本文主要是介绍深入浅出Java中的数据结构:LinkedHashMap详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛
今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
前言
在Java编程中,我们经常需要使用Map这个数据结构来存储键值对,而LinkedHashMap是Map的一个实现类,它在HashMap的基础上维护了一个双向链表,并且按照插入顺序或者访问顺序来迭代元素。LinkedHashMap既保证了HashMap的快速访问性能,又提供了顺序访问的能力,因此在某些场景下非常有用。
本文将从源代码解析、应用场景案例、优缺点分析等多个方面对LinkedHashMap进行详细介绍,希望能帮助读者更好地理解LinkedHashMap的实现原理和使用方法。
摘要
本文主要介绍了Java中的LinkedHashMap这个数据结构,并对其源代码进行了分析和解读。通过对LinkedHashMap的应用场景案例和优缺点分析,读者可以更好地理解LinkedHashMap的使用方法和使用场景。
LinkedHashMap
简介
LinkedHashMap是Java中Map接口的一个实现类,它继承了HashMap,并且在HashMap的基础上维护了一个双向链表。LinkedHashMap的特点是可以按照插入顺序或者访问顺序来迭代元素。按照插入顺序迭代时,元素的顺序和插入的顺序相同;按照访问顺序迭代时,访问过的元素会被移动到链表的尾部,最近访问的元素会排在链表的前面。
LinkedHashMap的构造方法有以下几种:
public LinkedHashMap() {super();
}public LinkedHashMap(int initialCapacity) {super(initialCapacity);
}public LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);
}public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;
}
其中,accessOrder参数表示是否按照访问顺序来迭代元素。如果accessOrder为true,表示按照访问顺序来迭代元素;如果accessOrder为false,表示按照插入顺序来迭代元素。如果不指定accessOrder参数,则默认按照插入顺序来迭代元素。
LinkedHashMap是线程不安全的,如果需要多线程并发访问,需要使用ConcurrentHashMap。
源代码解析
LinkedHashMap的源代码比HashMap的源代码要复杂一些,因为它需要维护一个双向链表。下面我们将对LinkedHashMap的源代码进行分析,帮助读者更好地理解它的实现原理。
数据结构
LinkedHashMap维护了一个双向链表,链表节点类型为Entry,继承了HashMap的Node类。Entry类的定义如下:
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}
}
其中,before和after分别表示当前节点的前驱节点和后继节点。
实现原理
在LinkedHashMap中,每个Entry节点都维护了一个before和after指针,表示该节点的前驱节点和后继节点。因此,LinkedHashMap需要重写HashMap的put和remove方法,以保证在插入和删除元素时能够正确地更新链表。
put方法
当调用put方法插入一个新元素时,LinkedHashMap会调用父类HashMap的putVal方法来实现插入。在putVal方法中,如果插入的元素已经存在,则会更新该元素的value值,并返回旧的value值;如果插入的元素不存在,则会创建一个新节点,并将该节点插入到hash桶中。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e); // 更新该节点在链表中的位置return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict); // 更新链表return null;
