本文主要是介绍使用train.py----yolov7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
准备工作
在训练之前,数据集的工作和配置环境的工作要做好
数据集:看这里划分数据集,训练自己的数据集。_划分数据集后如何训练-CSDN博客
划分数据集2,详细说明-CSDN博客
配置环境看这里
从0开始配置环境-yolov7_gpu0是inter gpu1是nvidia 深度学习要用哪个-CSDN博客
参数设置工作
首先就是数据集 , 我之前写的划分数据集的那个文件夹,还有data.yaml文件要设置好,然后将这两个文件放在项目文件夹下面,注意放的位置
给大家做个参考,我把我的放在了
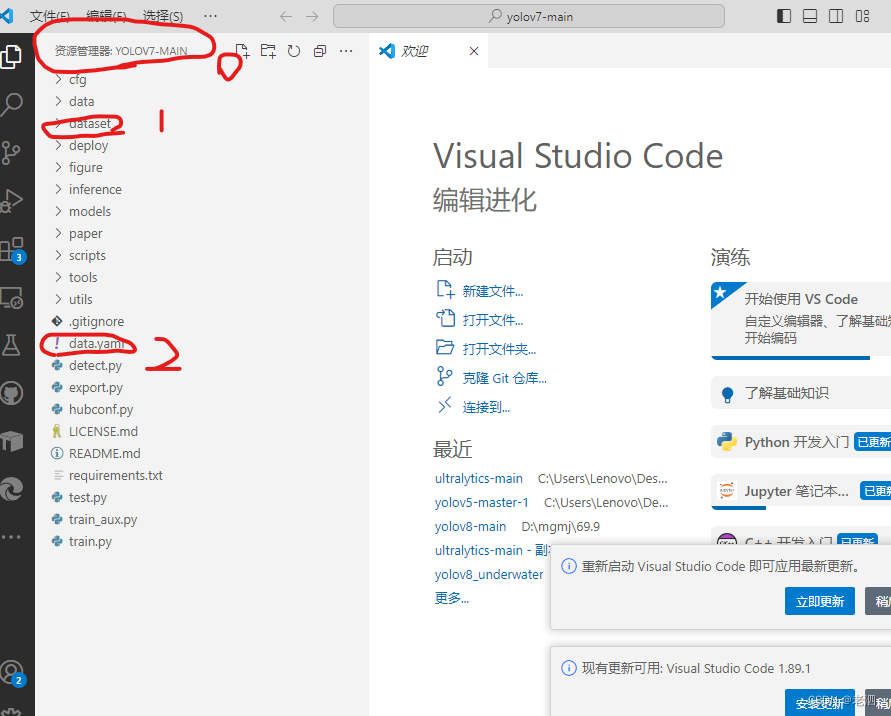
