本文主要是介绍使用 AI Assistant for Observability 和组织的运行手册增强 SRE 故障排除,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:Almudena Sanz Olivé, Katrin Freihofner, Tom Grabowski
通过本指南,你的 SRE 团队可以实现增强的警报修复和事件管理。

可观测性 AI 助手可帮助用户使用自然语言界面探索和分析可观测性数据,利用自动函数调用来请求、分析和可视化数据,将其转换为可操作的可观测性。 该助手还可以建立一个由 Elastic Learned Sparse EncodeR (ELSER) 提供支持的知识库,以提供来自私人数据的附加上下文和建议,以及使用 RAG(检索增强生成)的大型语言模型 (LLM)。 Elastic 的 Stack — 作为一个向量数据库,具有开箱即用的语义搜索以及 LLM 集成和可观测性解决方案的连接器 — 是一个完美的工具包,可以将公司独特的可观测性知识与生成式 AI 相结合,从而获得最大价值。
增强 SRE 故障排除
由于资源分散且可能过时,大型组织中的站点可靠性 (SRE) 在查找必要的工程师信息以排除警报、监控系统或获取见解方面经常面临挑战。 对于经验不足的 SRE 来说,这个问题尤其重要,即使有操作手册,他们也可能需要帮助。 重复发生的事件会带来另一个问题,因为待命人员可能缺乏对之前解决方案和后续步骤的了解。 成熟的 SRE 团队通常会投入大量时间来改进系统,以最大程度地减少 “救火”,并利用广泛的自动化和文档来支持待命人员。
Elastic® 通过使用 RAG 将生成式 AI 模型与内部数据的相关搜索结果相结合来应对这些挑战。 Observability AI Assistant 的内部知识库由我们的语义搜索检索模型 ELSER 提供支持,可以在对话过程中的任何时刻回忆信息,并根据内部知识提供 RAG 响应。
该知识库可以通过你组织的信息来丰富,例如操作手册、GitHub 问题、内部文档和 Slack 消息,从而允许 AI 助手提供特定帮助。 在排除问题时,助手还可以记录和存储与 SRE 正在进行的对话中的特定信息,从而有效地创建操作手册以供将来参考。 此外,助手还可以生成事件摘要、系统状态、操作手册、事后分析或公告。