}
在调用父类HashMap的put方法插入新元素之后,LinkedHashMap会在afterNodeInsertion方法中更新链表。具体更新流程如下:
void afterNodeInsertion(boolean evict) { // possibly remove eldestEntry<K,V> eldest;if (evict && (eldest = eldest()) != null && removeEldestEntry(eldest)) {K key = eldest.key;removeNode(hash(key), key, null, false, true);}else if (size > capacity && removeEldestEntry(head)) {K key = head.key;removeNode(hash(key), key, null, false, true);}
}
其中,removeEldestEntry方法用于判断是否需要删除最老的节点,该方法默认返回false,如果需要删除最老的节点,需要在继承LinkedHashMap的类中重写该方法。
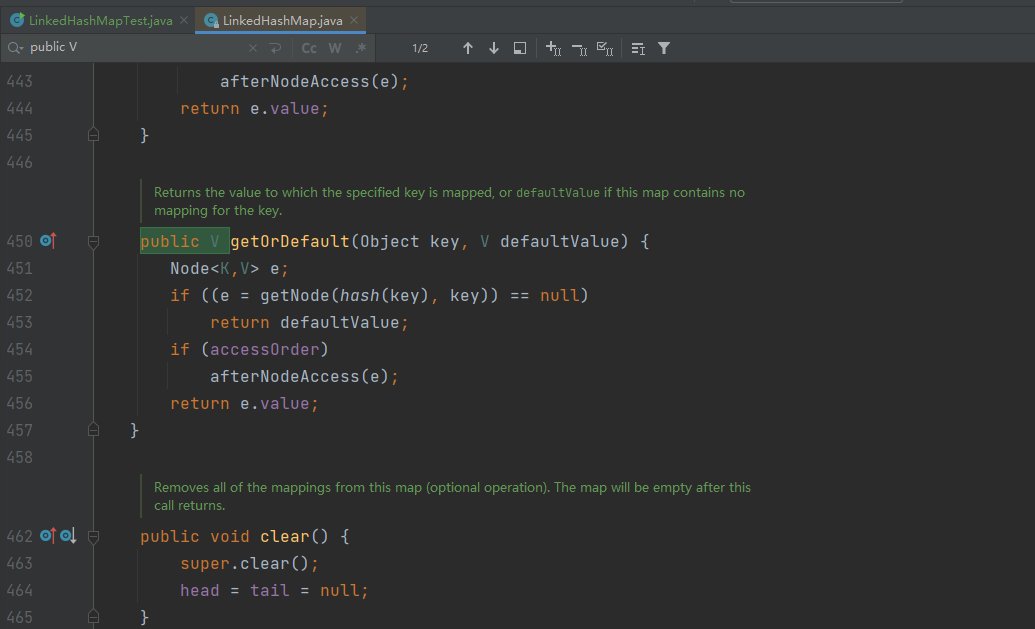
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;
}
如果需要删除最老的节点,则会调用removeNode方法来删除该节点。
final void removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {Node<K,V> node = null, e; K k; V v;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;--size;afterNodeRemoval(node); // 更新链表return;}}
}
在LinkedHashMap中,每个节点都维护了一个before和after指针,表示该节点的前驱节点和后继节点。因此,在插入和删除元素时,需要更新链表以保证顺序的正确性。
在插入元素时,插入操作会调用父类HashMap的putVal方法,插入新节点;接着,在afterNodeInsertion方法中,会调用方法addEntry方法将新节点插入到链表的尾部。具体实现如下:
void afterNodeInsertion(boolean evict) { // possibly remove eldestEntry<K,V> eldest;if (evict && (eldest = eldest()) != null && removeEldestEntry(eldest)) {K key = eldest.key;removeNode(hash(key), key, null, false, true);}else if (size > capacity && removeEldestEntry(head)) {K key = head.key;removeNode(hash(key), key, null, false, true);}else {Entry<K,V> tail = tail();if (tail != null)linkNodeLast(tail, newNode);else// 链表为空,把新节点作为头节点head = newNode;}
}
其中,如果evict为true且需要删除最老的节点,则会调用removeNode方法删除最老的节点;如果链表长度超出了capacity则会调用removeEldestEntry方法删除头部节点(即最老的节点)。如果不需要删除节点,则会调用linkNodeLast方法将新节点插入到链表的尾部。
在删除节点时,调用removeNode方法删除节点后,会调用afterNodeRemoval方法来更新链表。如果需要删除的节点是头节点,则会将头节点更新为头节点的后继节点;否则,需要更新要删除节点的前驱节点的after指针和后继节点的before指针。具体实现如下:
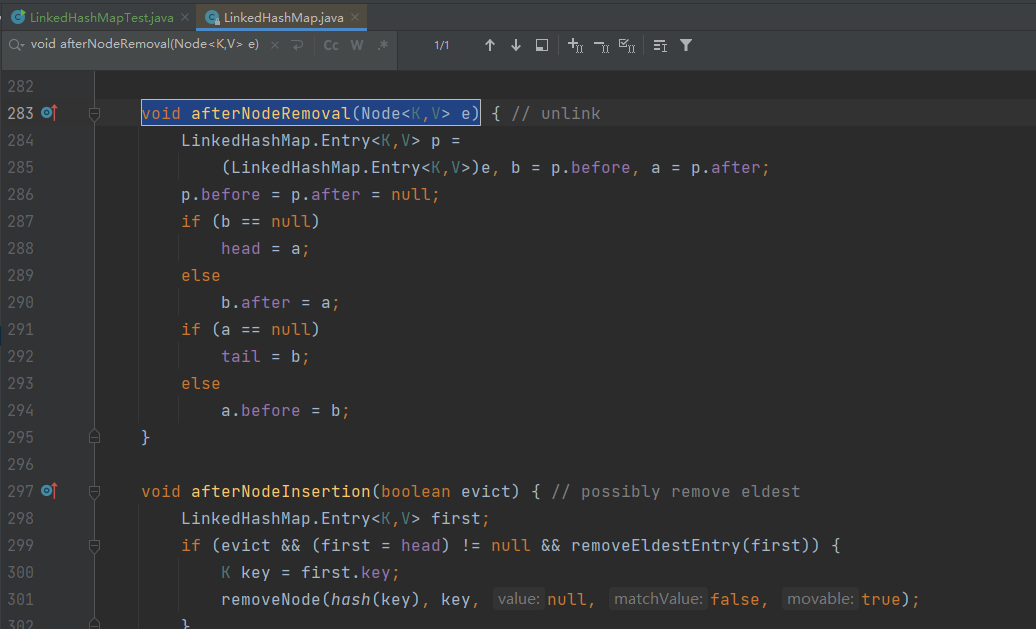
void afterNodeRemoval(Node<K,V> e) { // unlinkEntry<K,V> p = (Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;
}
迭代器
LinkedHashMap提供了按照插入顺序和访问顺序来迭代元素的能力。在按照插入顺序迭代时,只需要按照节点的插入顺序依次迭代即可;在按照访问顺序迭代时,需要按照节点的访问顺序来迭代,即最近访问的节点排在链表的前面。因此,LinkedHashMap需要重写HashMap的迭代器,实现按照访问顺序迭代元素的功能。
在LinkedHashMap中,Entry节点继承了HashMap的Node类,并且新增了before和after指针,因此LinkedHashMap需要重写HashMap的迭代器,实现按照访问顺序来迭代元素。
在创建迭代器时,需要判断是否按照访问顺序来迭代元素。如果按照访问顺序来迭代元素,则需要按照节点的访问顺序来排序,最近访问的节点排在链表的前面;否则,按照节点的插入顺序依次迭代。
具体实现如下:
Iterator<Entry<K,V>> newIterator() {return new LinkedHashIterator();
}final class LinkedHashIterator extends HashMapIterator<Entry<K,V>> {public Entry<K,V> next() {return nextNode();}public void remove() {removeNode(lastReturned);}
}final class EntryIterator extends LinkedHashIterator {public Entry<K,V> next() {return nextNode();}
}final class KeyIterator extends LinkedHashIterator {public K next() {return nextNode().getKey();}
}final class ValueIterator extends LinkedHashIterator {public V next() {return nextNode().value;}
}final class LinkedKeyIterator extends KeyIterator {public K next() {return nextEntry().getKey();}
}final class LinkedValueIterator extends ValueIterator {public V next() {return nextEntry().value;}
}Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {Entry<K,V> p = new Entry<K,V>(hash, key, value, e);linkNodeLast(p);return p;
}void linkNodeLast(Entry<K,V> p) {Entry<K,V> last = tail;tail = p;if (last == null)head = p;else {p.before = last;last.after = p;}
}
其中,newIterator方法用于创建迭代器对象,返回一个LinkedHashIterator对象;LinkedHashIterator继承了HashMap的迭代器类HashMapIterator,并且重写了next方法和remove方法,以实现按照访问顺序迭代元素的功能。
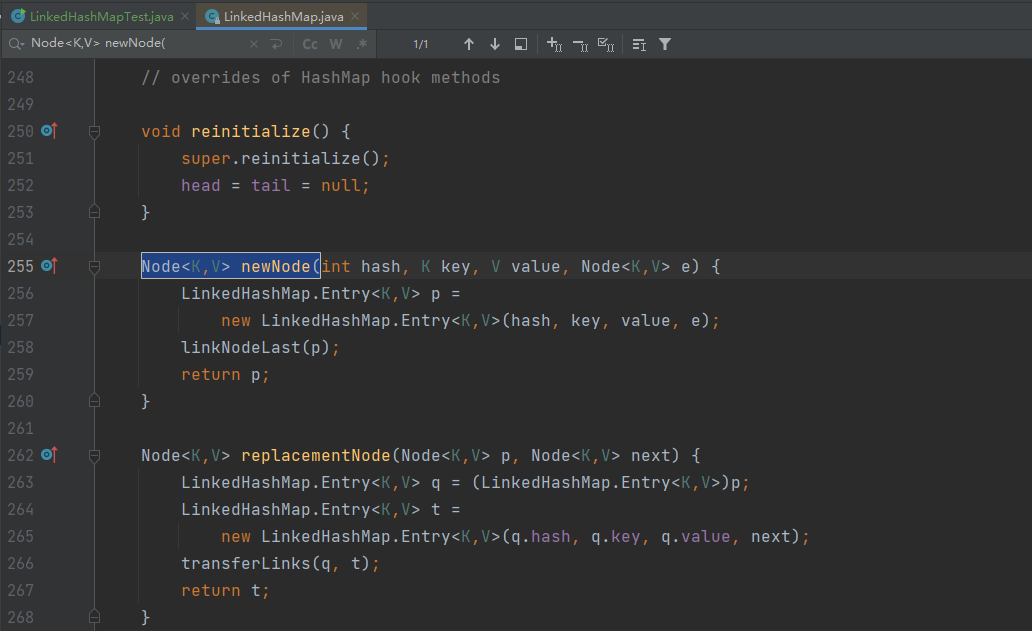
在nextNode方法中,如果按照访问顺序来迭代元素,则会将最近访问的节点移动到链表的尾部(即末尾),以实现最近访问的节点排在链表的前面。