0代表着我的项目文件夹名称
1和2就是我说的这两个文件
在这之后吗,再说其他工作
train.py参数设置
打开train.py文件,往下拉到这
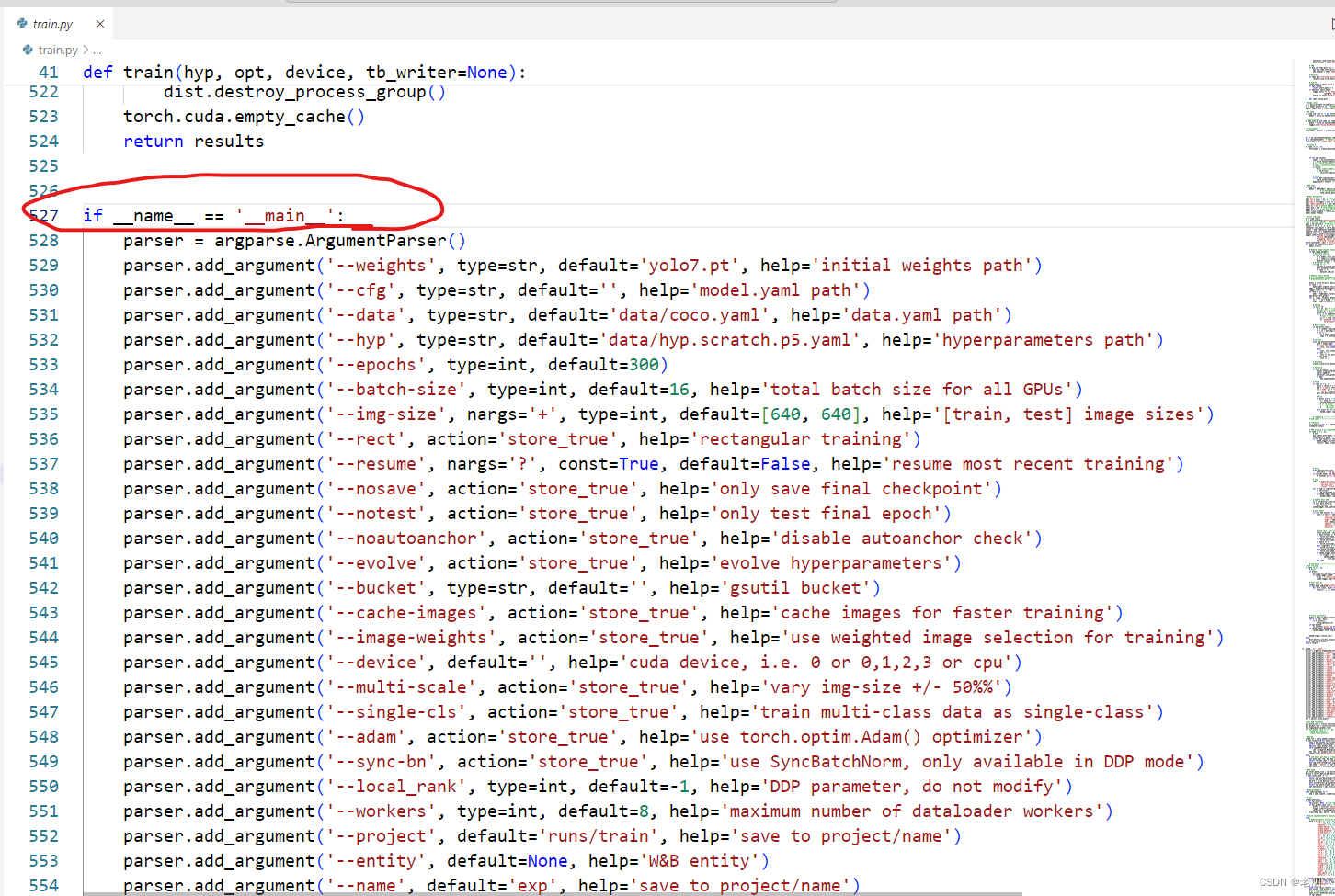
如果找不到的话,安住ctrl+F键,输入 __main__
就可以搜索到
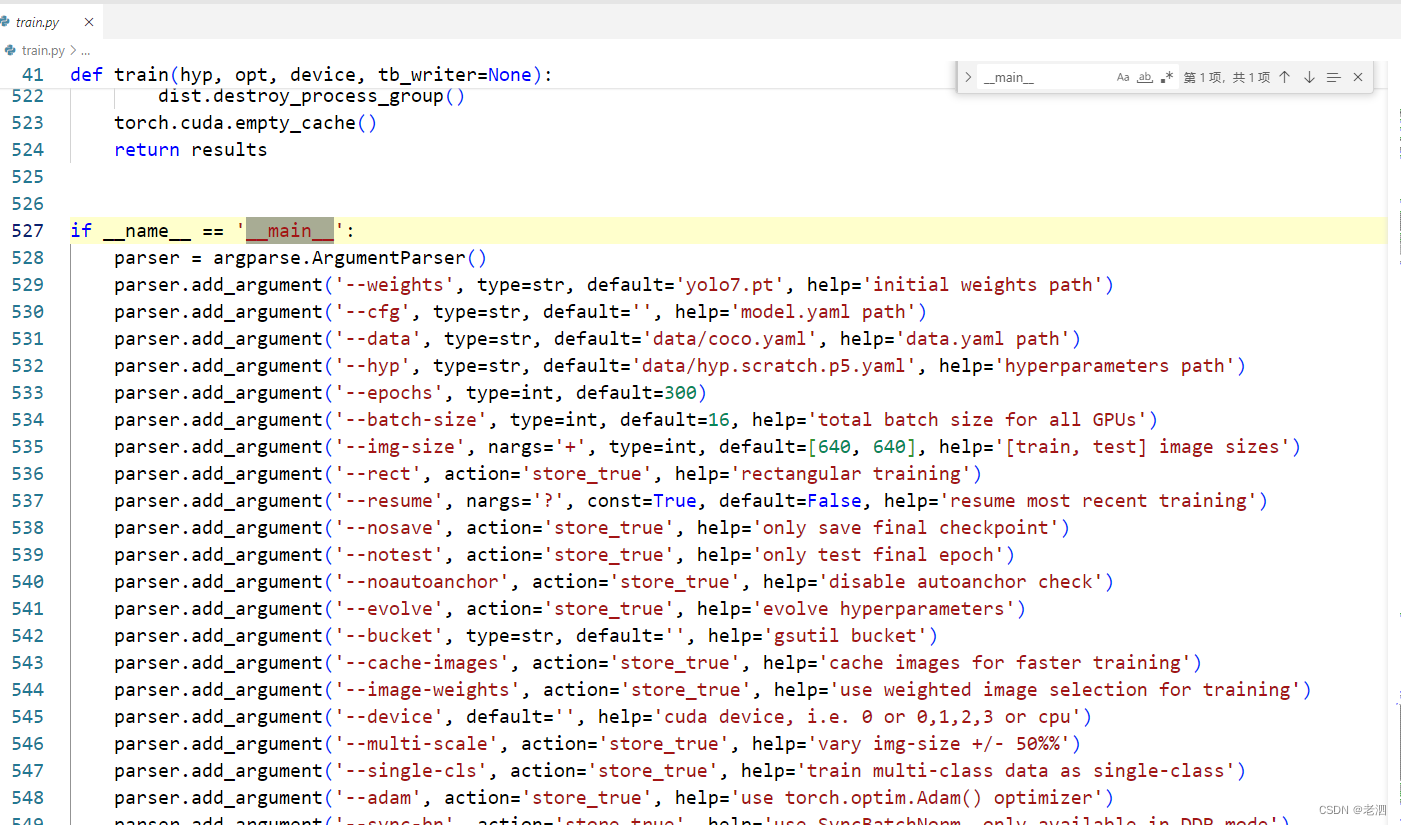
接下来是参数的设置了
weights设置
第一个是weights ,表示的是预训练权重,这这个东西好比说是让现在训练的模型有一些训练的经验,这样会使得训练精度有一定的提升,但是不一定说一定比没有预训练权重的好,一般来说都要好一些,这个是需要下载预训练权重的,这个东西在github下载的时候那里可以下载,

