本文主要是介绍从头理解transformer,注意力机制(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
交叉注意力
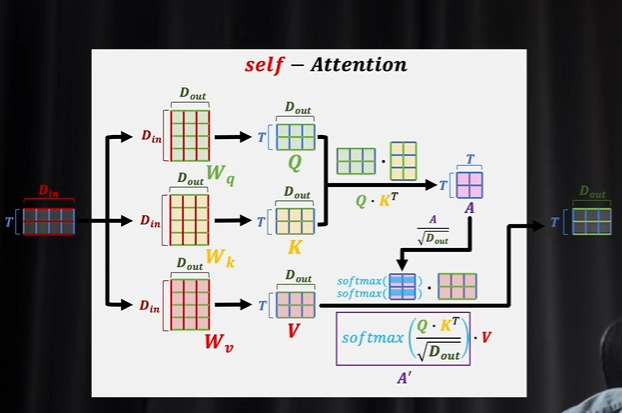
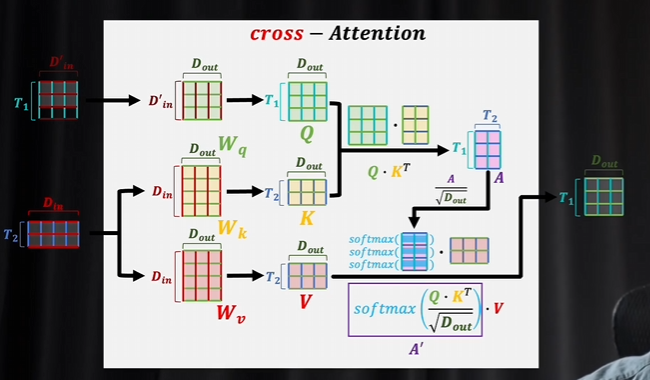
交叉注意力里面q和KV生成的数据不一样
自注意力机制就是闷头自学
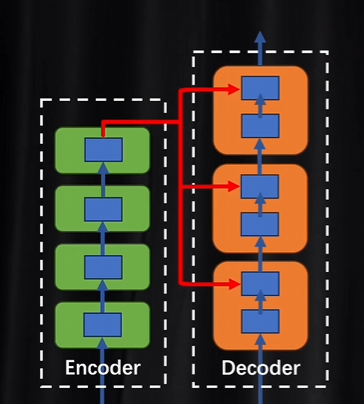
解码器里面的每一层都会拿着编码器结果进行参考,然后比较相互之间的差异。每做一次注意力计算都需要校准一次
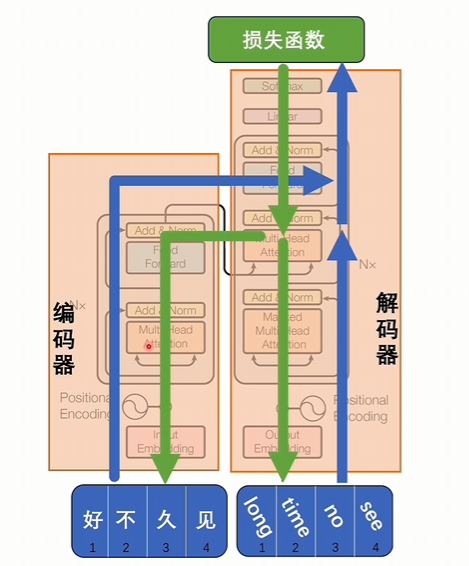
编码器和解码器是可以并行进行训练的
训练过程
