本文主要是介绍浦语大模型笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
书生·浦语大模型全链路开源体系
- 浦语大模型全链路开源体系
- 大模型成为发展通用人工智能的重要途径
- 书生·浦语 2.0(InternLM2)核心理念
- 书生·浦语 2.0(InternLM2)的主要亮点
- 主要亮点 1:超长上下文支持
- 主要亮点 2:性能全方位提升
- 主要亮点 3:优秀的对话和创作体验
- 主要亮点 4:工具调用能力升级
- 主要亮点 5:数理能力突出
- 从模型到应用典型流程
- 书生·浦语全链条开源开放体系
- 全链条开源开放体系|数据
- 全链条开源开放体系|开放高质量语料数据
- 全链条开源开放体系|预训练
- 全链条开源开放体系|微调
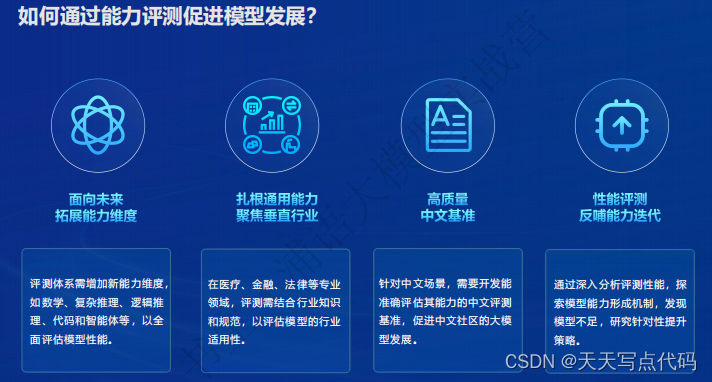
- 全链条开源开放体系|评测
- 全链条开源开放体系|部署
- 全链条开源开放体系|智能体
浦语大模型全链路开源体系
大模型成为发展通用人工智能的重要途径
- 专用模型:针对特定任务,一个模型解决一个问题
- 通用大模型:一个模型应对多种任务、多种模态
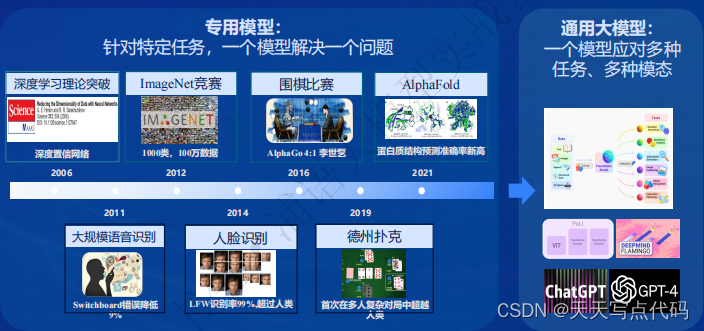
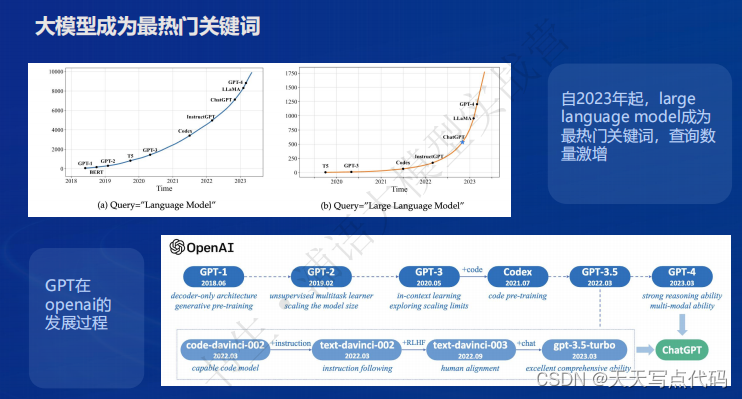
- 大模型发展时间线
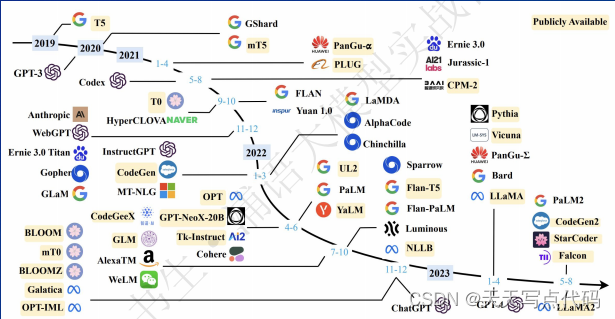
- LLaMA 模型家族
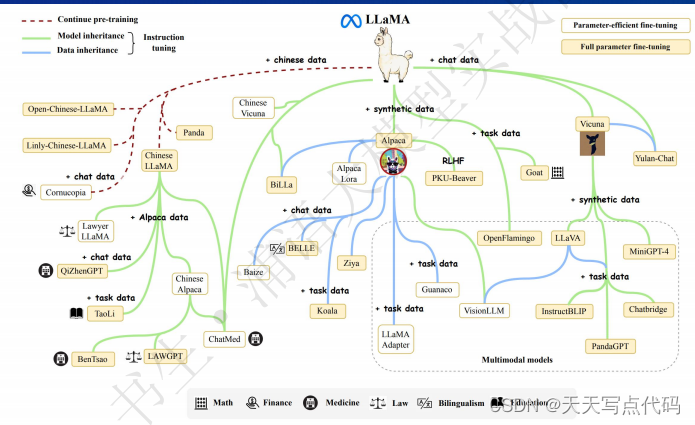
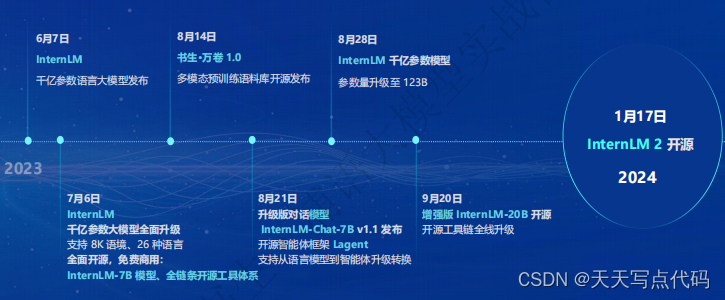
- 书生·浦语大模型开源历程
书生·浦语 2.0(InternLM2)核心理念
- 面向不同的使用需求 ,每个规格包含三个模型版本
7B:为轻量级的研究和应用提供了一个轻便但性能不俗的模型
20B:模型的综合性能更为强劲,可有效支持更加复杂的实用场景
- InternLM2-Base
高质量和具有很强可塑性的模型基座是模型进行深度领域适配的高质量起笈
- InternLM2
在 Base 基础上,在多个能力方向进行了强化 ,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座
- InternLM2-Chat
在 Base 基础上,经过 SFT 和 RLHF,面向对话交互进行了优化,具有很好的指令遭循、共情聊天和调用工具等的能力
- 回归语言建模的本质
- 致力于通过更高质量的语料以及更高的信息密度,实现模型基座语言建模能力的质的提升