这几个画圈的蓝色字体点击就可以下载的。一般来说就下载第一个就可以了,其他的参数量大,对电脑的性能要求高。
这里我给一个百度云链接,可以从这下载
链接:https://pan.baidu.com/s/1AKN_gQwnxiyOEVqn7N0rIg?pwd=hi49
提取码:hi49
下载下来之后,就放在项目文件夹下面就行了,这样就不用改文件路径了,
参考我的位置。
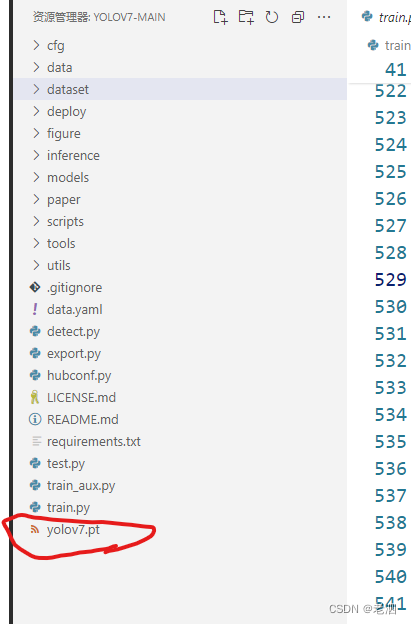
如果不使用预训练权重的画,就

