本文主要是介绍设计非递归算法,编程:在二叉排序树中,打印关键码a, b的公共祖先。注:例,若a是b的祖先,则a不算作公共祖先。反之亦然。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二叉排序树:
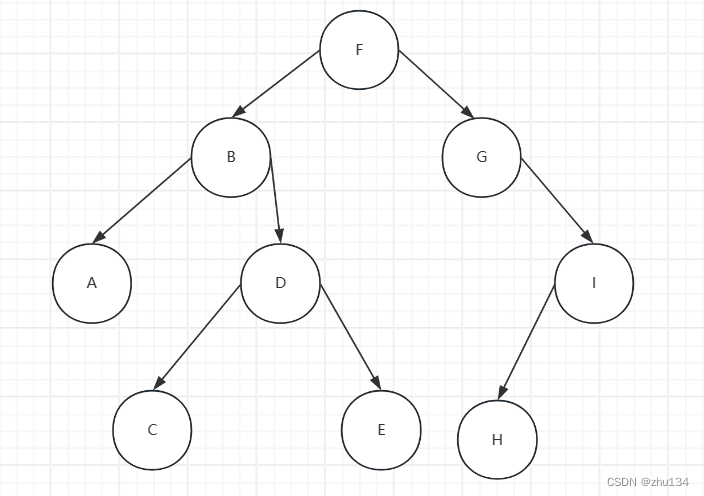
代码:
#include <iostream>
using namespace std;// 定义二叉树节点结构
typedef struct BTNode {char show;struct BTNode* left;struct BTNode* right;
} BTNode;// 非递归插入节点的函数
BTNode* insertNode(BTNode* root, char key) {BTNode* newNode = new BTNode{key, nullptr, nullptr};if (root == nullptr) {return newNode;}BTNode* parent = nullptr;BTNode* current = root;while (current != nullptr) {parent = current;if (key < current->show) {current = current->left;} else if (key > current->show) {current = current->right;} else {// 如果键已经存在,不插入重复的节点delete newNode;return root;}}if (key < parent->show) {parent->left = newNode;} else {parent->right = newNode;}return root;
}// 根据数值查找节点的函数
BTNode* findNodeByValue(BTNode* root, char value) {BTNode* current = root;while (current != nullptr && current->show != value) {if (value < current->show) {current = current->left;} else {current = current->right;}}return current;
