本文主要是介绍《python自然语言处理》笔记---chap3加工原料文本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
chap3中关于,NLP中的关键概念,包括分词和词干提取。字符串、文件、正则表达式、去除HTML标签
以下所有程序,默认导入包
import nltk,re,pprint #即,nltk包,正则表达式re包,输出pprint包3.1 从网络和硬盘访问文本
电子书
http://www.gutenberg.org/files/2554/2554.txt,古腾堡项目编号2554的文本:《罪与罚》的英文翻译
#coding:utf-8
import nltk
from urllib import urlopen
url = "http://www.gutenberg.org/files/2554/2554.txt"
raw=urlopen(url).read()
print type(raw) #文本的类型
print len(raw) #文本长度
print raw[:75] #文本前75个字符,不要直接打印出raw,太长了
#使用代理访问:
#proxies={'http':'http://www.someproxy.com:3128'}
#raw=urlopen(url,proxies=proxies).read()分词:将字符串分解为词和标点符号;经过分词,产生一个词汇和标点符号的链表
tokens=nltk.word_tokenize(raw)
print type(tokens)
print len(tokens)
print tokens[:10]
#从链表创建一个NLTK文本,对其进行操作
text=nltk.Text(tokens)
print type(text)
print text[:10] #text似乎同tokens没什么区别?
#print text.collocations()古腾堡项目的每个文本:包含一个首部,涵盖了文本的名称、作者、扫描和校对文本的人的名字、许可证等信息。手工检查文件以发现标记内容开始和结尾的独特的字
符串。
print raw.find("PART I")
print raw.rfind("End of Project Gutenberg's Crime") #逆向查找
#重新复制,将从"PART I"到"End of Project Gutenberg's Crime"部分截下来,赋给raw
raw=raw[raw.find("PART I"):raw.rfind("End of Project Gutenberg's Crime")]
处理的HTML
HTML全部内容包括:meta元标签、图像标签、map标签、JavaScript、表单和表格。
提取文本:clean_html()将HTML字符串作为参数,返回原始文本,然后对原始文本进行分词,活得熟悉的文本结构
#coding:utf-8
import nltk
from urllib import urlopen
url = "http://news.bbc.co.uk/2/hi/health/2284783.stm"
html = urlopen(url).read()
print html[:60]
#'<!doctype html public "-//W3C//DTD HTML 4.0 Transitional//EN'
#html=html[:60]
raw = nltk.clean_html(html)
tokens = nltk.word_tokenize(raw)
tokens=tokens[96:399]
text=nltk.Text(tokens)
print text.concodance('gene')
'''
使用clean_html()函数出错:
raise NotImplementedError ("To remove HTML markup, use BeautifulSoup's get_text() function")
NotImplementedError: To remove HTML markup, use BeautifulSoup's get_text() function
根据官方网站:介绍http://www.nltk.org/_modules/nltk/util.html
def clean_html(html):
raise NotImplementedError ("To remove HTML markup, use BeautifulSoup's get_text() function")
[docs]def clean_url(url):
raise NotImplementedError ("To remove HTML markup, use BeautifulSoup's get_text() function")
网站:http://stackoverflow.com/questions/10524387/beautifulsoup-get-text-does-not-strip-all-tags-and-javascript介绍:
以后的版本,似乎不支持clean_html()和clean_url()这两个函数
Support for clean_html and clean_url will be dropped for future versions of nltk. Please use BeautifulSoup for now...it's very unfortunate.
