本文主要是介绍通俗理解向量:从One-hot 到词嵌入,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在NLP任务中,将文本转换为向量是一个必要的步骤,这个过程被称为词嵌入。
很多同学在学习过程中,对向量这一概念很模糊,或者无法理解:为什么要把一个单独的token,或者一个数字,在转换为复杂的向量呢?
为了说明这个问题,本文以One-hot编码为切入点,来理解数值转换为向量的作用。在之前介绍视觉分类模型时,曾多次介绍过该算法。
1、什么是 one-hot 编码
one-hot 编码用于将离散的数值转换为二进制向量。
这里有两个关键词,第一个是离散的分类,第二个是二进制向量。
什么是离散的分类呢?
假设我们现在有三个类别,分别是猫、狗、人,当然你也可以认为是3个token,都可以。
那这 3 个类别就是一种离散的分类:它们之间互相独立,不存在谁比谁大、谁比谁先的关系。
这就是离散分类。
再看下二进制向量。
向量我们都能理解,A = [1, 2, 3, 4] 这是一个一维数组,也可以称之为一维向量。
那么二进制向量,就是里面的数字都是二进制的,像是[0, 1, 0, 0],因为在二进制里面,数字只有 0 和 1。
在搞清楚这两个概念之后,我们回到分类任务本身,需要对猫、狗、人这三个类别进行分类。
在神经网络中,需要一种数学表示方法,来表示猫、狗、人的分类。
我们最容易想到的,便是以 0 代表猫,以 1 代表狗,以 2 代表人这种简单且粗暴的方式。
那这样行不行呢?肯定不行。
因为一旦这样表示,以数学的运算逻辑,人(2) = 狗(1) + 狗(1)。
这样,在计算机眼里,一个人就等于两只狗,造成逻辑错乱了。
因此,需要有一种表示方法,在离散分类中,将互相独立的分类表示为互相独立的数字,使其不存在大小关系,也不存在可计算关系。
这就要用到 one-hot 编码了,也叫独热编码。
它就用二进制向量来表征这种离散的分类标签。
2、独热编码怎么做?
猫、狗、人三分类问题,我们可以很简单的将其进行如下的编码。
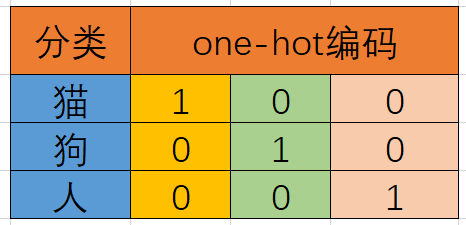
上表竖着看,黄色的代表是猫的编码 [1, 0, 0],浅绿色代表的是狗的编码 [0, 1, 0]。
解释如下:如果一个类别标签是猫,那么猫对应的位置就是1,狗和人对应的位置就是0,得到一个编码[1, 0, 0]。
这样得到的编码都是独立的。
我们学过几何,在三维坐标系下,[1, 0, 0]、[0, 1, 0]和[0, 0, 1]这三个向量是互相垂直的,也就是互相正交独立。
他们之间欧式距离相等,这就解决了上面说的问题。
也不存在人=狗+狗的错误逻辑了。
3、词嵌入怎么做的
在大模型对文本进行处理之前,其中一个关键的预处理过程是将文本(token)转换为词嵌入向量。
一般而言,这时转换完的词嵌入向量是一个多维向量,并且每个维度都不是二进制(0或者1这么简单)。
所以,词嵌入向量与One-hot编码有着很大的区别。
区别在于,One-hot编码中只有一个位置的值为1,其余全为0。而在词嵌入向量中,包含了很多数值,每个数值具有不同的意思,代表token中的不同特征。
可以说,One-hot向量是词嵌入向量在数学表示上的一个特殊情况。
至于词嵌入该如何实现,如何更友好的理解词嵌入使用的动机和原理,可以关注《Transformer最后一公里》专栏,专栏里会详细拆解Transformer架构中用到的各种算法原理和使用动机。
我的Transformer专栏来啦-CSDN博客文章浏览阅读558次,点赞11次,收藏5次。现在很多主流的大语言模型,比如chatGPT都是基于该架构进行的模型设计,可以说Transformer顶起了AI的半壁江山。对于这些有些枯燥的概念,有些乏味的数学表达,我会尽可能说的直白和通俗易懂,打通理解Transformer的最后一公里。我会在本公众号进行文章的首发,相关文章会添加标签“Transformer专栏”,可点击文章左下角的标签查看所有文章。巧的是,下班路上刚手敲完大纲,晚上一个小伙伴来咨询学习LLM的事情,问我之前写的《五一节前吹的牛,五一期间没完成,今天忙里偷闲,给完成了。https://blog.csdn.net/dongtuoc/article/details/138633936?spm=1001.2014.3001.5501
这篇关于通俗理解向量:从One-hot 到词嵌入的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