这种检索、总结和呈现上下文相关信息的能力对于 SRE 团队来说是一个游戏规则改变者,将工作从追逐文档和数据转变为直观的、上下文敏感的用户体验。知识库(请参阅需求)充当中央存储库。的可观察性知识,打破文档孤岛并整合部落知识,使借助 LLMs 的力量增强的 SRE 可以访问这些信息。
你的 LLM 提供商在使用人工智能助手时可能会收集查询遥测数据。 如果你的数据属于机密或包含敏感细节,我们建议你验证你向 AI 助手提供的 LLM 连接器的数据处理政策。
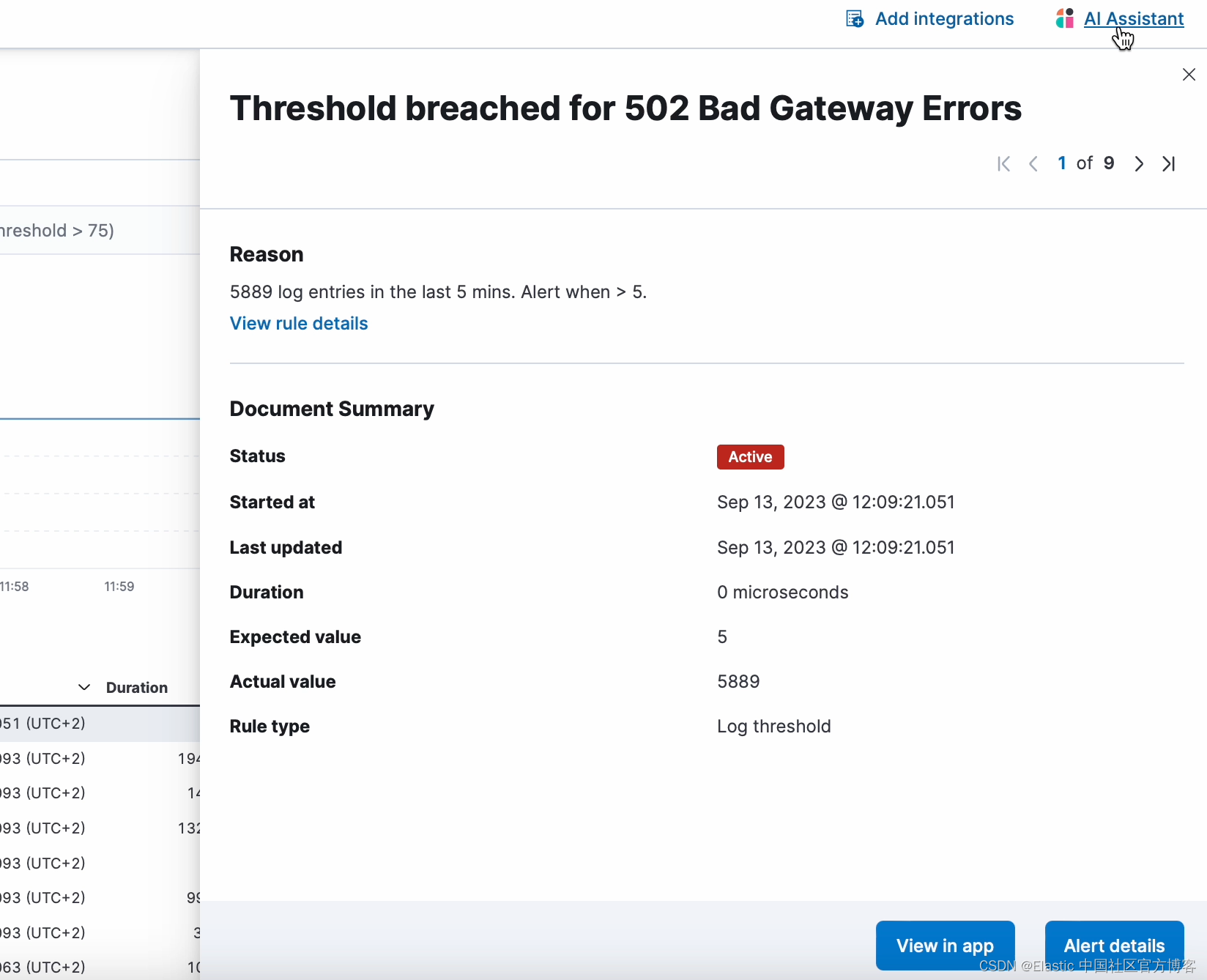
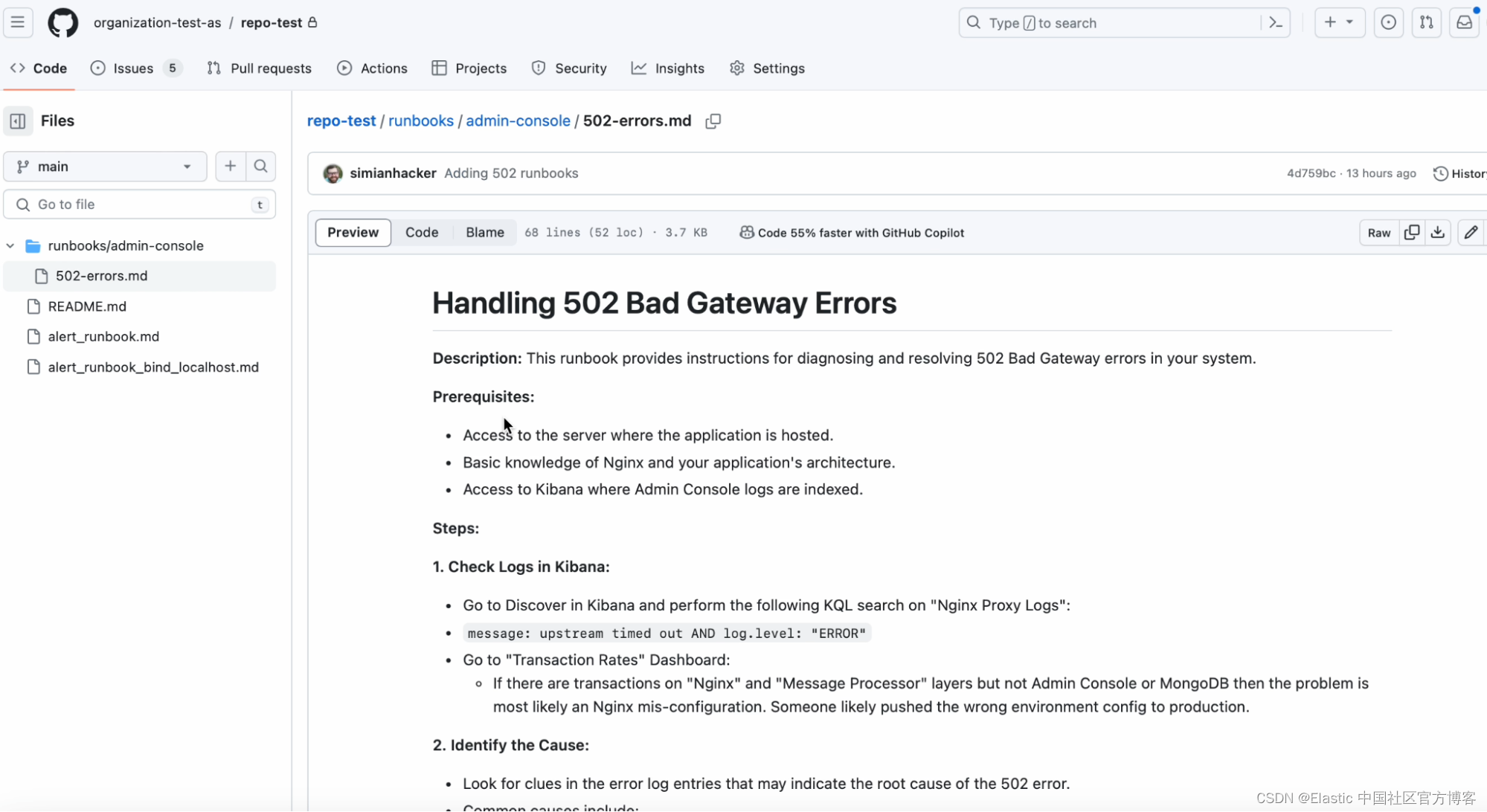
在这篇博文中,我们将介绍通过内部信息丰富你的知识库 (KB) 的不同方法。 我们将重点关注特定警报,该警报表明带有 “502 Bad Gateway” 错误的日志数量有所增加,并且已超出警报的阈值。
如何使用知识库对警报进行故障排除
在知识库充实内部信息之前,当 SRE 向 AI 助手询问如何解决警报问题时,LLM 的响应将基于其在训练期间学到的数据; 然而,LLM 无法回答与私人、近期或新兴知识相关的问题。 在这种情况下,当询问解决警报问题的步骤时,响应将基于通用信息。

但是,一旦你的操作手册丰富了知识库,当你的团队收到有关 “502 Bad Gateway” 错误的新警报时,他们可以使用 AI Assistant 访问内部知识来排除故障,使用语义搜索在知识库。
在本博客中,我们将介绍向知识库添加有关如何排除警报故障的内部信息的不同方法:
- 让助手记住现有操作手册的内容。
- 要求助手总结对话期间采取的步骤并将其存储在知识库中,并将其存储为操作手册。
- 使用我们的连接器和 API 将你的 Runbook 从 GitHub 或其他外部源导入到知识库。
将操作手册添加到知识库后,AI 助手现在可以调用操作手册中的内部信息和特定信息。 通过利用检索到的信息,LLM 可以提供更准确和相关的建议来解决警报问题。 这可能包括建议警报的潜在原因、解决问题的步骤、未来事件的预防措施,或要求助理使用功能帮助执行操作手册中提到的步骤。 有了更准确、更相关的信息,SRE 可能会更快地解决警报,从而减少停机时间并提高服务可靠性。