这里面的字删了,改成这样

就可以了,记得改完了保存一下
cfg设置
cfg就是yolov7.yaml这种文件,我们下载的官方代码,这个文件的路径在

只需要右键这个文件,复制相对路径就可以了
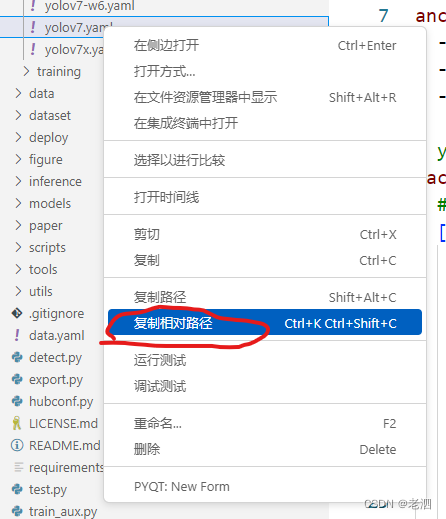
粘贴在这

这里要注意,每次复制路径的时候,要把\换成/,就是 cfg/deploy/yolov7.yaml

data设置
这个就是我之前说的数据集弄的那个文件,我放在了主目录文件下,就是

hyp设置
这个是一些超参数的设置,一般别动就行了
epochs设置
这个就是说的跑多少轮,现在默认是300轮,我建议一般的话先跑个100轮先试试,完了之后看看结果咋样,就是那个精度曲线,最后平的话就不用再跑了,如果还有上升的趋势的话就可以设置200再跑跑试试。
![]()
batch-size设置
这个和自己的设备有关系,如果用显卡的话,先看一下自己的显存是多少,
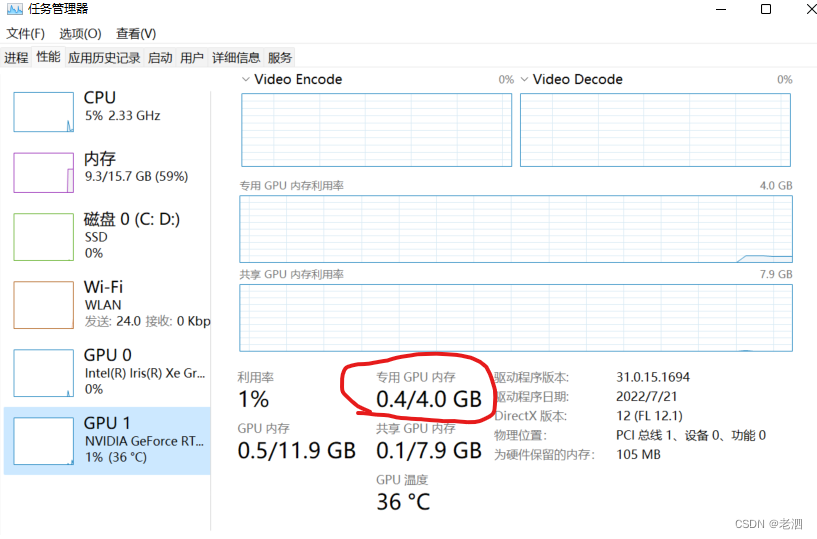
我的电脑显存是4G大小,这个参数的设置一般都是2的指数倍,
举个例子,假如我设置为4,我在运行代码的时候会显示显存占用的大小,比如是1.5G大小,那么我的batch-size就可以在当前设备情况下开到8,这样就可以最大的发挥显卡的使用率,跑到速度快一些。
这里我建议先试试4,再根据情况去做调整