'''通过尝试,找到内容索引的开始和结尾,并选择你感兴趣的标识符,初始化一个文本。
更多更复杂的有关处理HTML 的内容,可以使用http://www.crummy.com/software/BeautifulSoup/上的Beautiful Soup 软件包。
处理搜索引擎的结果
搜索引擎的主要优势是规模
读取本地文件
open()函数:
f=open(r'D:\test.txt') #注意格式,文件路径前面用个r,或者对文件路径里面的符号进行转义
raw=f.read()
#按行读出
for line in f:
print line.strip()#去掉换行符
#nltk语料库中的文件,使用nltk.data.find()函数
path = nltk.data.find('corpora/gutenberg/melville-moby_dick.txt')
raw = open(path, 'rU').read()从 PDF、MS Word 及其他二进制格式中提取文本
打开PDF和MSWord,用第三方函数库如pypdf和pywin32,
捕获用户输入
输入函数:raw_input("")
输出函数:print
NLP 的流程

处理流程:打开一个URL,读里面HTML 格式的内容,去除标记,并选择字符的切
片,然后分词,是否转换为nltk.Text 对象是可选择的。我们也可以将所有词汇小写并提取词汇表。
一个对象的类型决定了它可以执行哪些操作,如可以追加元素到一个链表,但是不能追加元素到一个字符串
可以用加号,连接字符串与字符串,但是不能连接字符串与链表
3.2 字符串:最底层的文本处理
字符串的基本操作
1.字符串中包含单引号,需要用"\"转义
2.可用单引号,双引号,三重引号来指定字符串,其中的区别,见博客
3.字符串跨好几行,a:使用反斜杠"\",解释器就知道第一行的表达式不完整;b:使用括号,将两个字符串括起来,中间换行即可,不用加逗号
4.对字符串操作,“+”加法:连接字符串;“*”乘法:多倍连接字符串;不能使用减法和除法
>>> a='first'\
'second' #使用反斜杠跨行
>>> a
'firstsecond'
'very' + 'very' + 'very'
'very' * 3输出字符串
print '逗号隔开','能够连着一行输出去'“,”告诉python不要再行尾输出换行符
访问单个字符
1.从0开始,长度为1的字符串,用索引符号[]调用,
2.超出索引范围,出错
3.字符串的负数索引,-1为最后一个字符的索引,-2,-3,...对应着过去,
4.计数单个字符。将所有字符小写,忽略掉大小写,并过滤掉非字母字符
import nltk
from nltk.corpus import gutenberg
raw=gutenberg.raw('melville-moby_dick.txt')
fdist=nltk.FreqDist(ch.lower() for ch in raw if ch.isalpha())
print fdist.keys() #出现频率最高排在最先的顺序显示出英文字母
print fdist.values() #fdist如同key-value一般,调用keys和values方法,能够显示对应的字符情况
fdist.plot() #可视化输出
'''运行结果:
[u'e', u't', u'a', u'o', u'n', u'i', u's', u'h', u'r', u'l', u'd', u'u', u'm', u'c', u'w', u'f', u'g', u'p', u'b', u'y', u'v',
u'k', u'q', u'j', u'x', u'z']
[117092, 87996, 77916, 69326, 65617, 65434, 64231, 62896, 52134, 42793, 38219, 26697, 23277, 22507, 22222, 20833, 20820,
17255, 16877, 16872, 8598, 8059, 1556, 1082, 1030, 632]
图略'''访问子字符串
1.使用切片,开始于第一个索引,结束于最后一个索引的前一个。注意,最后索引的前一个
2.负数索引切片,-1为最后一个,-2,-3...推算过去
3.省略:第一个值,即从字符串开头开始;第二个值,切到字符结尾结束;
4.in操作符:测试一个字符串是否包含一个特定的子字符串
5.find()函数操作:子字符串在字符串内的位置;从开头到找到的第一个位置.(若是第二个怎么算?)
6.rfind()函数,从末尾开始查找,同findd().只是开始位置相反而已。
monty='Monty Python'
monty[6:10]
monty[-12:-7]
phrase = 'And now for something completely different'
if 'thing' in phrase:
print '''find "thing"'''更多的字符串操作
help(str)可以找到所有的有关函数
| 方法 | 功能 |
| s.find(t) | 字符串s 中包含t 的第一个索引(没找到返回-1) |
| s.rfind(t) | 字符串s 中包含t 的最后一个索引(没找到返回-1) |
| s.index(t) | 与s.find(t)功能类似,但没找到时引起ValueError |
| s.rindex(t) | 与s.rfind(t)功能类似,但没找到时引起ValueError |
| s.join(text) | 连接字符串s 与text 中的词汇 |
| s.split(t) | 在所有找到t 的位置将s 分割成链表(默认为空白符) |
| s.splitlines() | 将s 按行分割成字符串链表 |
| s.lower() | 将字符串s 小写 |
| s.upper() | 将字符串s 大写 |
| s.titlecase() | 将字符串s 首字母大写 |
| s.strip() | 返回一个没有首尾空白字符的s 的拷贝 |
| s.replace(t, u) | 用u 替换s 中的t |
链表与字符串的差异
1.字符串和链表之间不能连接
2.我们使用一个for 循环来处理读入文件(对应的文件内容对应一个字符串),所有我们可以挑选出的只是单个的字符——我们不选择粒度;链表中的元素可以很大也可以很小,它们可能是段落、句子、短语、单词、字符。链表的优势在于我们可以灵活的决定它包含的元素,相应的后续的处理也变得灵活
3.我们在一段NLP 代码中可能做的第一件事情就是将一个字符串分词放入一个字符;当我们要将结果写入到一个文件或终端,我们通常会将它们格式化为一个字符串
4.字符串是不可改变的:一旦你创建了一个字符串,就不能改变它。链表是可变的,内容可以随时修改
3.3 使用 Unicode 进行文字处理
什么是 Unicode?