你的知识库文档将存储在索引 .kibana-observability-ai-assistant-kb-* 中。 请记住,LLMs 对模型一次可以读取和写入的信息量有限制,称为 token 限制。 想象一下,你正在读一本书,但一次只能记住一定数量的单词。 一旦达到这个限制,你就会开始忘记之前读过的单词。 这类似于 LLM 中 token 限制的工作方式。
为了使操作手册保持在检索增强生成 (RAG) 模型的 token 限制内,请确保信息简洁且相关。 为了清晰起见,使用要点,避免重复,并使用链接获取附加信息。 定期查看和更新操作手册,删除过时或不相关的信息。 目标是提供清晰、简洁、有效的故障排除信息,而不会因 token 限制限制而影响质量。 LLM 非常适合总结,因此你可以要求 AI 助手帮助你使操作手册更加简洁。
让助手记住现有操作手册的内容
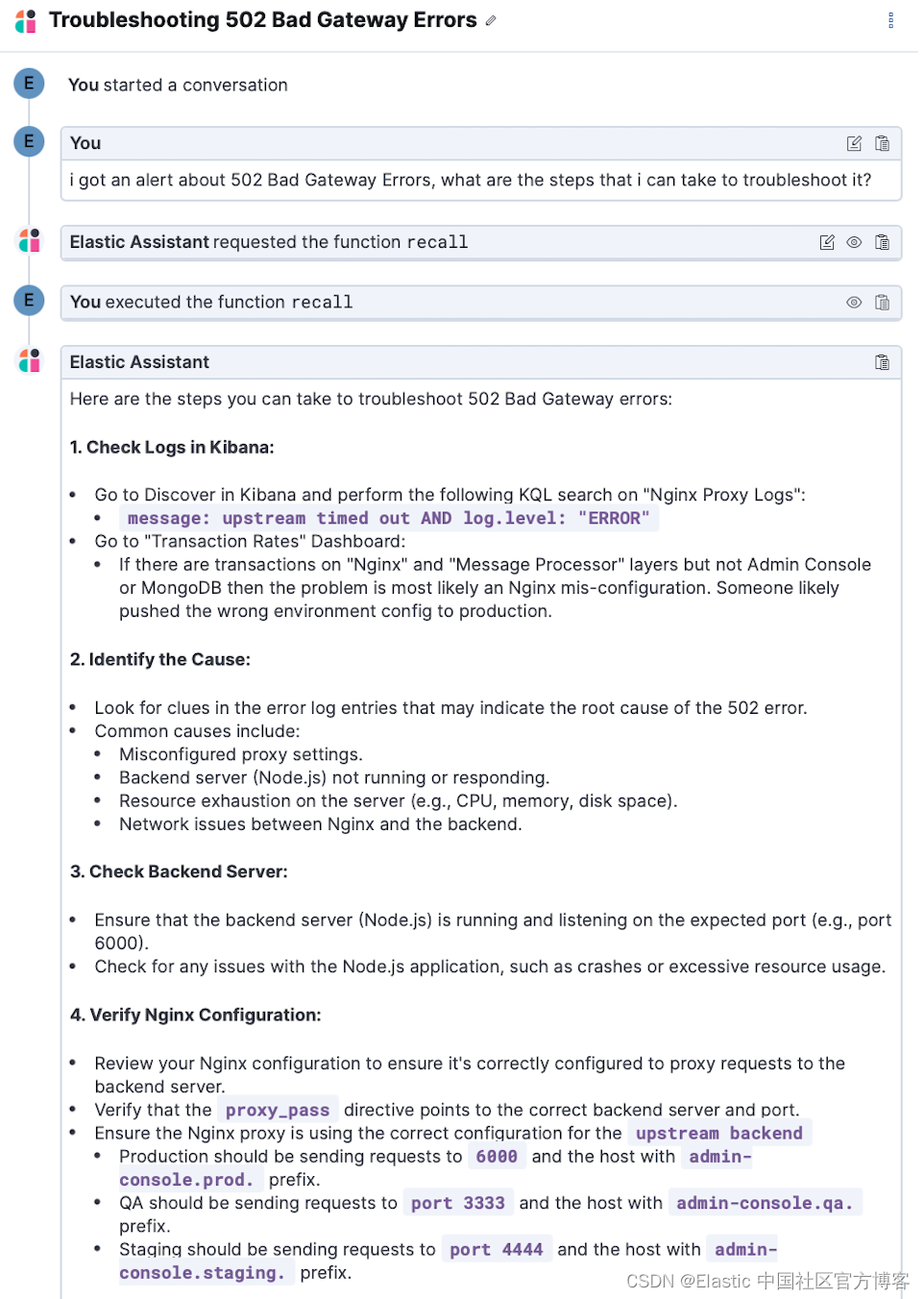
将操作手册存储到知识库的最简单方法就是让人工智能助手去做! 打开一个新对话并询问 “Can you store this runbook in the KB for future reference? - 你可以将此操作手册存储在知识库中以供将来参考吗?” 然后以纯文本形式粘贴操作手册的内容。
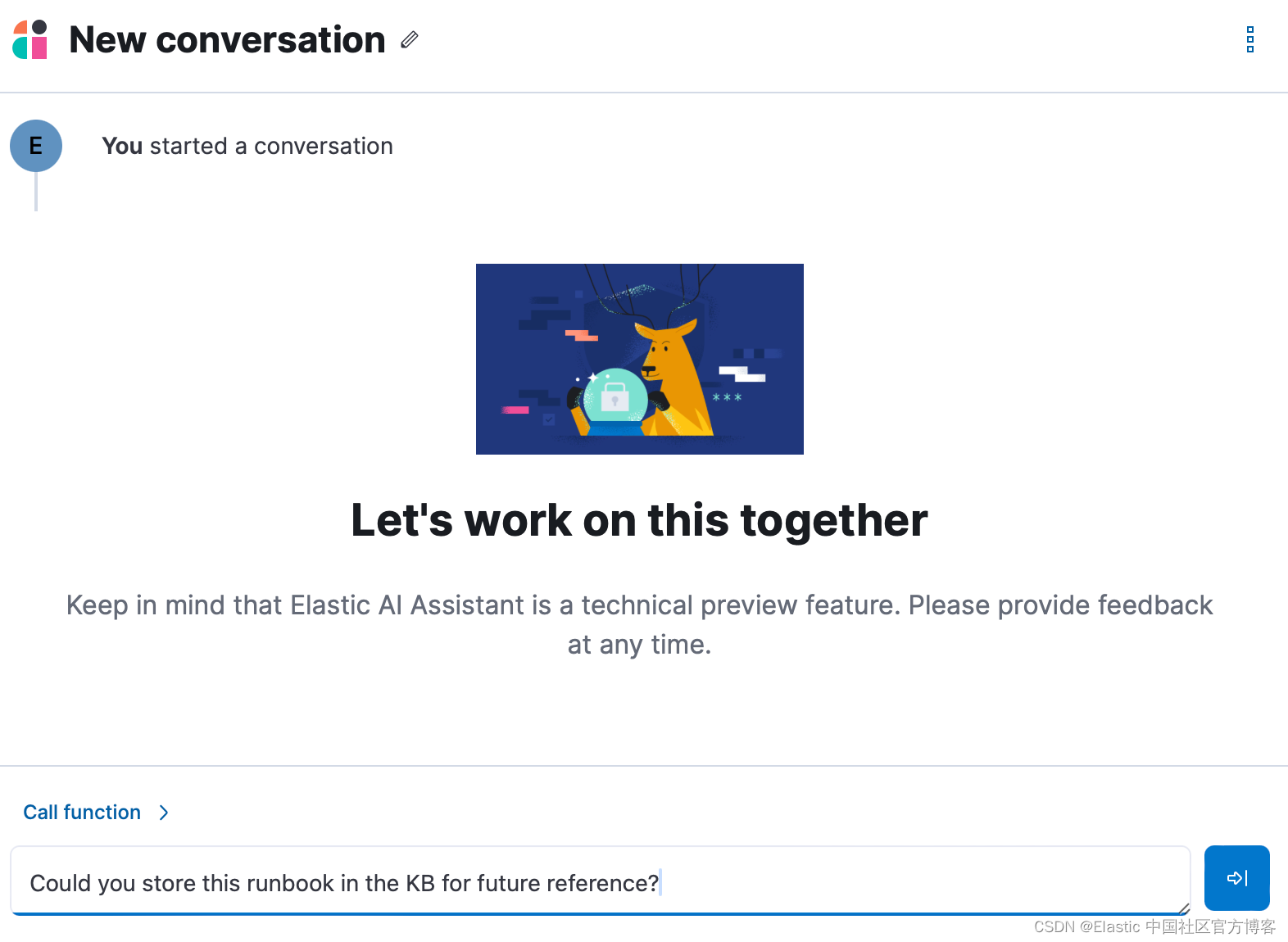
然后 AI 助手会自动帮你存入知识库,就这么简单。
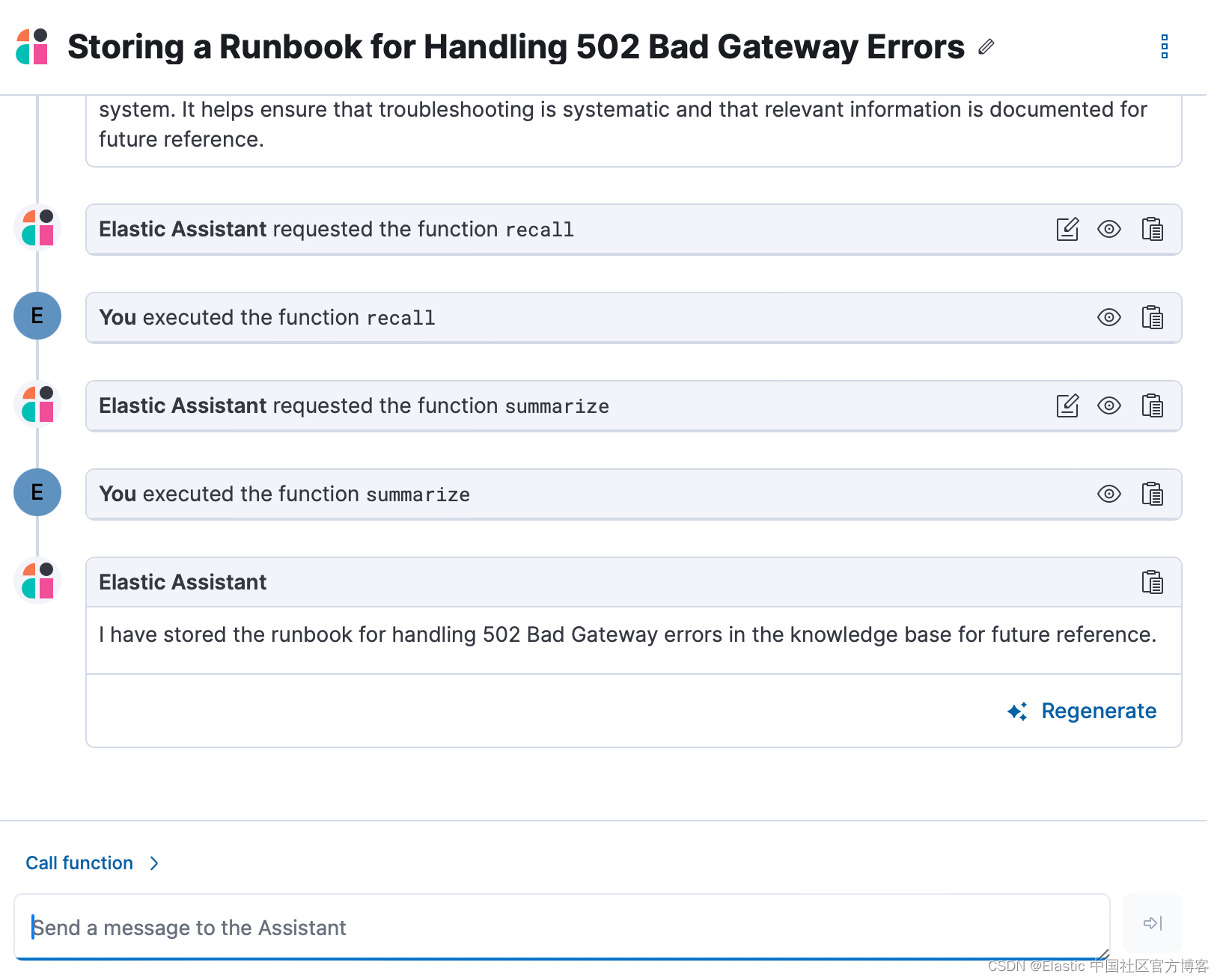
让助手总结对话期间采取的步骤并将其存储在知识库中
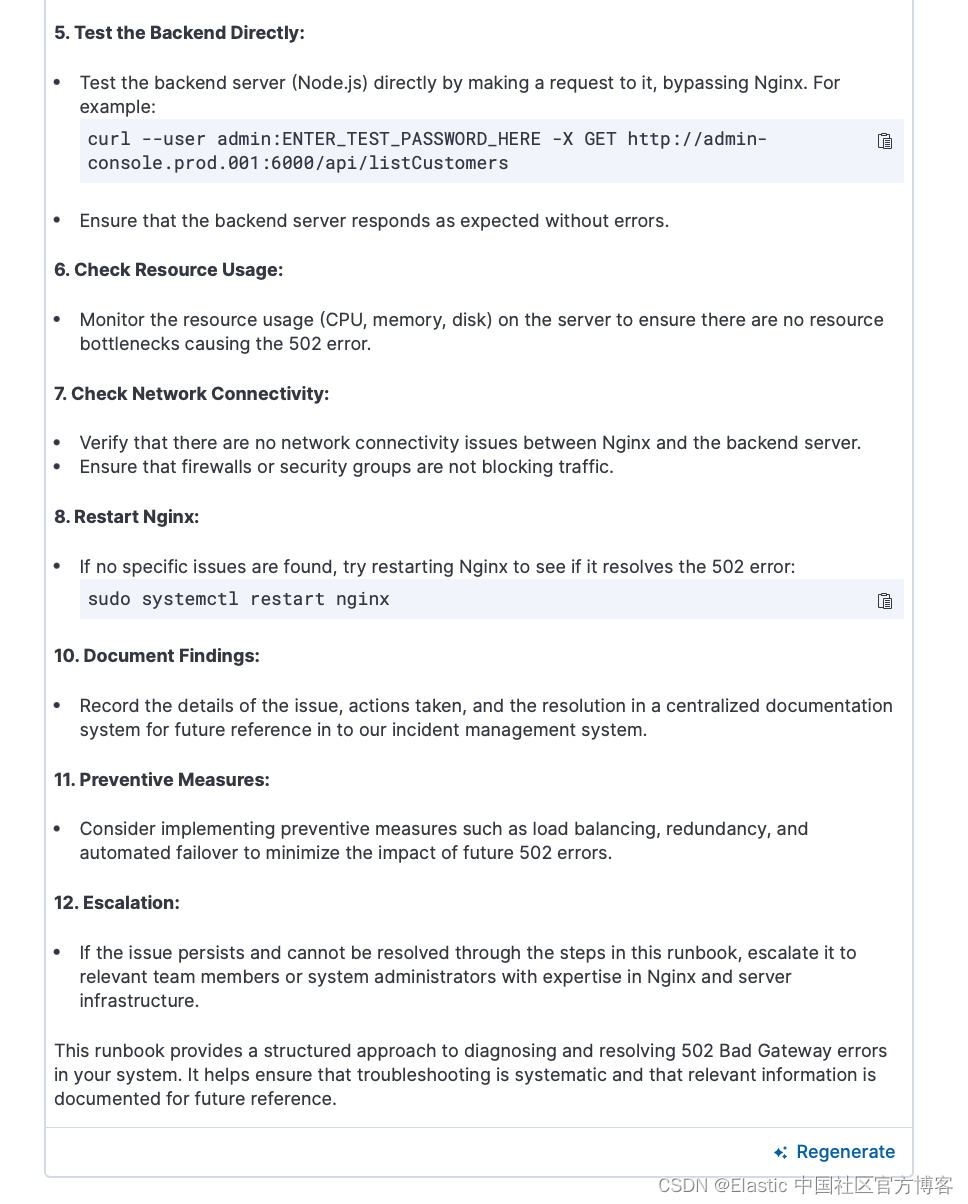
你还可以要求 AI 助手在对话时记住一些内容 - 例如,在使用 AI 助手解决了警报问题后,你可以要求 “remember how to troubleshoot this alert for next time. - 记住下次如何解决此警报问题”。 AI 助手将创建对警报进行故障排除所采取的步骤的摘要,并将其添加到知识库中,从而有效地创建操作手册以供将来参考。 下次你遇到类似的情况时,AI 助手会回忆起这些信息并用它来帮助你。