}// 判断是否是祖先节点的函数
bool isAncestor(BTNode* root, BTNode* node) {if (root == nullptr) return false;if (root == node) return true;return isAncestor(root->left, node) || isAncestor(root->right, node);
}// 寻找公共祖先的函数
BTNode* findCommonAncestor(BTNode* root, char a, char b) {// 边界情况处理if (root == nullptr) return nullptr;// 确保 a 小于 bif (a > b) swap(a, b);BTNode* nodeA = findNodeByValue(root, a);BTNode* nodeB = findNodeByValue(root, b);// 判断是否 a 是 b 的祖先或者 b 是 a 的祖先if (nodeA && nodeB) {if (isAncestor(nodeA, nodeB) || isAncestor(nodeB, nodeA)) {return nullptr;}}while (root) {if (root->show < a) {root = root->right;} else if (root->show > b) {root = root->left;} else {return root;}}return nullptr;
}// 测试用例
void printCommonAncestor(BTNode* root, char a, char b) {BTNode* ancestor = findCommonAncestor(root, a, b);if (ancestor) {cout << a << "和" << b << "的公共祖先是:" << ancestor->show << endl;} else {cout << a << "和" << b << "没有公共祖先" << endl;}
}// 主函数
int main() {// 构建二叉搜索树BTNode* root = nullptr;root = insertNode(root, 'F');root = insertNode(root, 'B');root = insertNode(root, 'G');root = insertNode(root, 'A');root = insertNode(root, 'D');root = insertNode(root, 'I');root = insertNode(root, 'C');root = insertNode(root, 'E');root = insertNode(root, 'H');// 输入要查询的两个字符char x, y;cout << "请输入要查询的两个字符: ";cin >> x >> y;// 根据数值查找节点并打印结果BTNode* nodeX = findNodeByValue(root, x);BTNode* nodeY = findNodeByValue(root, y);if (nodeX && nodeY) {printCommonAncestor(root, nodeX->show, nodeY->show);} else {cout << "输入的字符不在二叉搜索树中" << endl;}// 释放内存(这里简单起见不进行内存释放)return 0;
}
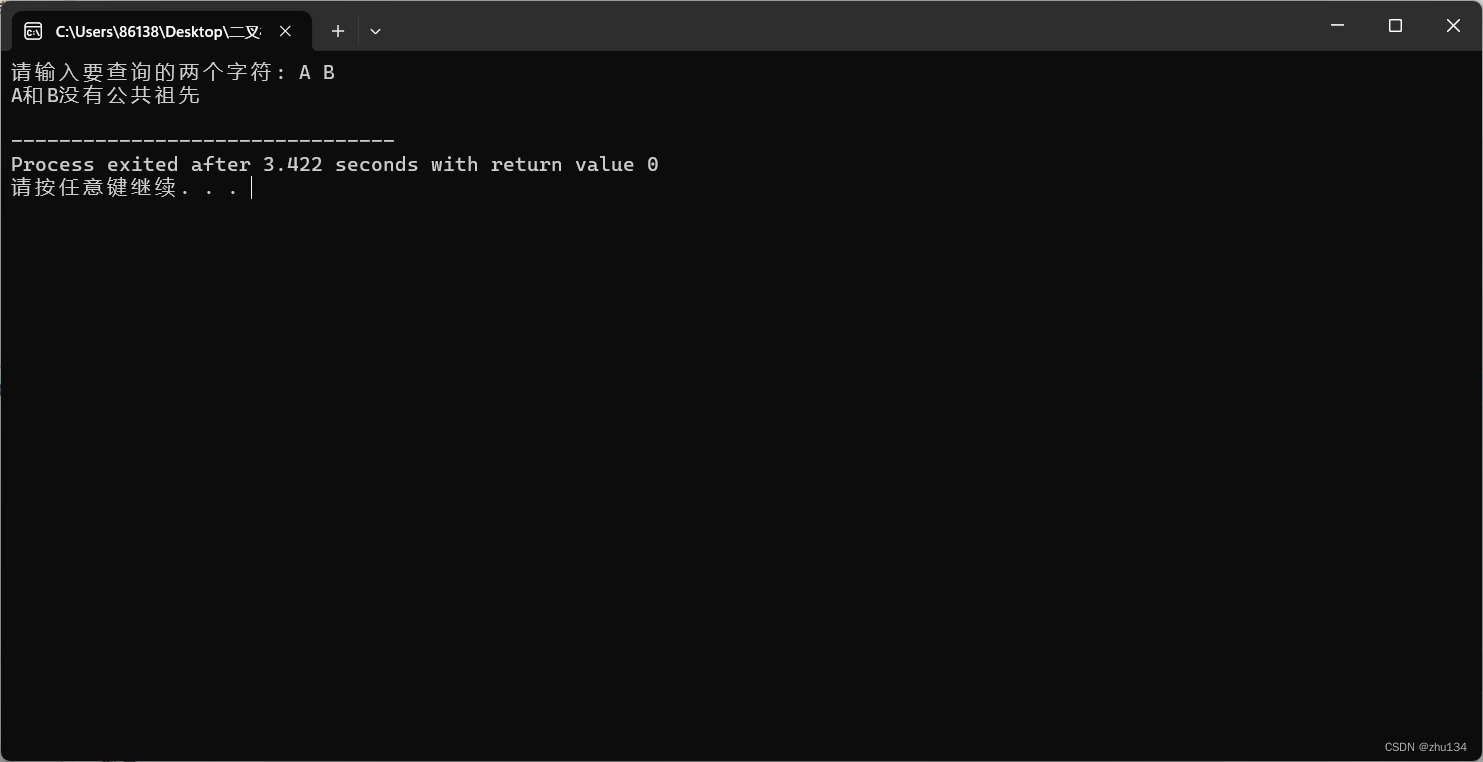
运行截图:
示例1:
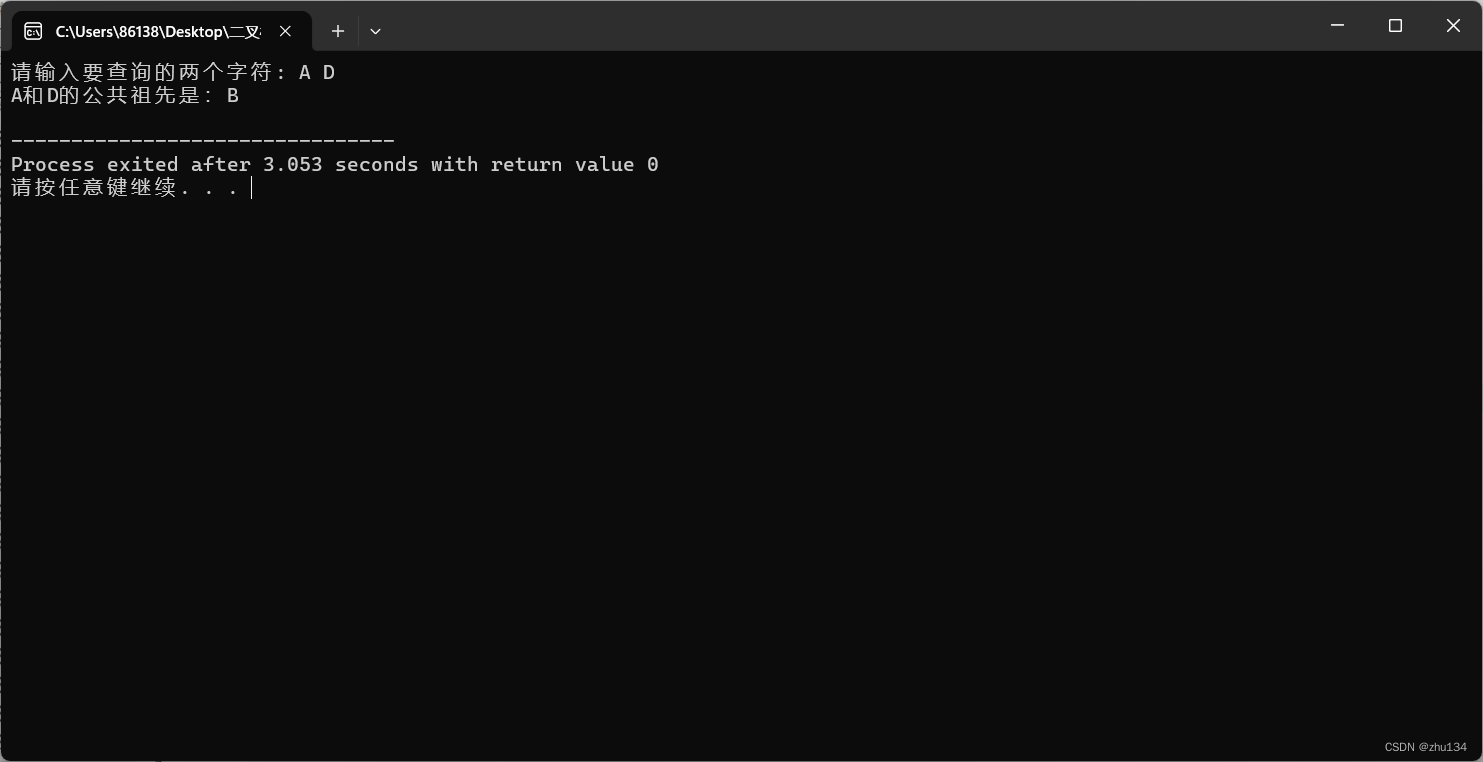
示例2:
这篇关于设计非递归算法,编程:在二叉排序树中,打印关键码a, b的公共祖先。注:例,若a是b的祖先,则a不算作公共祖先。反之亦然。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