编码点:每个字符分配一个编号;python中编码点写作\uXXXX 的形式,其中XXXX 是四位十六进制形式数。
字节流:
解码:将文本翻译成Unicode——翻译成Unicode
编码:将Unicode 转化为其它编码的过程
Unicode的角度看字符:,字符是可以实现一个或多个字形的抽象的实体。只有字形可以出现在屏幕上或被打印在纸上。一个字体是一个字符到字形映射。
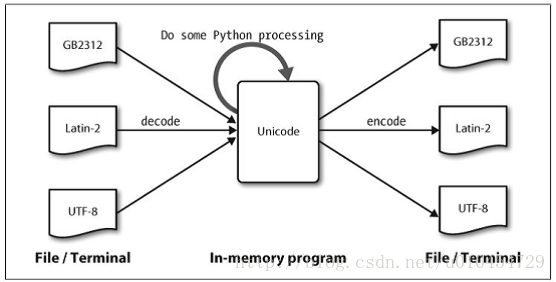
Unicode 的解码和编码
从文件中提取已编码文本
nltk.data.find()函数:定位文件
import nltk
path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')codecs模块:提供了将编码数据读入为Unicode 字符串和将Unicode 字符串以编码形式写出的函数。
codecs.open()函数:encoding 参数来指定被读取或写入的文件的编码。
unicode_escape编码:Python的一个虚拟的编码;把所有非ASCII 字符转换成它们的\uXXXX 形式。
path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
f=codecs.open(path,encoding='latin2')
#print f
#似乎调用出错,还是说没有将f读出来以Unicode返回
#f2=codecs.open(path,'w',encoding='utf-8')
#print f2
#文件对象f 读出的文本将以Unicode 返回
for line in f.readlines():
line=line.strip()
print line.encode('unicode_escape')
Unicode 字符串常量:在字符串常量前面加一个u,
ord()函数:查找一个字符的整数序列。如ord('a')
>>> a=u'\u0062' #对其进行转义
>>> a
u'b'
>>> print a
bprint 语句:假设Unicode 字符的默认编码是ASCII 码。
repr()函数:转化的字符串,输出utf-8转义序列(以\xXX的形式)
nacute = u'\u0144'
nacute_utf = nacute.encode('utf8')
print nacute
print repr(nacute_utf)unicodedata模块:检查Unicode 字符的属性。
在 Python中使用本地编码
pass
3.4 使用正则表达式检测词组搭配
使用基本的元字符
美元符号$:用来匹配单词的末尾;
乘方符号^:用来匹配单词的开始;
符号“?”:表示前面的一个字符可选;
通配符“.”:匹配任何单个字符。«^e-?mail $»将匹配email 和e-mail
例1:查找以ed结尾的词汇,《ed$》
例2:假设我们有一个8 个字母组成的词的字谜室,j 是其第三个字母,t 是其第六个字母。
例3:计数一个文本中出现email 或e-mail的次数,
import re,nltk
wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()]
print [w for w in wordlist if re.search('ed$',w)]
print [w for w in wordlist if re.search('^..j..t..$',w)]
print sum(1 for w in text if re.search('^e-? mail$',w))
#用IDLE运行有点慢,直接用命令窗口的话,更快。。。范围与闭包
手机输入法联想提示:例如,hole 和golf 都是通过输入序列4653。
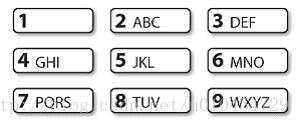
T9:9 个键上的文字
闭包:+、*
“+”:前面的项目的一个或多个实例
“*”:前面的项目的零个或多个实例
“^”:出现在方括号内的第一个字符位置查找非元音字母组成的词汇:«^[^aeiouAEIOU]+$»
例1:按键4653,产生哪些相同的序列单词?