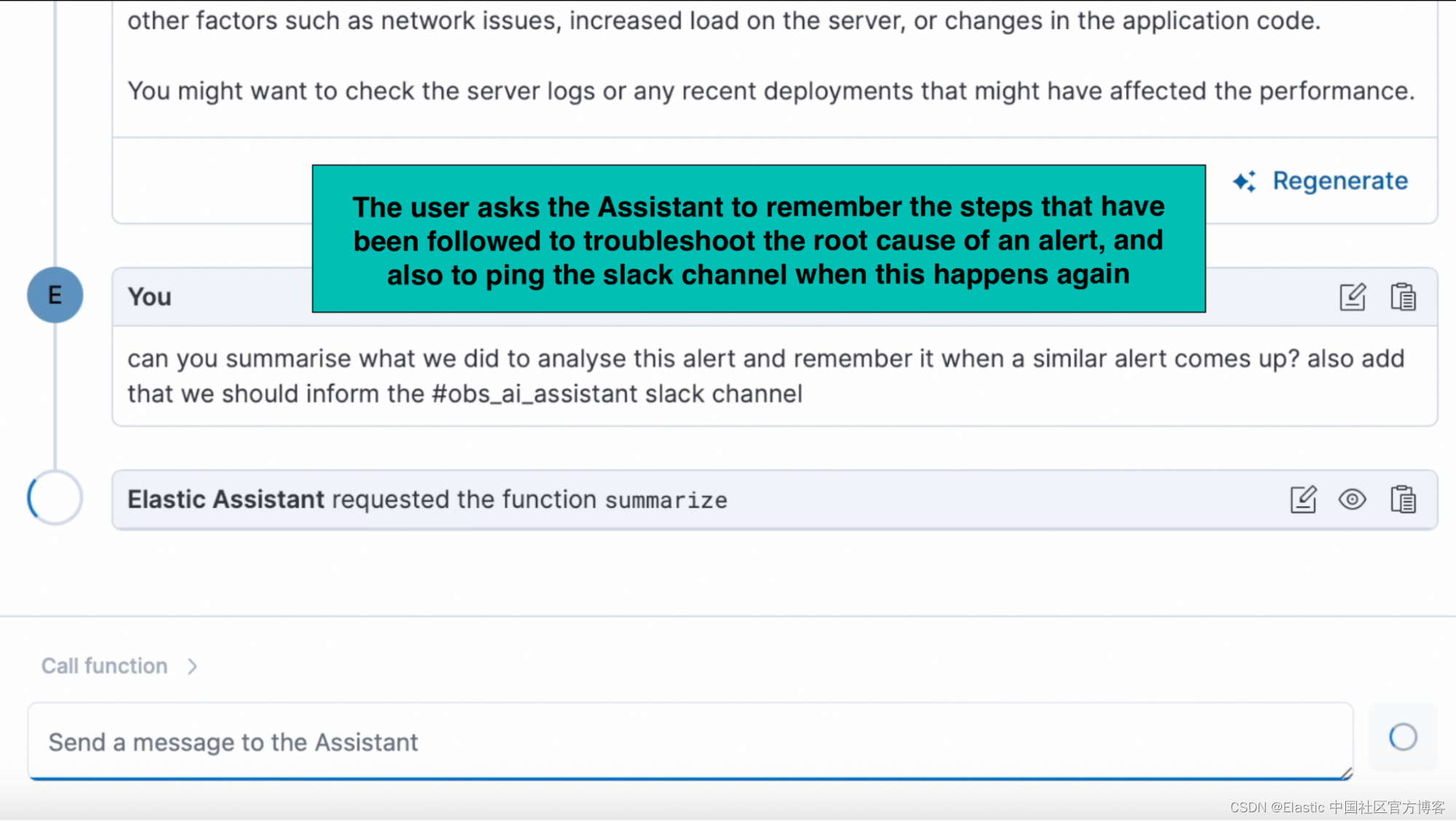
在下面的演示中,用户要求助手记住为解决警报的根本原因而遵循的步骤,并在这种情况再次发生时对 Slack 通道执行 ping 操作。 在后来与助手的对话中,用户询问类似问题可以做什么,AI 助手能够记住这些步骤,并提醒用户 ping Slack 通道。
收到警报后,你可以打开 AI 助手聊天并测试排除警报。 调查警报后,请 AI 助手总结分析结果以及针对根本原因采取的步骤。 为了下次记住它们,我们有一个类似的警报并添加额外的指令,例如警告 Slack 通道。
助手将使用内置功能总结步骤并将其存储到你的知识库中,以便在将来的对话中调用。
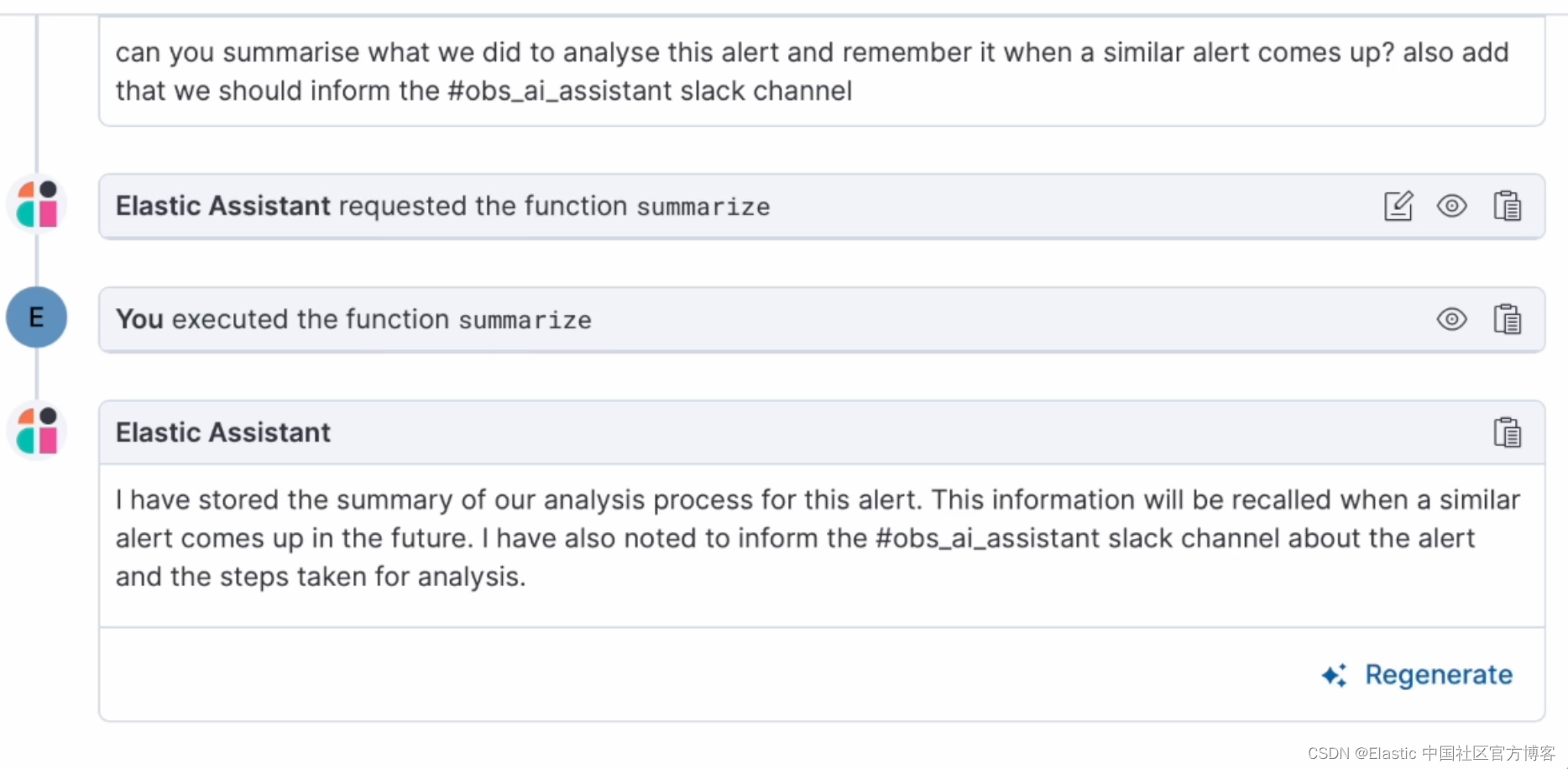
打开一个新对话,询问在对与我们刚刚调查的警报类似的警报进行故障排除时应采取哪些步骤。 助手将能够使用基于 ELSER 的语义搜索来调用存储在 KB 中的与特定警报相关的信息,并提供故障排除步骤的摘要,包括通知 Slack 通道的最后指示。
blog RAG text user
使用 API 或我们的 GitHub 连接器将存储在 GitHub 中的 Runbook 导入知识库
你还可以通过将专有数据(例如 GitHub 问题、Markdown 文件、Jira 票证、文本文件)提取到 Elastic 中,以编程方式将专有数据添加到知识库中。
如果你的组织已创建存储在 GitHub 中的 Markdown 文档中的 Runbook,请按照本博客文章下一部分中的步骤将 Runbook 文档索引到你的知识库中。
将文档引入知识库的步骤如下:
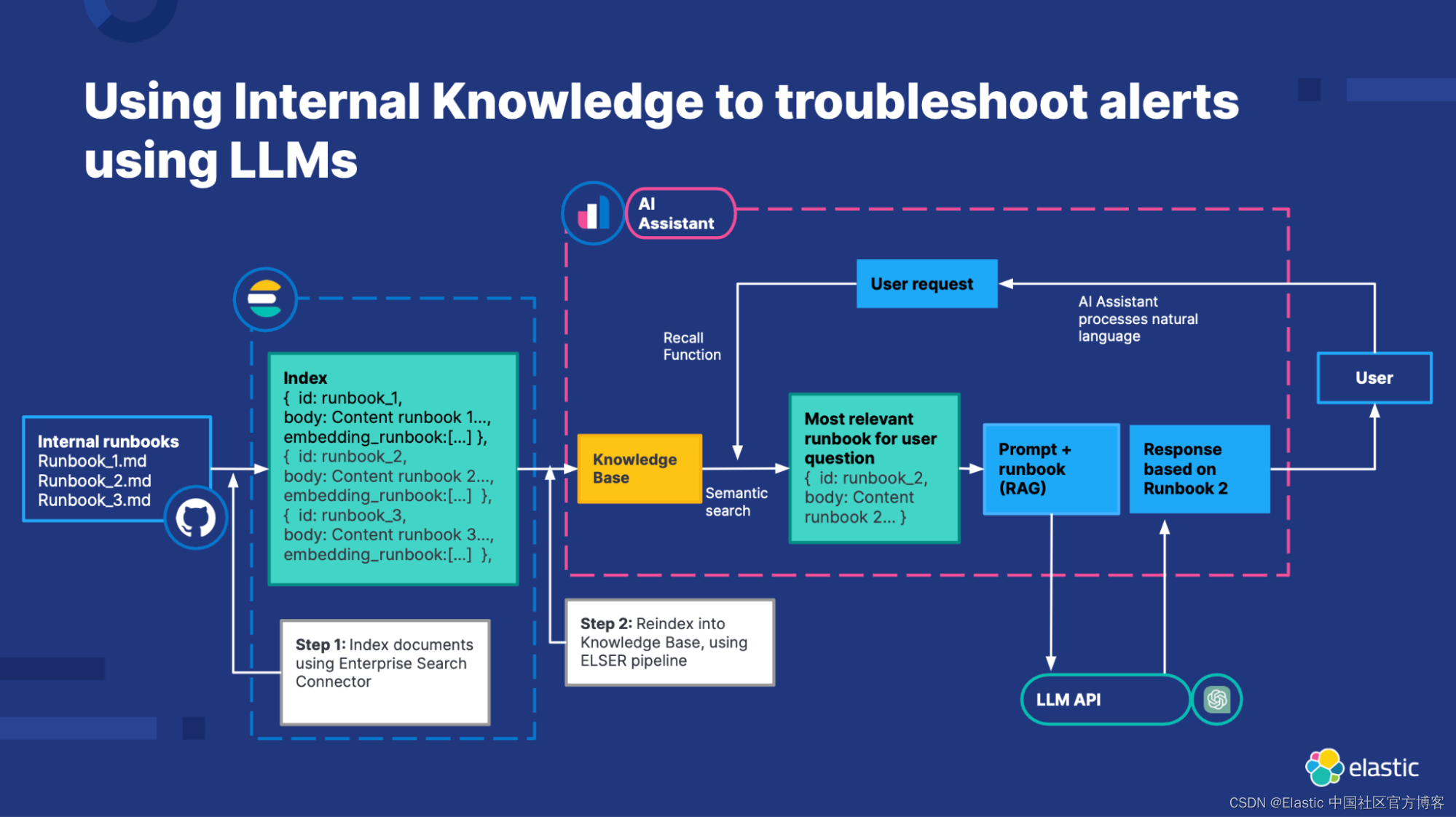
将你组织的知识吸收到 Elasticsearch 中
选项 1:使用 Elastic 网络爬虫。 使用网络爬虫以编程方式从网站和知识库中发现、提取和索引可搜索内容。 当你使用网络爬虫获取数据时,会创建一个搜索优化的 Elasticsearch® 索引来保存和同步网页内容。
选项 2:使用 Elasticsearch 的 index API。 观看演示如何使用 Elasticsearch 语言客户端从应用程序获取数据的教程。
