本文主要是介绍搭建hadoop2.5.2/Ubuntu12集群(完全分布式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 用户(ts)获取root权限:vi /etc/passwd (ts:x:1000:1000:crystal:/home/ts:/bin/bash 将两个1000改成0)
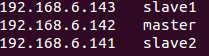
2. 修改hostname:gedit /etc/hostname (分别为master(namenode),slave1,slave2(datanode))
3. 设置hosts:gedit /ect/hosts
4. 安装SSH:sudo apt-get install ssh
5. 设置无密码登录:产生密钥
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
导入authorized_keys
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
测试 ssh localhost

把slave的id_dsa.pub,copy到master,并导入到authorized_keys

6. 安装JDK
解压: tar -zxvf jdk-7u79-linux-x64.tar.gz
移动到安装目录:mv jdk /usr/lib/jvm/java-7-sun
配置:gedit /etc/environment 添加--/usr/lib/jvm/java-7-sun/bin:
二. 安装Hadoop
1. 创建文件
2. 解压文件
tar zxvf hadoop-2.5.2.tar.gz
mv hadoop /usr/lib/jvm/hadoop

3. 修改配置文件(目录:hadoop/etc/hadoop)
1. hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-sun
2. yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-sun
3. slaves
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/home/ts/tmp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.aboutyun.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.aboutyun.groups</name><value>*</value></property>
</configuration>5. hdfs-site.xml
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:9001</value></property><property><name>dfs.namenode.name.dir</name><value>file:/home/ts/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/home/ts/dfs/data</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>
</configuration>
6. mapred-site.xml
<configuration><property> <name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>
7. yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property>
</configuration>
4. copy到其它节点 /
scp -r /usr/lib/jvm/hadoop root@slave1:/usr/lib/jvm/
scp -r/usr/lib/jvm/hadoop root@slave2:/usr/lib/jvm/
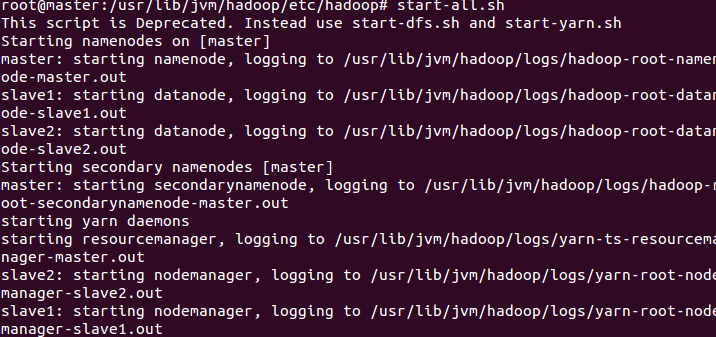
5. 测试
格式化namenode:hadoop namenode format
启动:start-all.sh
查看:




这篇关于搭建hadoop2.5.2/Ubuntu12集群(完全分布式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