device设置
这里就是选择设备去训练的那个参数,如果有显卡的话,我的电脑为例子,我就一个显卡,这里是从0开始计数的,我就输入0,代表着用第一块显卡训练参数,如果你有两个显卡,就输入0,1
![]()
workers设置
这个来说,一般windows系统设置0就行了,这个设置别的有时候会报错
这个对训练没啥影响。

最后
一般就这几个参数设置就可以了,在训练的时候,先选择自己的环境。训练有两种方法,一个是在终端输入指令训练,一个是点击训练按钮训练。
使用终端训练
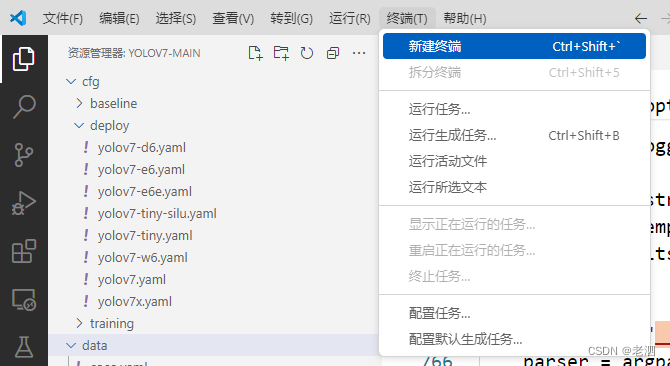
先新建终端,然后激活自己的环境
我的这个项目配置的环境名字叫yolov7,所以我的指令是
conda activate yolov7 
1代表着当前选择的环境名字,
2代表着当前文件位置,这个一般都是当前项目文件夹的位置
输入
python train.py按回车,就开始加载训练数据了

显示这个就是说在训练了
使用编译器训练
如果你会使用终端的话,这个就别看了
先在编辑器选择环境
我使用的是vscode,选择我配置的yolov7环境
在选择之后,右下角会显示当前的环境名称
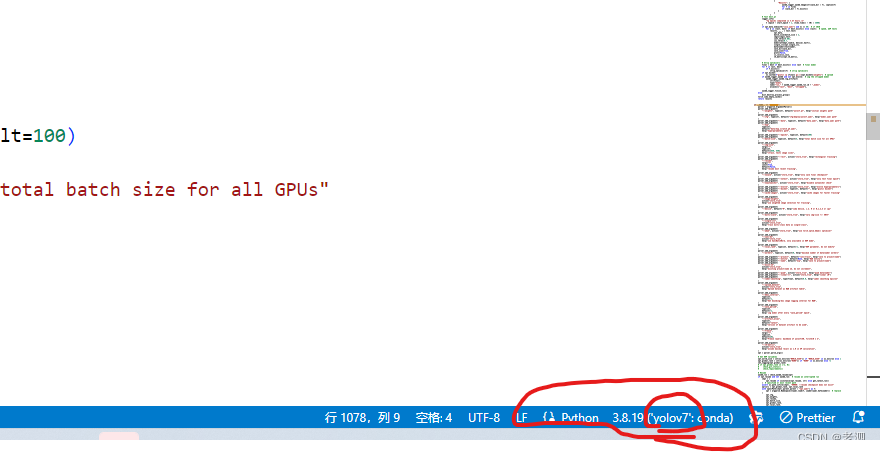
右键,运行python就可以
或者直接点击训练按钮
训练文件查看
运行之后会生成run文件夹,你往里面选择你训练的就行了,他这个是自动命名字的,选择对应的就可以了

这篇关于使用train.py----yolov7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