选项 3:构建你自己的连接器。 请按照此博客中描述的步骤操作:如何为 Elasticsearch 创建自定义连接器。
选项 4:使用 Elasticsearch Workplace 搜索连接器。 例如,GitHub 连接器可以自动捕获、同步和索引问题、Markdown 文件、拉取请求和存储库。
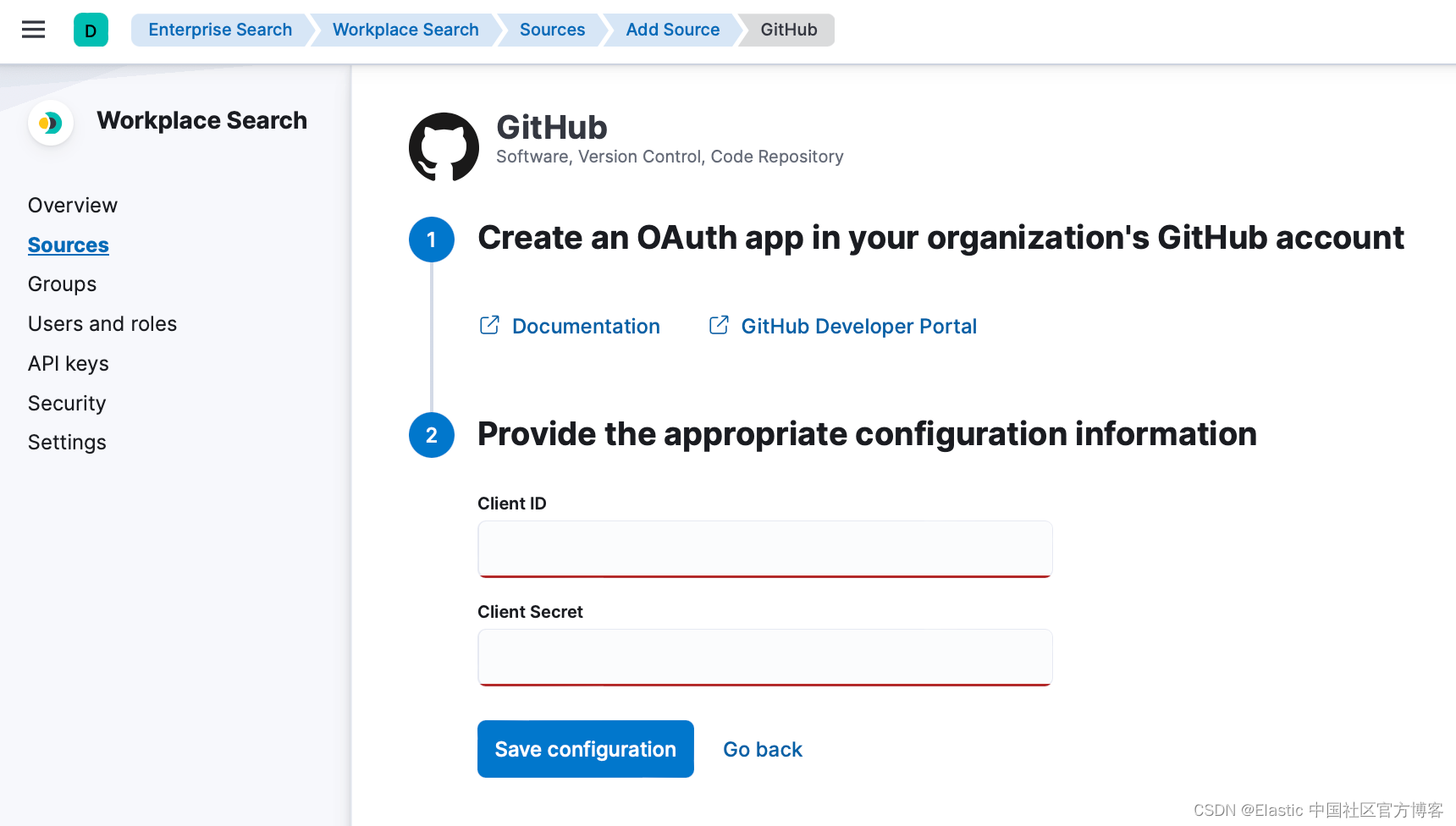
- 按照步骤在 GitHub 中配置 GitHub 连接器,以从 GitHub 平台创建 OAuth 应用程序。
- 现在你可以将 GitHub 实例连接到你的组织。 前往你组织的 “Search”>“Workplace Search” 管理仪表板,然后找到 “Sources” 选项卡。
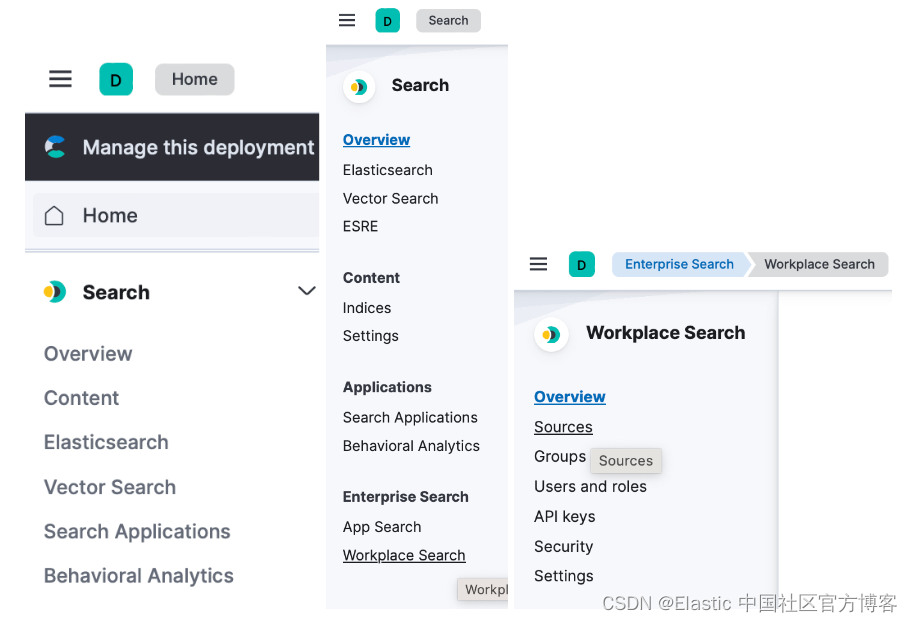
- 在已配置 Sources 列表中选择 GitHub(或 GitHub Enterprise),然后按照所示的 GitHub 身份验证流程进行操作。 身份验证流程成功后,你将被重定向到工 Workplace Search,并提示你选择要同步的组织。
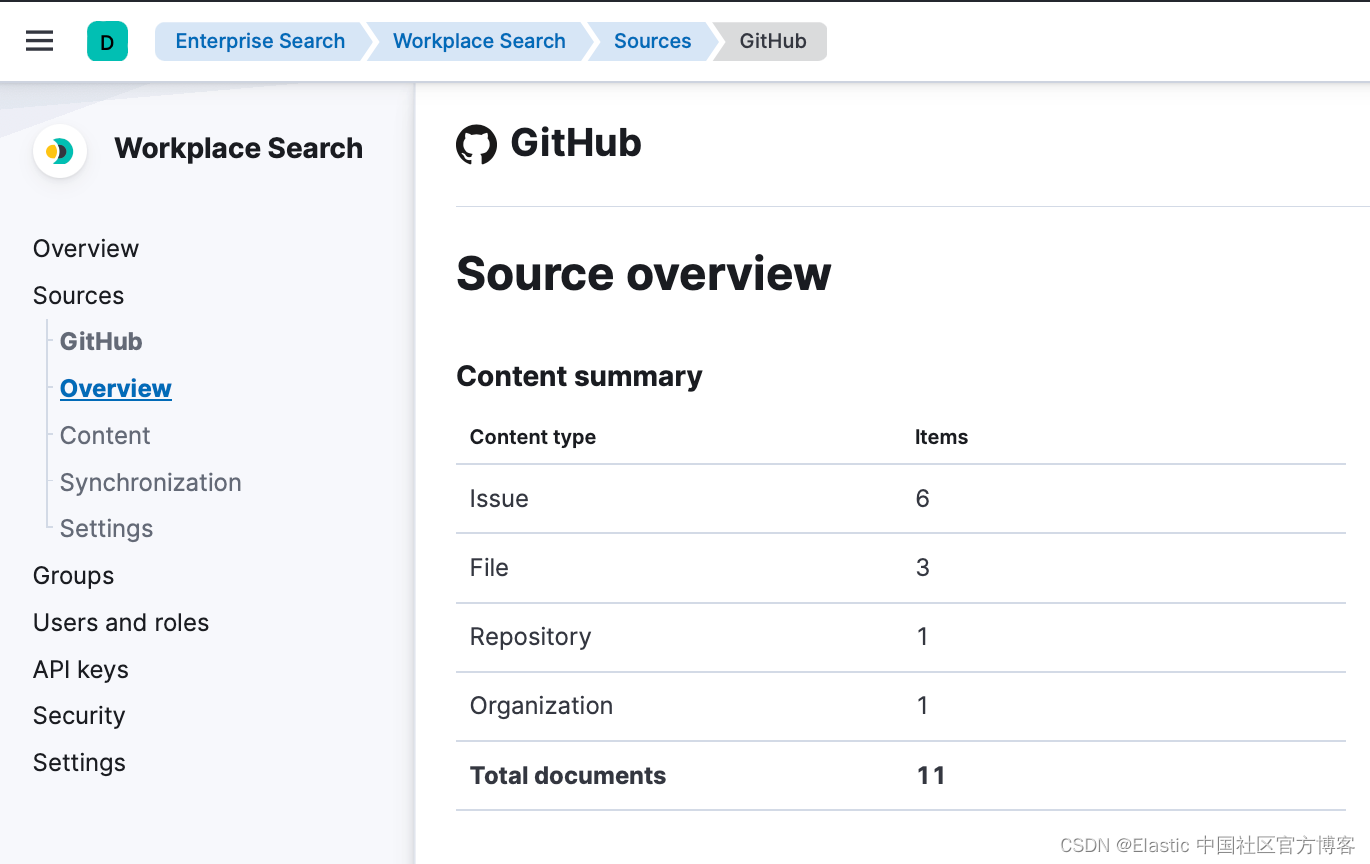
- 配置连接器并选择组织后,内容应该同步,你将能够在 Sources 里看到它。 如果你不需要对所有可用内容建立索引,你可以通过 API 指定索引规则。 这将有助于缩短索引时间并限制索引的大小。 请参阅自定义索引。
- Source 已在 Elastic 中创建了一个索引,其中包含来自你组织的内容(issues、Markdown 文件……)。 你可以通过导航到 “Stack Management” > “Index Management”,激活右侧的 “ Include hidden Indices” 按钮,然后搜索 “GitHub” 来找到索引名称。
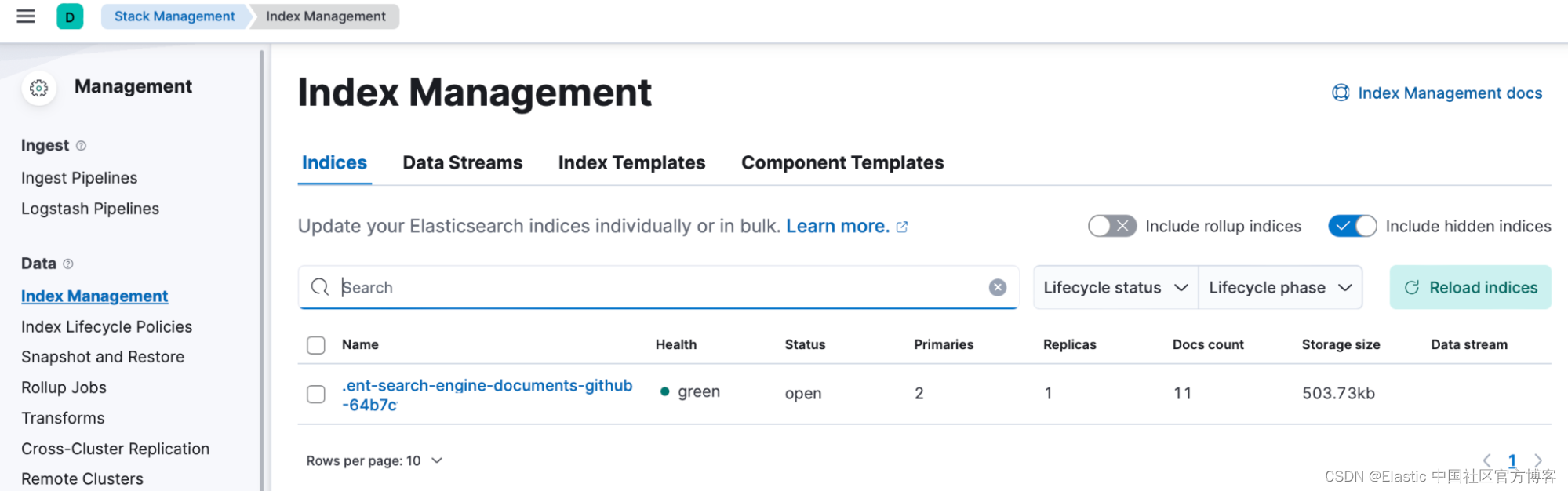