好久不见输入到编码器,long time no see输入到解码器,按照transformer的编码和解码这个过程逐渐往上进行计算。
有交叉注意力进行互相匹配,看是不是一样,最后得到损失函数,这个损失函数就是判断编码器和解码器部分分别得到的潜空间词向量是不是匹配,经过反向传播再修改模型里的参数,最后达到编码器和解码器他们在潜空间里词向量里表达的词意是能对应起来的
推理过程
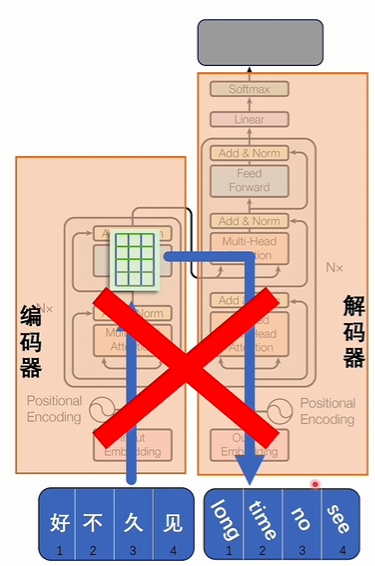
直接把输入变成词向量,词向量翻译成对应的目标的语言是不行的
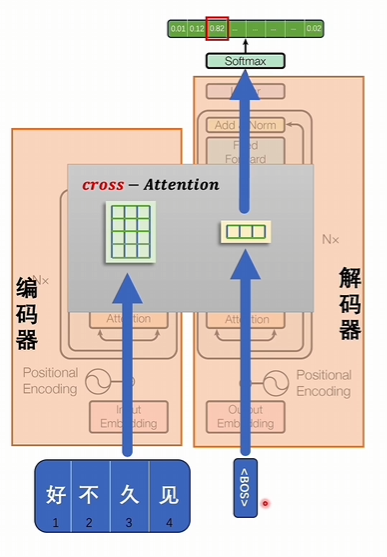
编码器部分:输入好久不见,生成一组潜空间里的词向量
解码器部分:输入一个特殊符号, 代表开始
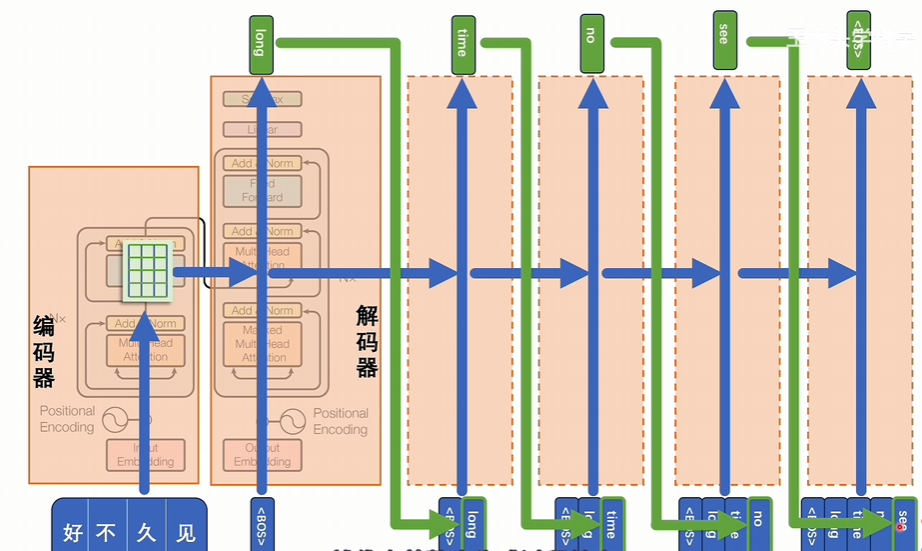
