本文主要是介绍批量处理文件,高效分发数据:一键操作解决繁琐工作的技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在数字化时代,文件处理和数据分发已经成为许多行业日常工作中不可或缺的一部分。然而,面对大量的文件和数据,传统的手动处理方式往往显得繁琐且效率低下。幸运的是,现代技术为我们提供了办公提效工具批量处理文件,高效分发数据的解决方案,一键操作即可解决这些繁琐工作。
高效分发数据是提高工作效率的关键。传统的数据分发方式可能需要手动复制、粘贴或发送文件,这在处理大量数据时显得尤为繁琐。然而,现代的数据分发工具可以实现自动化和智能化的数据分发,让数据传递更加高效和准确。

文件批量处理分发的操作方法:
步骤1、执行办公提效工具进入主界面,并点击“文件批量处理”功能。
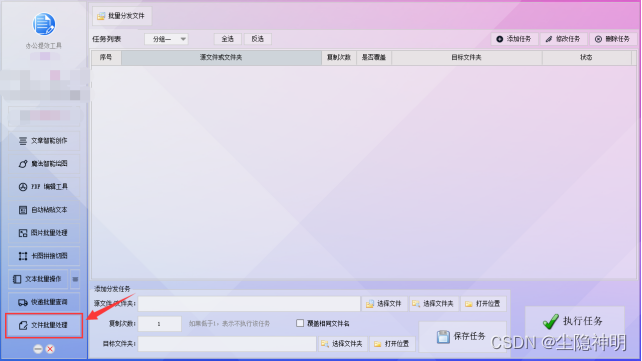
步骤2、在“添加分发任务”版块中,点击“选择文件”找到文件路径并点击“打开”。

步骤3、根据需求设置复制的次数。(低于1,表示不执行该任务)
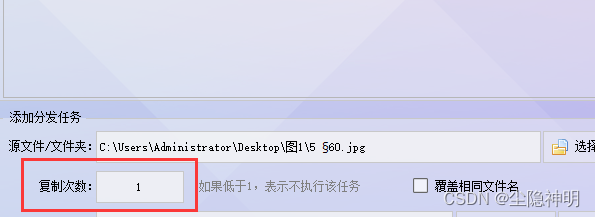
步骤4、设置目标文件夹,通过“选择文件夹”来设定路径保存。
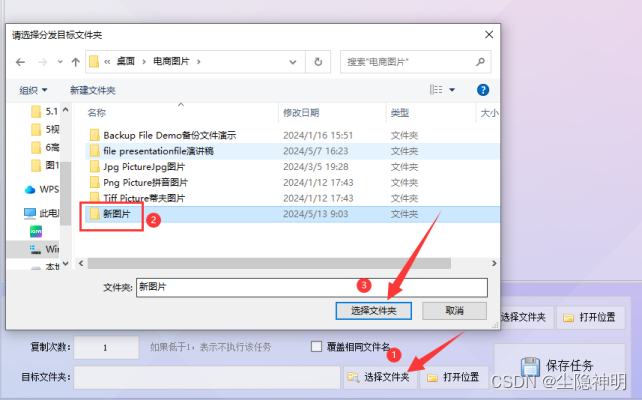
步骤5、都设置好后,点击“保存任务”。
步骤6、已设置的任务显示在任务列表中,可通过面板上的“添加任务、修改任务、删除任务”,继续操作。
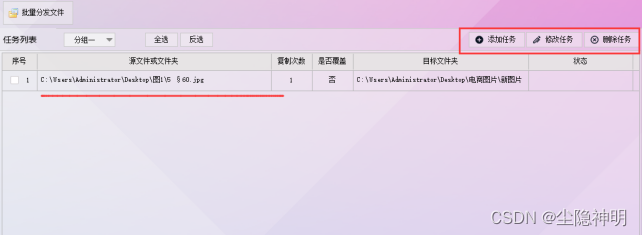
步骤7、确定所有任务都添加完成后,在界面上点击“执行任务”。
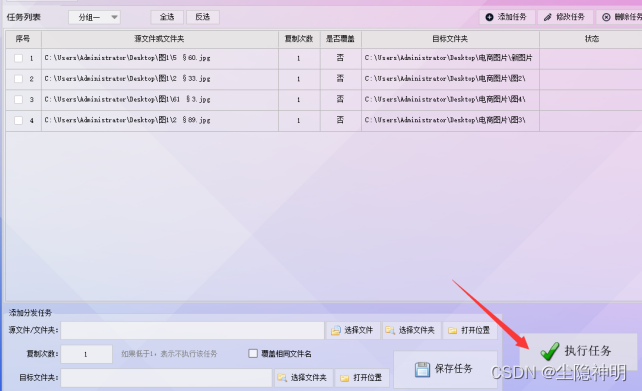
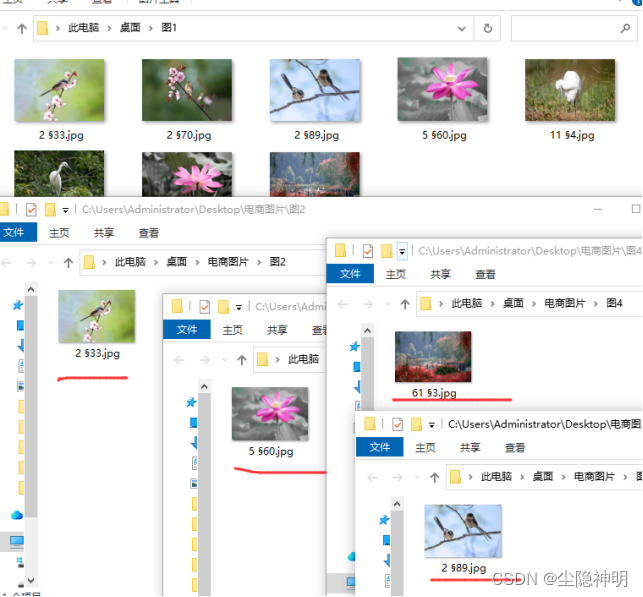
步骤8、打开目标文件夹检查下是否把文件分发到位。
批量处理文件,高效分发数据是现代工作中解决繁琐任务的重要技巧。掌握使用方法并关注数据安全性,您可以轻松实现一键操作,提高工作效率,从而有更多时间和精力专注于更重要的工作。希望本文对您有所启发和帮助,祝您在工作中取得更大的成功!
这篇关于批量处理文件,高效分发数据:一键操作解决繁琐工作的技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