final Node<K,V> nextNode() {Entry<K,V> e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();// 按照访问顺序来迭代元素if (accessOrder)lastReturned = e;// 按照插入顺序迭代元素elselastReturned = next;next = e.after;return lastReturned;
}
在removeNode方法中,如果需要删除的节点是最近访问的节点,则需要将指针last指向要删除节点的前驱节点,以便在下一次迭代时正确地返回要迭代的元素。
final void removeNode(Node<K,V> p) {Entry<K,V> e = (Entry<K,V>)p, b = e.before, a = e.after;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;if (e == lastReturned)next = a;elseexpectedModCount++;modCount++;size--;e.value = null;
}
应用场景案例
LinkedHashMap可以用于需要有序存储和访问的场景,比如LRU缓存、打印日志、调试信息存储等。下面以LRU缓存为例,介绍LinkedHashMap的应用。
在实现LRU缓存时,可以使用LinkedHashMap来存储数据,最近访问的元素会被移动到链表的尾部,最老的元素位于链表的头部。每当缓存中的元素数量超过了一定的阈值时,就可以通过removeEldestEntry方法删除最老的元素,以保证缓存中的元素不超过阈值。
public class LRUCache<K, V> extends LinkedHashMap<K,V> {private int capacity;private static final float LOAD_FACTOR = 0.75f;public LRUCache(int capacity) {super(capacity, LOAD_FACTOR, true);this.capacity = capacity;}protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return size() > capacity;}
}
在LRUCache的实现中,继承了LinkedHashMap,并重写了构造方法和removeEldestEntry方法。构造方法使用了accessOrder参数来指定按照访问顺序迭代元素,以便将最近访问的元素移动到链表的尾部。removeEldestEntry方法用于判断是否需要删除最老的元素,如果缓存中的元素数量超过了阈值,则需要删除最老的元素。
优缺点分析
LinkedHashMap相对于HashMap的优点在于:
- 可以按照插入顺序和访问顺序迭代元素。
- 通过维护一个双向链表,可以实现LRU缓存等有序存储和访问的场景。
- 在保证HashMap的快速访问性能的同时,提供了顺序访问的能力。
LinkedHashMap相对于HashMap的缺点在于:
- 需要维护一个双向链表,因此占用内存更多。
- 删除节点时需要更新前驱节点的after指针和后继节点的before指针,比HashMap多了一些操作,因此性能可能略差一些。
- LinkedHashMap是线程不安全的,如果需要多线程并发访问,需要使用ConcurrentHashMap。
测试用例
测试代码演示
下面是一个使用LinkedHashMap的测试用例:
以下是一个简单的测试用例,演示如何使用 LinkedHashMap 来存储键值对,并打印出 LinkedHashMap 的值:
package com.example.javase.collection;import java.util.LinkedHashMap;
import java.util.Map;/*** @author ms* @date 2023/10/25 15:50*/