经过交叉注意力进行计算得到一个结果,结果经过升维和softmax计算后,会将词汇表的所有token都计算一个数值,拿出概率最大的值作为结果,结果代表下一个token将会是什么。
以此类推直到得到的结果是结束符号为止,代表整个生成过程结束,生成的结果就是好久不见的翻译。相当于是逐步挨个对潜空间里的词向量进行解压,一个一个的还原成token,从而解决seq2seq
位置编码
多头注意力机制其实就是能力更强的CNN,词向量的维度就是CNN里面的通道,多头对应的就是卷积核
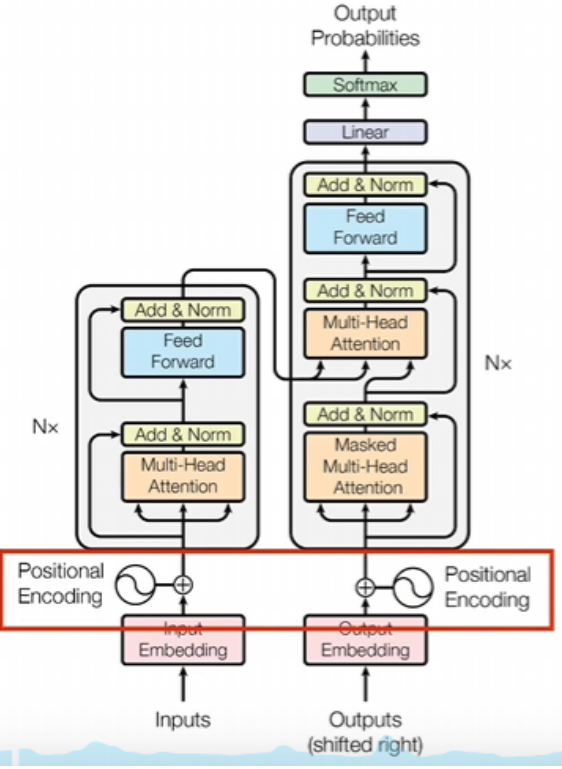
如果没有位置编码,transfomer会把所有token一起放到模型并行运算,这样的话词语的前后顺序所携带的信息没办法体现
有两种选择增加位置信息:
- 通过权重增加位置信息(乘法)
- 通过偏置系数进行区分(加法)
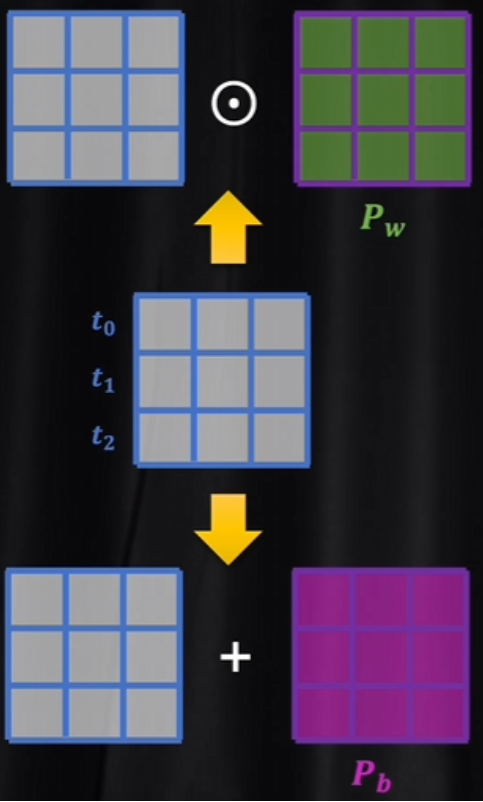