你可以通过创建数据视图 (Data View) 并在 “Discover” 中探索来探索已索引的文档。 转到 Stack Management > Kibana > Data Views > Create data view 并输入数据视图名称、索引模式(确保在高级选项中激活 “Allow hidden and system indices” )和时间戳字段:
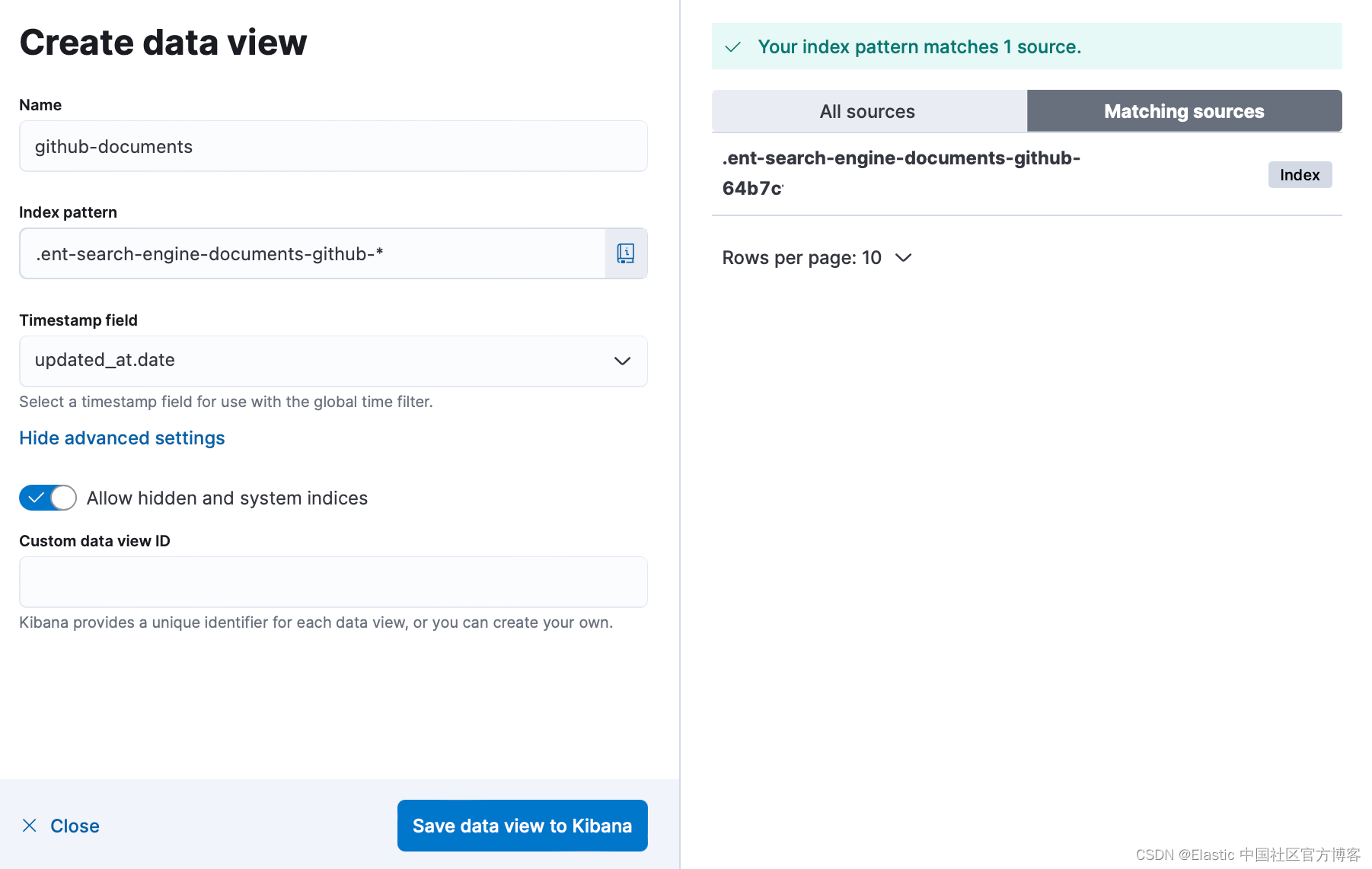
- 你现在可以使用数据视图浏览 Discover 中的文档:
使用其语义搜索管道将你的内部操作手册重新索引到 AI 助手的知识库索引中
你的知识库文档存储在索引 .kibana-observability-ai-assistant-kb-* 中。 要将从 GitHub 导入的内部 Runbook 添加到知识库,你只需将文档从上一步中创建的索引重新索引到知识库的索引即可。 要向知识库中的文档添加语义搜索功能,重新索引还应使用为知识库预先配置的 ELSER 管道,.kibana-observability-ai-assistant-kb-ingest-pipeline。
通过使用知识库索引创建数据视图,你可以探索 Discover 中的内容。
你在 “Management” > “DevTools” 中执行以下查询,确保在 “_source” 和 “inline” 上替换以下内容:
- InternalDocsIndex :存储内部文档的索引名称
- text_field :包含内部文档文本的字段名称
- timestamp : 内部文档中时间戳字段的名称
- public :(true 或 false)如果为 true,则使文档可供定义的 Kibana 空间(如果已定义)或所有空间(如果未定义)中的所有用户使用; 如果为 false,文档将仅限于中指定的用户
- (可选) space :如果定义,则限制内部文档在特定的 Kibana 空间中可用
- (可选) user.name :如果定义,则限制内部文档可供特定用户使用
- (可选)“query” 过滤器仅索引某些文档(见下文)
POST _reindex
