本文主要是介绍计算机视觉——基于改进UNet图像增强算法实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 引言
在低光照条件下进行成像非常具有挑战性,因为光子计数低且存在噪声。高ISO可以用来增加亮度,但它也会放大噪声。后处理,如缩放或直方图拉伸可以应用,但这并不能解决由于光子计数低导致的低信噪比(SNR)。短曝光图像受到噪声的影响,而长曝光可能会引起模糊,通常也不切实际。已经提出了各种去噪、去模糊和增强技术,但在极端条件下,如夜间视频速率成像,它们的有效性是有限的。有物理手段可以增加低光照下的SNR,包括打开光圈、延长曝光时间以及使用闪光灯。但每种方法都有其特有的缺点。例如,增加曝光时间可能会因为相机抖动或物体运动引入模糊。

为了支持基于学习的低光照图像处理流程的开发,我们正在处理See-in-the-Dark(SID)数据集,它包含原始的短曝光低光照图像,以及相应的长曝光参考图像。使用所呈现的数据集,我们开发了一个处理低光照图像的流程,该流程基于端到端训练的全卷积网络。该网络直接在原始传感器数据上操作,并取代了在这些数据上表现不佳的传统图像处理流程。
原文:https://medium.com/@arijitdey3410/learning-to-see-in-the-dark-using-convolutional-neural-network-4c03766bfd8
2. 现有的经典图像处理技术
2.1图像去噪
图像去噪是低级视觉中一个发展成熟的主题。有一些最先进的方法使用诸如全变分、小波域处理、稀疏编码、核范数最小化和3D变换域滤波(BM3D)等技术。这些方法通常基于特定的图像先验,如平滑性、稀疏性、低秩或自相似性。不幸的是,大多数现有方法已经在合成数据上进行了评估,例如添加了高斯噪声或椒盐噪声的图像。最近一项对真实数据的仔细评估发现,在真实图像上,BM3D的性能超过了更近期的技术。
2.2 低光照图像增强
已经应用了各种技术来增强低光照图像的对比度。一个经典的选择是直方图均衡化,它平衡了整个图像的直方图。另一种广泛使用的技术是伽马校正,它增加了暗区的亮度,同时压缩了亮像素。更先进的方法执行更全局的分析和处理,例如使用逆暗通道先验、小波变换、Retinex模型和照明图估计。
图1:经典图像处理技术
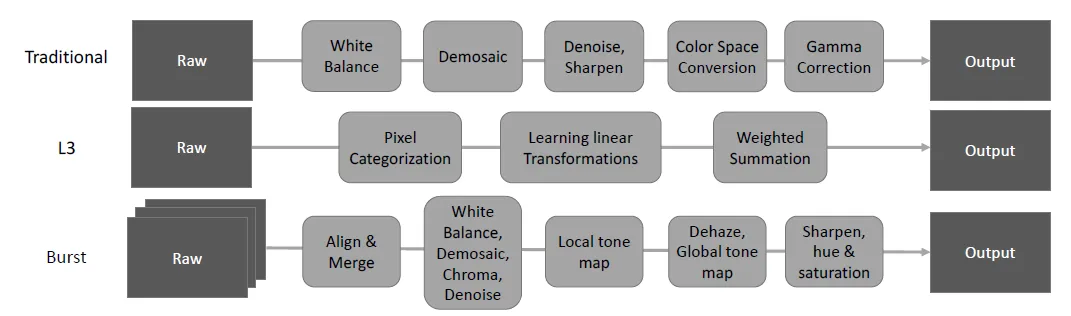
然而,研究人员还探索了将深度网络应用于去噪,包括堆叠稀疏去噪自编码器(SSDA)、可训练的非线性反应-扩散(TNRD)、多层感知器、深度自编码器和卷积网络。当在特定噪声水平上训练时,这些数据驱动的方法可以与最先进的经典技术如BM3D和稀疏编码相媲美。
3. See-in-the-Dark 数据集
See-in-the-Dark(SID)数据集包含1865张原始短曝光图像,每张图像都有相应的长曝光参考图像。请注意,多个短曝光图像可以对应于同一个长曝光参考图像。例如,我们收集了一系列短曝光图像来评估突发去噪方法。序列中的每张图像都被视为一个独特的低光照图像,因为每张图像都包含真实的成像伪影,并且对于训练和测试都是有用的。SID中不同长曝光参考图像的数量是424。