transformer用的是加法,因为如果用乘法,位置对词向量影响就太大。而LLama模型用到的旋转位置编码,就是用乘法的方式实现
绝对位置编码
针对数据进行修饰,直接让数据携带了位置信息
把位置下标,一维的自然数集投射到与词向量维度相同的连续空间,这样词向量矩阵就可以和位置编码矩阵直接相加了。
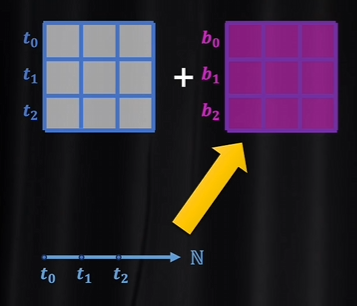
投射过程
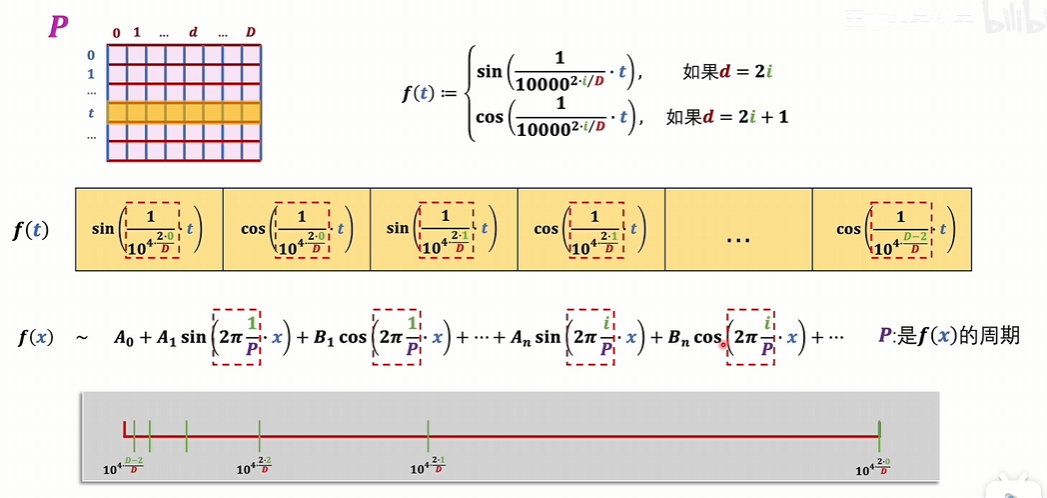
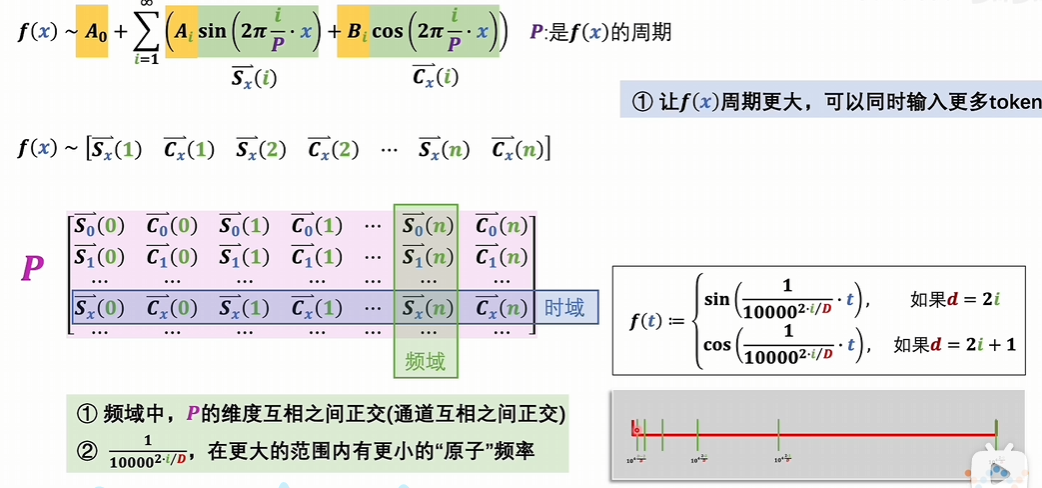
值域中

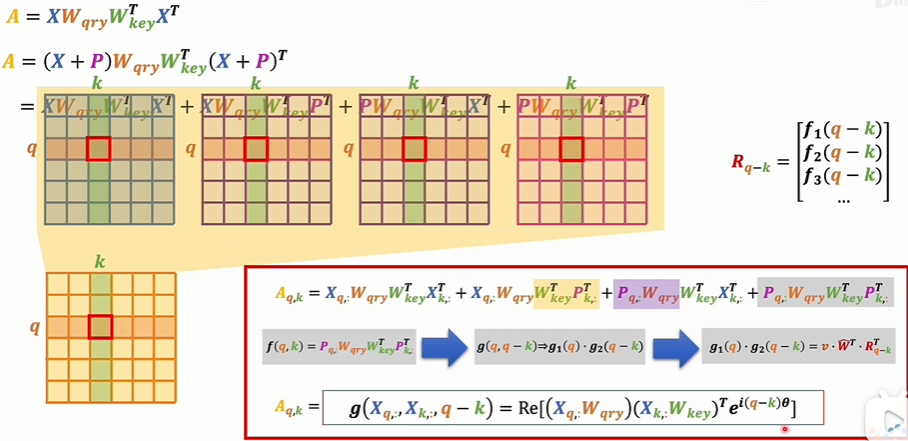
相对位置编码
会更多的考虑一个词向量和另一个词向量之间的相对位置,一个词向量和另一个词向量进行对比。这个过程是在注意力机制里面发生的.