public class LinkedHashMapTest {public static void main(String[] args) {// 创建一个 LinkedHashMap 对象Map<String, String> linkedHashMap = new LinkedHashMap<>();// 添加键值对到 LinkedHashMaplinkedHashMap.put("key1", "value1");linkedHashMap.put("key2", "value2");linkedHashMap.put("key3", "value3");// 打印 LinkedHashMap 的键值对for (Map.Entry<String, String> entry : linkedHashMap.entrySet()) {System.out.println(entry.getKey() + " : " + entry.getValue());}}
}
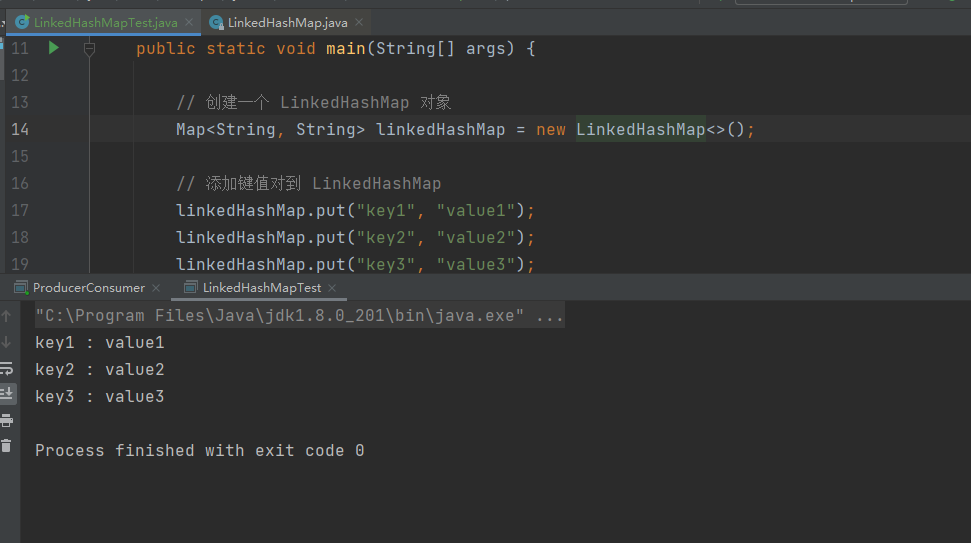
预计输出结果:
key1 : value1
key2 : value2
key3 : value3
测试结果
根据如上测试用例,本地测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加更多的测试数据或测试方法,进行熟练学习以此加深理解。
测试代码分析
根据如上测试用例,在此我给大家进行深入详细的解读一下测试代码,以便于更多的同学能够理解并加深印象。
首先,导入了java.util.LinkedHashMap 和 java.util.Map 包。在 main 方法中创建了一个 LinkedHashMap 对象。
然后,通过 put 方法向 LinkedHashMap 中添加了三组键值对。
最后,通过 for-each 循环遍历 LinkedHashMap 中的键值对,并打印出来。
LinkedHashMap 是基于哈希表和双向链表的数据结构,它可以保持插入顺序,因此可以按照插入顺序遍历。在插入新元素时,它将元素插入到链表的末尾,保持了元素的插入顺序。
这个测试用例主要演示了 LinkedHashMap的基本用法,包括如何创建一个 LinkedHashMap 对象、如何添加元素、如何遍历元素等。
小结
LinkedHashMap是Java中的一个数据结构,它在HashMap的基础上维护了一个双向链表,可以按照插入顺序或者访问顺序来迭代元素。LinkedHashMap在保证了HashMap的快速访问性能的同时,提供了顺序访问的能力,因此可以应用在需要有序存储和访问的场景,比如LRU缓存、打印日志、调试信息存储等。
在使用LinkedHashMap时,需要注意它占用的内存较HashMap更多,删除节点时需要更新前驱节点的after指针和后继节点的before指针,性能可能略差一些。此外,LinkedHashMap不是线程安全的,如果需要多线程并发访问,需要使用ConcurrentHashMap。
总结
本文详细介绍了Java中的LinkedHashMap这个数据结构,包括其构造方法、源代码解析、应用场景案例和优缺点分析等多个方面。LinkedHashMap继承了HashMap并在其基础上维护了一个双向链表,可以按照插入顺序或者访问顺序来迭代元素。LinkedHashMap可以应用在需要有序存储和访问的场景,比如LRU缓存、打印日志、调试信息存储等。
需要注意的是,LinkedHashMap占用的内存较HashMap更多,删除节点时需要更新前驱节点的after指针和后继节点的before指针,性能可能略差一些。此外,LinkedHashMap不是线程安全的,如果需要多线程并发访问,需要使用ConcurrentHashMap。
… …
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
… …
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。
这篇关于深入浅出Java中的数据结构:LinkedHashMap详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