{"source": {"index": "<InternalDocsIndex>","_source": ["<text_field>","<timestamp>","namespace","is_correction","public","confidence"]},"dest": {"index": ".kibana-observability-ai-assistant-kb-000001","pipeline": ".kibana-observability-ai-assistant-kb-ingest-pipeline"},"script": {"inline": "ctx._source.text=ctx._source.remove(\"<text_field>\");ctx._source.namespace=\"<space>\";ctx._source.is_correction=false;ctx._source.public=<public>;ctx._source.confidence=\"high\";ctx._source['@timestamp']=ctx._source.remove(\"<timestamp>\");ctx._source['user.name'] = \"<user.name>\""}
}
你可能想要指定在知识库中重新索引的文档类型 - 例如,你可能只想重新索引 Markdown 文档(如 Runbook)。 你可以向源中的文档添加 “query” 过滤器。 对于 GitHub,Runbook 使用包含字符串 “file” 的 “type” 字段进行标识,你可以将其添加到重新索引查询中,如下所示。 要添加 GitHub 问题,你还可以在查询 “type” 字段中包含字符串 “issues”:
"source": {"index": "<InternalDocsIndex>","_source": ["<text_field>","<timestamp>","namespace","is_correction","public","confidence"],"query": {"terms": {"type": ["file"]} }
太棒了! 现在数据已存储在你的知识库中,你可以向 Observability AI Assistant 询问有关它的任何问题:
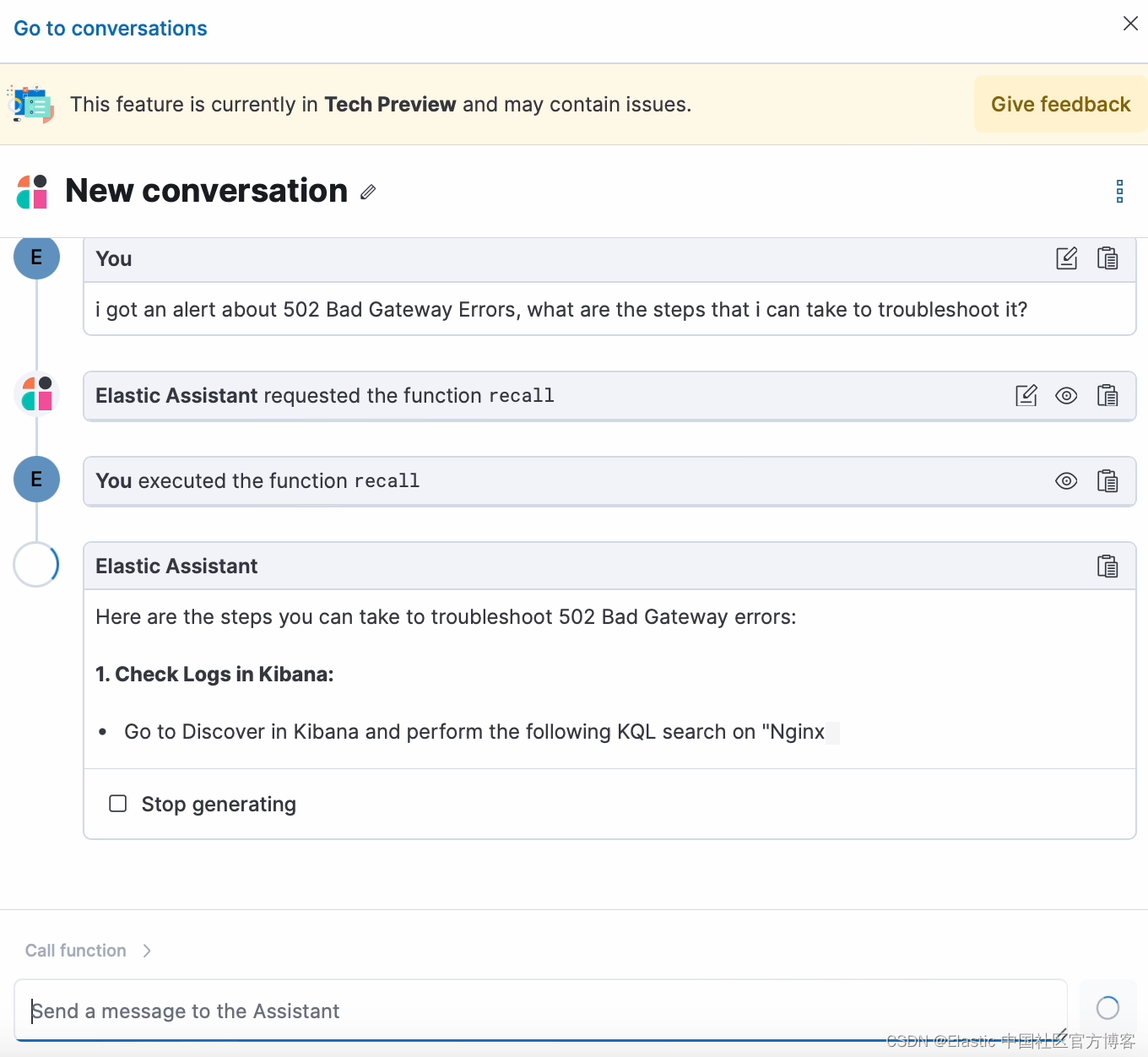
blog RAG issue
blog RAG runbook
结论