绝对位置编码是对数据进行修饰的话,那相对位置编码就是对注意力得分的那个A矩阵进行修饰,让它具备相对位置的信息。这个矩阵考虑的是Q和K的相对关系.
对于这个注意力得分矩阵,用乘法的方式为每一项增加一个系数。这个系数是和相对位置有关的。
多头注意力机制
形式
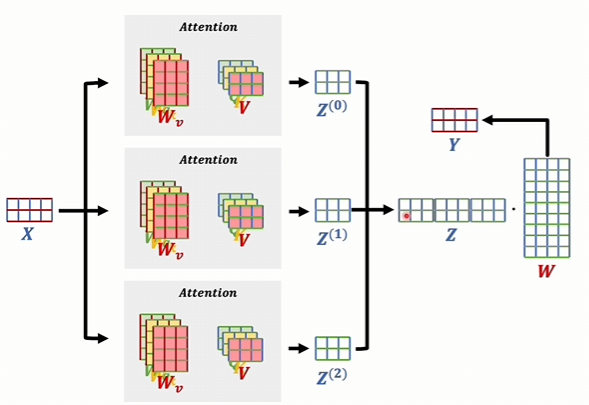
输入的数据。假如说有两词向量,我们之前只是把这个数据进行一次注意力机制,然后得到一个新的词向量。现在我们是多头了,假如说我有三头,分别去计算三次,这三个注意力机制里面系数是各自独立的。
也就是说这里的三个矩阵是不一样的。最后学到了什么可能会各不相同。最后得到的这三个结果也可能不一样。而多头对立就是把他们给拼起来
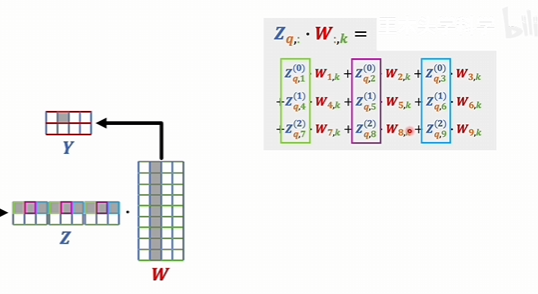
这个矩阵的行数和输入数据的这个矩阵的行数是一样的。因为行代表的是词向量的个数,行是一样的,维度就不同了。维度它是每一个输出的维度,再乘以头的个数,然后最后得到这个结果以后,还会再和一个W矩阵相乘,再得出一个输出的词向量
有什么意义
为什么要分别去计算,然后再拼在一起,而不是直接就用一个9维的W矩阵去进行训练。
词向量的维度某种程度上是可以理解成是通道的。就是和图片的RGB的通道是相同的。如果就是一个大的注意力机制,那最后得到的结果是九维,那就是相当于九个通道。
现在是多头的,每个头计算出来都有三个维度。这三个计算结果的第一位,如果定性的去想的话,他们在语义上都是比较接近的,把这些语义接近的组成一组是更合理。那这三个通道经过一个系数相乘,然后再相加得到一个具体的值
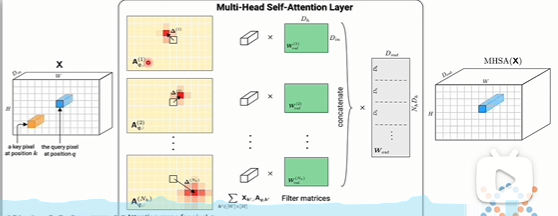
多头注意力机制比卷积神经网络它有更大的可能性,它不再局限于卷积核,必须是围绕一个中心的,是可以中间可以跨越很多个头头,对很远的地方去产生联系,所以这个可能性就要更多,也可能会比卷积神经网络更灵活。