该数据集包含室内和室外图像。室外图像通常在夜间捕获,月光或路灯下。室外场景中相机的照度通常在0.2 lux到5 lux之间。室内图像甚至更暗。它们是在关闭房间内,关闭常规灯光,并为此目的设置的微弱间接照明下捕获的。室内场景中相机的照度通常在0.03 lux到0.3 lux之间。
4. 全连接深度学习模型实现
4.1. 流程
为了提升低光照条件下单张图像的直接处理能力,我们设计并构建了一个深度学习网络,该网络采用端到端的学习方式,能够快速处理这类图像。具体而言,我们训练了一个全卷积网络(FCN),来完成整个图像处理的流程。近期的研究表明,纯粹的FCN能够有效地实现众多图像处理算法,这一发现激发了我们的灵感,并促使我们探索这种方法在极低光照成像领域的应用。
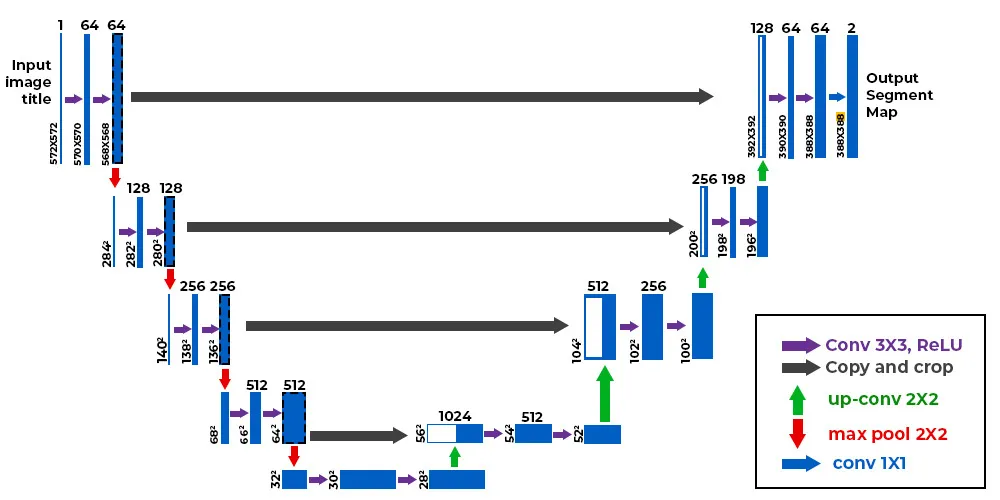
经过初步的探索,我们决定专注于两种全卷积网络的通用架构,它们构成了我们流程的核心:一种是最近在快速图像处理中采用的多尺度上下文聚合网络(CAN),另一种是U-Net。尽管其他研究工作探讨了残差连接的应用,但我们在当前的实验设置中并未发现其带来显著益处,这可能是因为我们的输入和输出图像采用了不同的颜色空间。此外,我们还考虑了内存消耗的问题,因此选择了能够在GPU内存中处理全分辨率图像(如4240×2832或6000×4000分辨率)的架构。基于这些考虑,我们避免了使用需要处理小图像块并重新组合的全连接层。最终,我们选择U-Net作为默认的网络架构。
图2:通用U-Net架构
4.2. 训练
- 训练策略:网络的训练是从零开始的,这意味着没有使用任何预训练的权重。他们选择了L₁损失函数和Adam优化器来进行网络的优化。
- 输入与输出:在训练过程中,网络接收的输入是短曝光图像的原始数据,而期望的输出(即地面真实)是相应的长曝光图像。这些长曝光图像通过libraw库处理,libraw是一个专门用于原始图像处理的软件库。
- 针对不同相机的网络训练:考虑到不同相机可能有不同的成像特性,他们为每个相机分别训练了一个网络。
- 数据增强:为了提高网络的泛化能力,他们在每次迭代中采用一个256×256像素的图像补丁,并引入了随机翻转和旋转作为数据增强手段。
- 学习率调整:初始学习率设置得相对较小,为10⁻³。如果在过去的三个周期中学习率保持不变,它会通过乘以一个常数因子0.2来减少,这是一种常见的学习率衰减策略,用于避免陷入局部最小值并加快收敛。
- 训练周期:标准的训练周期设置为60个epoch,但为了达到更优的性能,训练周期可以延长至100个epoch或者更多。
通过这种训练方法,网络能够学习如何从短曝光的低光照图像中恢复出高质量的视觉效果,以匹配长曝光图像的细节和清晰度。
5. 实验结果
(a) 经典方法
一旦我们遵循了使用块匹配和3D去噪的经典方法,我们得到了如下的输出:
图4:使用BM3D(块匹配和3D去噪)增强后的输出