[w for w in wordlist if re.search('^[ghi][mno][jlk][def]$',w)]
#以g或者h或者i开头,以d或者e或者f结尾的,并且第二个字符是m,n,o中的一个,第三个字符是j,l,k中的一个
例2:“+”符号的使用
chat_words = sorted(set(w for w in nltk.corpus.nps_chat.words()))
print [w for w in chat_words if re.search('^m+i+n+e+$', w)] #1个或者多个m,i,n,e,并且以m开头,e结尾
print [w for w in chat_words if re.search('^[ha]+$', w)] #以ha开头,并且有1一个或者多个ha,
'''
[u'miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee', u'miiiiiinnnnnnnnnneeeeeeee', u'mine', u'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee']
[u'a', u'aaaaaaaaaaaaaaaaa', u'aaahhhh', u'ah', u'ahah', u'ahahah', u'ahh', u'ahhahahaha', u'ahhh', u'ahhhh', u'ahhhhhh',
u'ahhhhhhhhhhhhhh', u'h', u'ha', u'haaa', u'hah', u'haha', u'hahaaa', u'hahah', u'hahaha', u'hahahaa', u'hahahah', u'hahahaha',
u'hahahahaaa', u'hahahahahaha', u'hahahahahahaha', u'hahahahahahahahahahahahahahahaha', u'hahahhahah', u'hahhahahaha']
'''
wsj = sorted(set(nltk.corpus.treebank.words()))
print [w for w in wsj if re.search('^[0-9]+\.[0-9]+$',w)] #任何带小数点的符号数
print [w for w in wsj if re.search('^[A-Z]+\$$',w)] #以$结尾,前面有1个或者多个大写字母
print [w for w in wsj if re.search('^[0-9]{4}$',w)] #XXXX年
print [w for w in wsj if re.search('^[0-9]+-[a-z]{3,5}$',w)] #['10-day', '10-lap', '10-year', '100-share', '12-point', '12-year', ...]
print [w for w in wsj if re.search('^[a-z]{5,}-[a-z]{2,3}-[a-z]{,6}$',w)]
#['black-and-white', 'bread-and-butter', 'father-in-law', 'machine-gun-toting','savings-and-loan']
print [w for w in wsj if re.search('(ed|ing)$',w)] #以ed或者ing结尾的单词或者符号“\.”:匹配一个句号。
大括号表达:如{3,5},表示前面的项目重复指定次数。
管道字符:从其左边的内容和右边的内容中选择一个。
圆括号:表示一个操作符的范围,它们可以与管道(或叫析取)符号一起使用,如:«w(i|e|ai|oo)t»,匹配wit、wet、wait 和woot。
表:正则表达式基本元字符,其中包括通配符,范围和闭包
| 操作符 | 行为 |
| · | 通配符,匹配所有字符 |
| ^abc | 匹配以abc 开始的字符串 |
| abc$ | 匹配以abc 结尾的字符串 |
| [abc] | 匹配字符集合中的一个 |
| [A-Z0-9] | 匹配字符一个范围 |
| ed|ing|s | 匹配指定的一个字符串(析取) |
| * | 前面的项目零个或多个,如a*, [a-z]* (也叫Kleene 闭包) |
| + | 前面的项目1 个或多个,如a+, [a-z]+ |
| ? | 前面的项目零个或1 个(即:可选)如:a?, [a-z]? |
| {n} | 重复n 次,n 为非负整数 |
| {n,} | 至少重复n 次 |
| {,n} | 重复不多于n 次 |
| {m,n} | 至少重复m 次不多于n 次 |
| a(b|c)+ | 括号表示操作符的范围 |
原始字符串:前缀"r";例如:原始字符串r'\band\b'包含两个“\b”符号会被re 库解释为匹配词的边界而不是解释为退格字符。
3.5 正则表达式的有益应用
提取字符块
这篇关于《python自然语言处理》笔记---chap3加工原料文本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