在卷积神经网络里面,它通过卷积操作,它可以叠加不同的层去识别出不同尺度的模式,或者说不同尺度的规律。就比如说这里这个图最开始的卷积层可能是只能识别出非常简单的一些模式。再往上去叠加更多的层,就能识别出复杂的模式来了。比如说眼睛、鼻子、嘴,再往上就可以把眼睛、鼻子、嘴再拼成人的脸。

transformer它叠加了很多层,它其实也有类似的作用,不同层的叠加,最底层它很可能只能识别出一个单词,跨越几个单词它们之间的关系。随着层数越高,那可能就能识别出跨越段的语义关系,代表就识别出跨越文章的语义关系。
其他
1.掩码
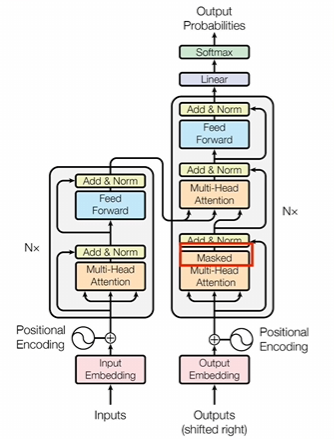
第一个是在解码器里面,这个注意力上会加一个掩码,就是因为在推理的时候,解码器部分是一个词一个词生成的这就代表了你生成到某个词的时候,这个词它只能受到它之前词的影响,不应该被未来生成的词所决定。我们前面说了,注意力机制里面那个助力得分矩阵A它可以表示一个词和所有上下文之间的关系的,既包含了它之前的,也包含了它之后的。所以说这个时候就需要把矩阵A中的这部分词给屏蔽掉。
屏蔽的方法就是在这些位置上分别加上一个无穷小这样子。

2.计算残差和进行normal运算
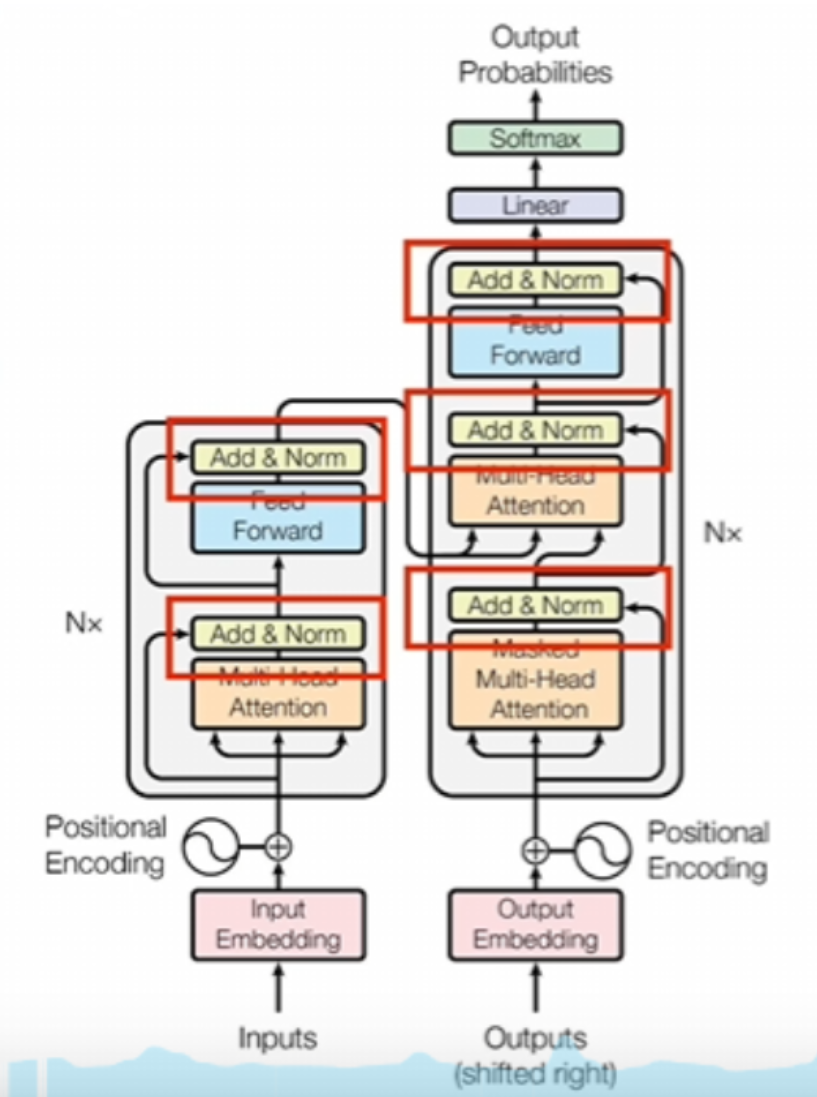 这部分它会完成两个操作,一个是实现残差网络的功能,另一个是对上一层数据进行normal运算,也就是进行归一化。反正它的计算很简单,就是把输入和输出直接加起来,这么简单一加之后就会让注意力机制里面学习到的东西发生变化了。如果没有做残差,那注意力机制里面学到的是变化后的结果。而做了残差注意力机制里面学到的就是变化的程度了。
这部分它会完成两个操作,一个是实现残差网络的功能,另一个是对上一层数据进行normal运算,也就是进行归一化。反正它的计算很简单,就是把输入和输出直接加起来,这么简单一加之后就会让注意力机制里面学习到的东西发生变化了。如果没有做残差,那注意力机制里面学到的是变化后的结果。而做了残差注意力机制里面学到的就是变化的程度了。