书生·浦语 2.0(InternLM2)的主要亮点

主要亮点 1:超长上下文支持
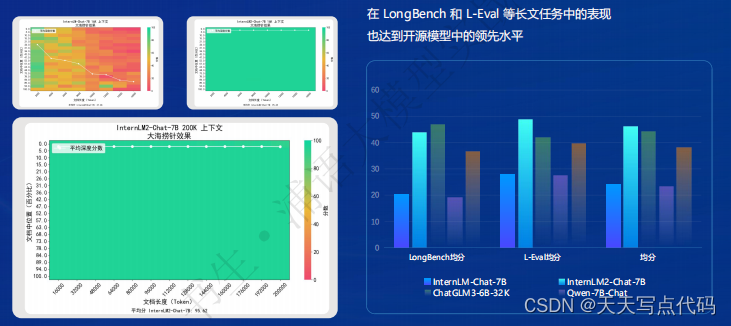
模型在 20 万字长输入中几乎完美地实现长文“大海捞针”
主要亮点 2:性能全方位提升
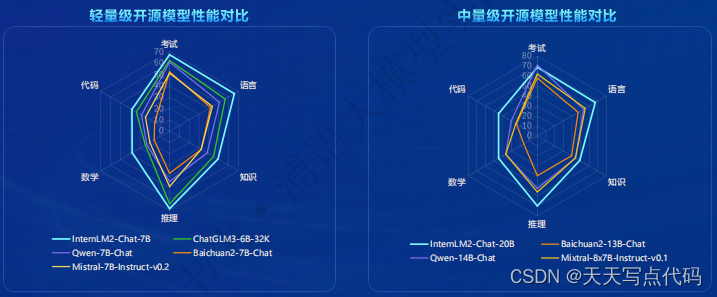
在各能力维度全面进步,在推理、数学、代码等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上 InternLM2-Chat-20B 甚至可以达到比肩 ChatGPT (GPT-3.5)的水平
主要亮点 3:优秀的对话和创作体验
- 贴心又可靠的 Al 助手
- 充满人文关怀的对话
- 富有想象力的创作
AlpacaEval2 英文主观对话榜单(斯坦福大学发布)IntemLM2-Chat-20B胜率(21.75%)超越了 GPT-3.5(14.13%),GeminiPro(16.85%)和Claude-2 (17.19%)
指令遵循能力评测集 IFEval(谷歌发布): InternLM2-Chat-208 的指令遵循率超越了 GPT-4(79.5%vs 79.3%)



