技术,充分运用低代码平台构建高性能、高效率和敏捷响应的AI中台。
该专栏需要具备一定的计算机基础,专栏的前部会以基础知识点为主,后部会将这些知识点串起来。虽然文章已经深入浅出,还需仔细推敲。若卡在某篇文章,则请回到AI架构设计专栏再细细推敲。斯坦福2024人工智能报告则面向入门者通识性专栏。若已经稍有基础,则可以深入理解如何优雅的谈论大模型。技术宅麻烦死磕LLM背后的基础模型。

AI架构挑战
上面几节从GPU的知识点入手,清晰的介绍了GPU原理、构造以及运算模型。有了初步的认知之后,回到最原始的AI需求,来看看其对于基础架构的要求。AI最早于1956年提出,数十年沉沉浮浮,最后还是被广泛的运用于语音识别、机器学习、翻译、图像处理。深度学习的创新推出,使得近期人工智能有了突破性的增长。AI分为Discriminative AI和Generative AI两类,前者用于预测与分类,后者用于学习知识生成。下面的表格列出两种AI对于各项基础设施的需求:
| 需求 | 生成式AI | 预测式AI |
| 计算资源 | 极其高 需要专业化的硬件 | 中到高 一般用途硬件 |
| 数据容量 | 大量且多样化格式 | 专业化的历史数据 |
| 训练与微调 | 复杂 多轮的专业化计算 | 中等强度的训练 |
| 扩展与弹性 | 高度的可扩展和弹性的基础设施(应对可变和密集计算) | 可扩展性 弹性要求较低,支持流批一体处理 |
| 存储与吞吐 | 高性能高吞吐低延时 支持多样化的数据类型 | 中等吞吐量 注重数据分析,大部分为架构化 |
| 网络带宽 | 高带宽低延时,支持模型分布式训练 | 数据访问需要一致性和可靠 |
从上面各种AI对于基层基础设施的需求,有经验的工程师一般都能浮现一个关键的名词:云原生。
云原生技术使组织能够在公共云、私有云和混合云等现代化的动态环境中构建和运行可扩展的应用程序。容器、服务网格、微服务、基础设施和声明式 API 就是其中的典型案例。这些技术使低耦合的系统具有弹性、可管理和可监测。通过和Devops结合,工程师能够以低成本实现高频且可预测的系统迭代。

为什么要基于云原生
下图则直观的将AI所需要的关系图勾勒出来,黑色为某种能力,红色为两者的关系,箭头代表着谁服务于谁。例如编排(Orchestration)需要解决数据科学的可扩展性,而模型服务则为数据科学提供部署能力,自动化建模为数据科学提供自动化。希望读者还是花点时间仔细推敲下这幅图。
因此可以看到编排设计很重要的,它贯穿所有环节,其次对于每个能力对象的技术选型也十分关键。

那么AI为什么要基于云原生,因为云原生给AI带来很多的益处。按照CNAI的定义基于云原生的AI架构解决了人工智能应用科学家、开发人员和部署人员在云基础设施上开发、部署、运行、扩展和监控人工智能工作负载时面临的挑战。通过利用底层云基础设施的能力(例如CPU、GPU、网络和存储),提供隔离和受控共享机制,加速AI应用程序性能并降低成本。其实很大顶尖的公司都是将AI搭建在云原生的基础上,尤其是Kubernetes。

这里需要先科普下Kubernetes,它是一个编排平台,可用于部署和管理容器。容器是轻量级、可移植、独立的软件单元。AI模型可以打包到容器,然后部署到K8s集群。容器化对于AI部署尤其重要,因为不同模型依赖于不同版本的底层类库,经常会发生冲突。采用容器技术,可以解决依赖关系冲突的问题,且在模型部署中能够提供巨大的灵活性。
举个栗子:在一个服务器上面将A和B的应用打包到两个容器,一个容器里面装了Ubuntu系统,另一个容器里面装了Linux系统。两个容器可以看成是小的世界,都可以跑在服务器的操作系统上面。两个应用各自所需要的环境互不打扰。而且容器可以随时销毁,随时启动。
在存储方面,高质量的数据用于训练和测试人工智能模型,云原生基础设施可以通过多种方式访问数据,例如数据湖和数据仓库。无论是私有还是公有的云技术都能够支持块、对象和文件存储系统,非常适合提供低成本、可扩展的存储。
例如,模型的大小可以达到千兆字节。在训练阶段,每次拉取模型的检查点都会对网络和存储带宽造成严重负载。 对模型采用容器化设计,且在注册表中完成托管和缓存则能有效解决,同时还有利于模型的加签、验证、证明和数据来源管控。