这两种情况的区别,做个类比的话,大概就是这样一种情况,没有做残差,就相当于是你蒙着眼开车,你只能通过控制手的不来回晃动,让自己车尽量走直线。理论上是可以做到的,但是对操作要求那就非常高了。做了残差,就相当于是你可以看到路上的标线,你控制的其实是车子和标线的偏差。就算手再抖,这个偏差也不会太大,你还是能调整回来的。
至于norm,Transformer里面用到的是layer Normal, 简单来说就是给模型里面输入的是一个batch数据。如果简单理解的话,你可以这么去想,你给模型说说一段话,一段话里面有不同的句子,每个句子都是一个句子的长短不一样。所以说这个句子的行数也不一样,那样的话要做的就是你一个句子里面,不管你的这个行数是多少,反正是这个句子里的所有元素放在一起进行归一,那就是layer Normal.
3.前馈神经网络
其实也就是一个全连接神经网络。CNN也有类似的东西,就是前面是一堆卷积层。卷积层计算完了之后还会把结果输入到神经网络里面。
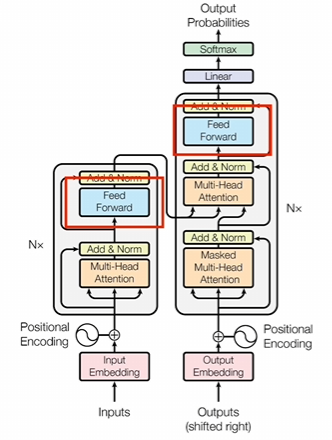
全连接神经网络到底和前面的数据怎么连,按照词向量的维度去排列,作为输入一个维度。对应一个输入,因为只想让你的维度某种程度上来说就是这个词对应的词义特征,把特征输入到神经网络,这应该算是标准操作了。神经网络最后要做的就是各种特征的组合和抽象。
4.线性层
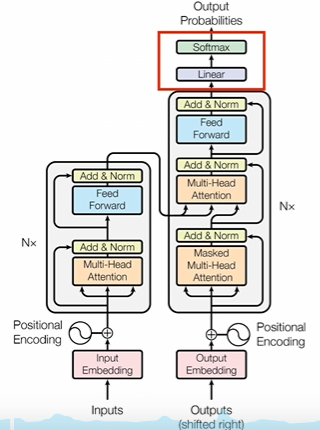
线性层其实就是一个线性变化,也就是做一个矩阵运算。其实这部分我也没有去仔细研究,我的理解是这里加入这一层是为了将前面潜空间里的子向量再进行一次维度变换训练的时候,你就要把维度变换成可以计算损失值的形式。在推理的时候,你需要把词向量变成读热编码去判断到底哪个token的概率最大。所以这部分应该也不是特别复杂。
这篇关于从头理解transformer,注意力机制(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