主要亮点 4:工具调用能力升级
工具调用能够极大地拓展大语言模型的能力边界 ,使得大语言模型能够通过搜索、计算、代码解释器等获取最新的知识并处理更加复杂的问题。InternLM2进一步升级了模型的工具调用能力,能够更稳定地进行工具筛选和多步骤规划,完成复杂任务
主要亮点 5:数理能力突出
- 强大的内生计算能力
在预训练阶段,模型吸收了丰富的数学相关的语料,在微调阶段模型全面学习了覆盖不同学段各类知识点的题目,使得模型内生的计算能力得到了大大增强

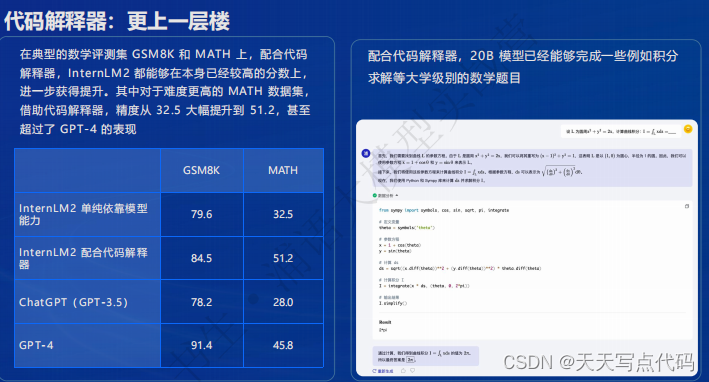
- 代码解释器:更上一层楼
借助代码解释器,模型能够编写代码进行更复杂的计算,或者对推理的结果进行形式化验证,从而可以解决计算要求更高或者演算过程更加复杂的问题
- 数据分析和可视化
基于在计算及工具调用方面强大的基础能力,InternLM2在语言模型中具备了数据分析和可视化实用能力,进一步贴近用户使用场景

从模型到应用典型流程
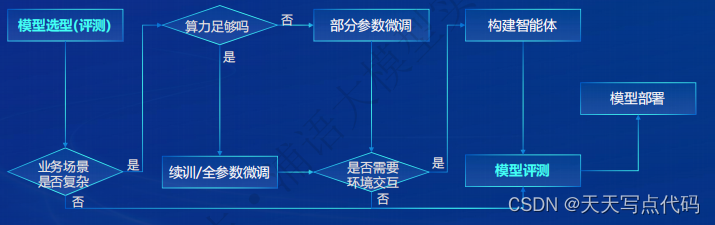
书生·浦语全链条开源开放体系
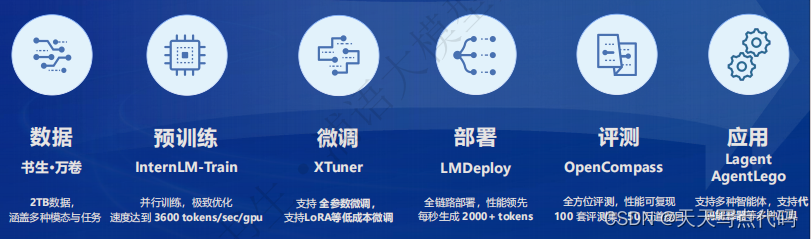
全链条开源开放体系|数据