综上所述,利用内部的可观察性知识并将其添加到弹性知识库中可以极大地增强 AI 助手的能力。 通过手动输入信息或以编程方式摄取文档,SRE 可以创建一个可通过 Elastic 和 LLM 的功能访问的中央知识存储库。 人工智能助手可以调用这些信息,协助处理事件,并使用检索增强生成为特定环境提供定制的可观察性。 通过遵循本文中概述的步骤,组织可以释放其 Elastic AI Assistant 的全部潜力。
立即开始使用 Elastic AI Assistant 丰富你的知识库,并为你的 SRE 团队提供卓越所需的工具。 按照本文中概述的步骤操作,将你的事件管理和警报修复流程提升到新的水平。 你迈向更高效、更有效的 SRE 运营的旅程现在就开始了。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
在这篇博文中,我们可能使用或引用了第三方生成人工智能工具,这些工具由其各自所有者拥有和运营。 Elastic 对第三方工具没有任何控制权,我们对其内容、操作或使用不承担任何责任,也不对你使用此类工具可能产生的任何损失或损害负责。 使用人工智能工具处理个人、敏感或机密信息时请务必谨慎。 你提交的任何数据都可能用于人工智能培训或其他目的。 无法保证你提供的信息将得到安全或保密。 在使用之前,你应该熟悉任何生成式人工智能工具的隐私惯例和使用条款。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine 和相关标志是 Elasticsearch N.V. 的商标、徽标或注册商标。 在美国和其他国家。 所有其他公司和产品名称均为其各自所有者的商标、徽标或注册商标。
原文:Enhancing SRE troubleshooting with the AI Assistant for Observability and your organization's runbooks | Elastic Blog
这篇关于使用 AI Assistant for Observability 和组织的运行手册增强 SRE 故障排除的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