我们通过这种方法获得的PSNR是15.64 dB。
我们还选择了另一种方法,称为使用改进的暗通道和大气散射的图像去雾。输出如下:
图5:图像去雾增强后的输出

然而,在应用这种方法后,PSNR显著提高(17.10 dB)。
(b) 使用CNN的基于深度学习的方法:
传统方法没有产生更好的暗图像重建,我们可以确定相应的PSNR。然而,使用U-Net架构的最新CNN模型提供了远更好的结果,我们可以在这里观察到。
2个周期后的输出
图6:从左到右:输入短曝光图像,地面真实长曝光图像,预测输出
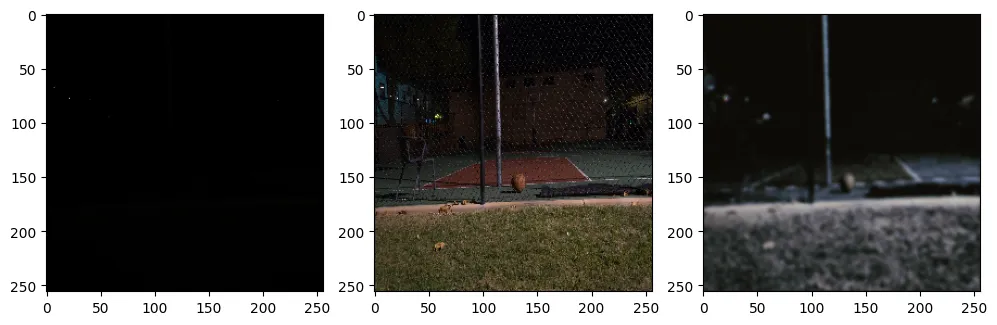
10个周期后的输出
图7:从左到右:输入短曝光图像,地面真实长曝光图像,预测输出
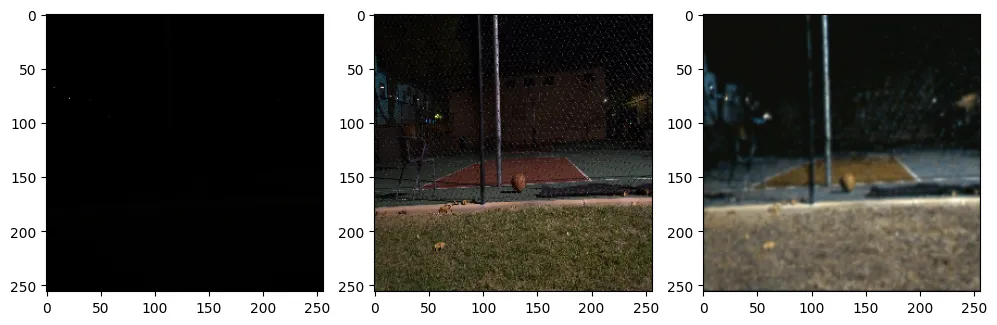
40个周期后的输出
图8:从左到右:输入短曝光图像,地面真实长曝光图像,预测输出

遵循这种基于深度学习的方法,我们获得:
(a) 平均绝对误差:0.08
(b) PSNR:23.81 dB
我们当然可以推断,在这种情况下,PSNR已经显著提高。
6. 结论
在这种场景中,传统的图像增强方法对于暗图像的效果并不好,而基于深度学习的全连接CNN大大提高了性能。
在这里,我们考虑了See-in-the-Dark(SID)数据集,该数据集是为了支持开发可能实现这种极端成像的数据驱动方法而创建的。使用SID,我们开发了一个简单的流程,改进了对低光照图像的传统处理。所提出的流程基于端到端训练的全卷积网络。
然而,这种分析为进一步的范围和研究开辟了许多机会。我们没有解决HDR色调映射问题。SID数据集的局限性在于不包含人类和动态对象。然而,这种呈现的流程的结果仍然需要完善,并且可以改进。
SID数据集的另一个缺点是处理全分辨率图像的延迟。这将使整个流程在实时处理中显著变慢。然而,可以使用适当的优化技术实时生成低分辨率预览。
这篇关于计算机视觉——基于改进UNet图像增强算法实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