全链条开源开放体系|开放高质量语料数据

全链条开源开放体系|预训练

全链条开源开放体系|微调

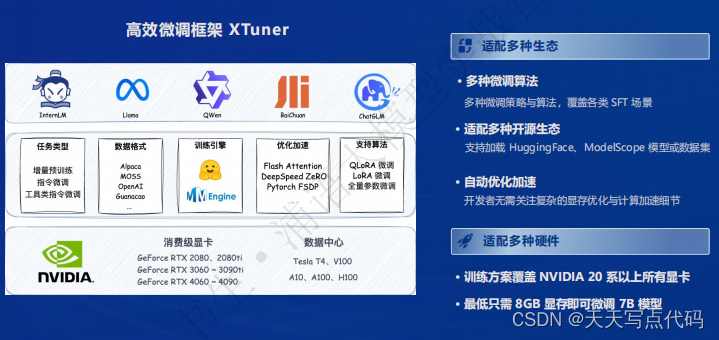

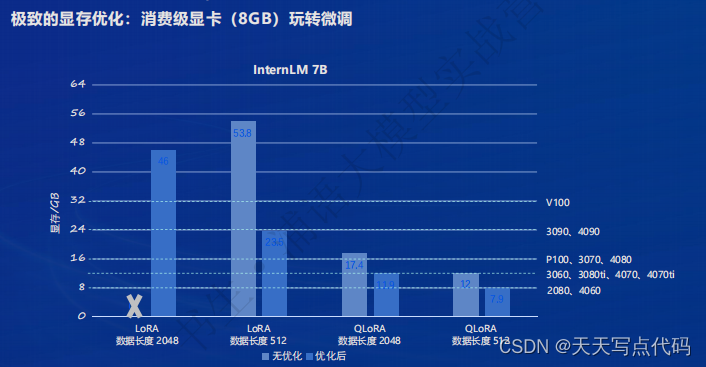
全链条开源开放体系|评测

-
OpenCompass 2.0 司南大模型评测体系开源历程


-
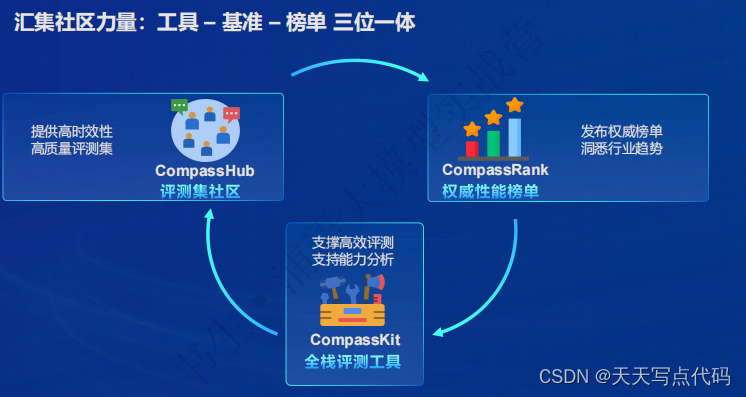
CompassRank:中立全面的性能榜单
-
CompassKit:大模型评测全栈工具链

-
CompassHub:高质量评测基准社区
-
OpenCompass 2.0 能力维度全面升级

-
夯实基础:自研高质量大模型评测基准
-
洞见未来:年度榜单与能力分析
-
洞见未来:OpenCompass 年度榜单(主观评测-对战胜率)
-
洞见未来:OpenCompass 年度榜单(综合性客观评测)
-
群策群力:携手行业领先共建繁荣生态
全链条开源开放体系|部署


全链条开源开放体系|智能体

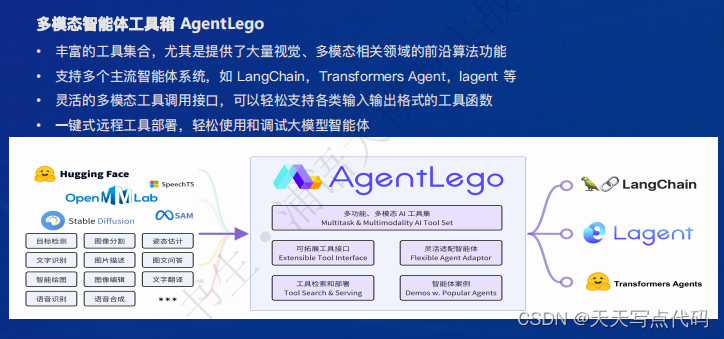
这篇关于浦语大模型笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