AI云原生架构
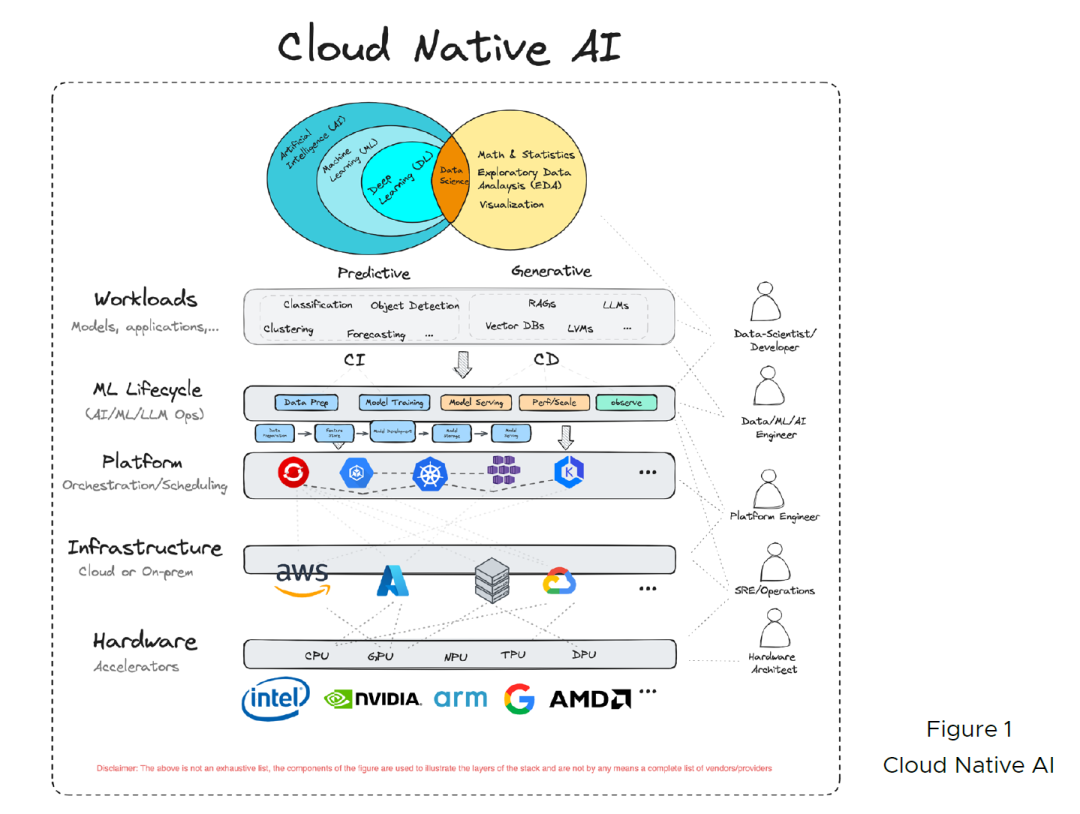
下图为CNAI提出来的AI云原生架构,它将整个架构设计分为五层,从下往上分别是硬件层,基础设施层,云原生平台层,AIOps/MLOps/LLMOps层,最顶层则为模型应用层。这个专栏还是关注在上三层,除此之外也会覆盖到新的计算资源GPU,以及其调度策略。
这篇关于AI整体架构设计4:理解AI云原生的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









