本文主要是介绍李宏毅-注意力机制详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原视频链接:attention
一. 基本问题分析
1. 模型的input
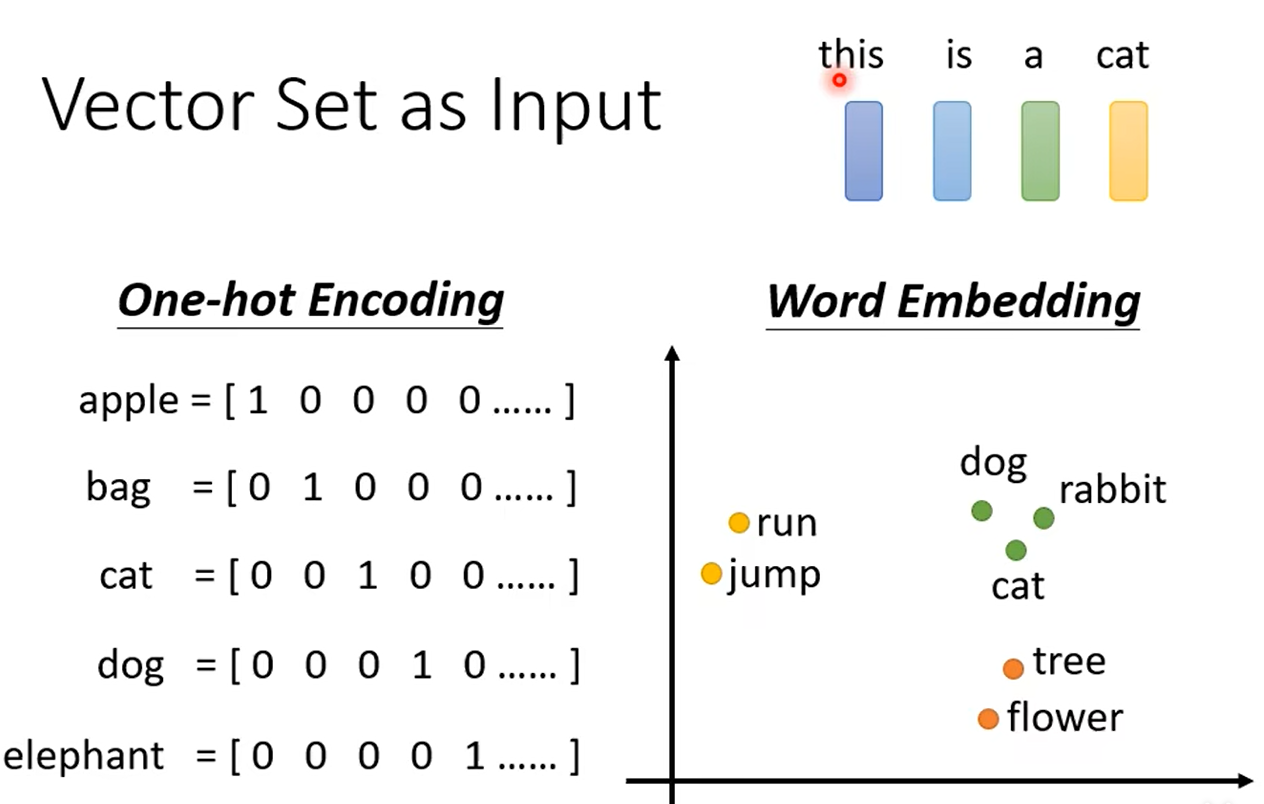
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量,长度可能会不同,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样。解决这个问题的方法是One-hot Encoding以及Word Embedding,其中Word Embedding更能考虑到相似向量的语义信息,如下所示:
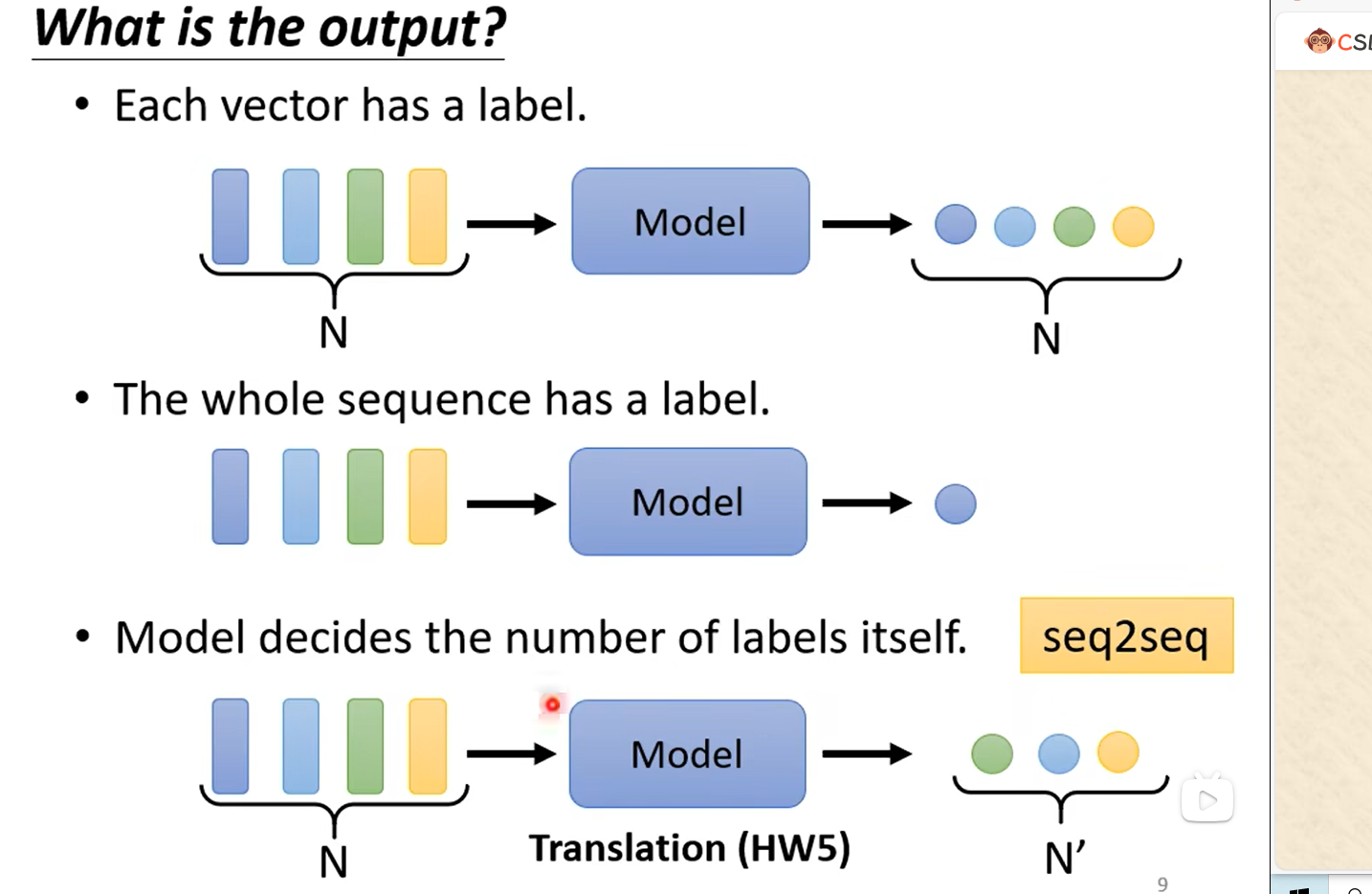
2. 模型的output
输出可以是每个vector都产生个对应的label,即N to N。如:在社交网络中,推荐某个用户商品(这个用户可能会买或者不买);
也可以是N to 1。如:情感分析,给出一句话this is good,输出positive;反之给出另一段消极的话输出negative;
也可以是N to M。如:翻译工作,翻译到另一个语言可能和原语言单词长度不一样
3. attention的引入
比如我们想利用全连接网络,输入一个句子,输出对应单词的标签。当一个句子里出现两个相同的单词,并且它们的词性不同(例如:I saw a saw. 我看见一把锯子),这个时候就需要考虑上下文:利用滑动窗口,每个向量查看窗口中相邻的其他向量的性质。 但是滑动窗口所观看的视野是有限的,窗口增大又会计算量增大,且容易过拟合,这就引出了self-attention机制。
二. self-attention机制
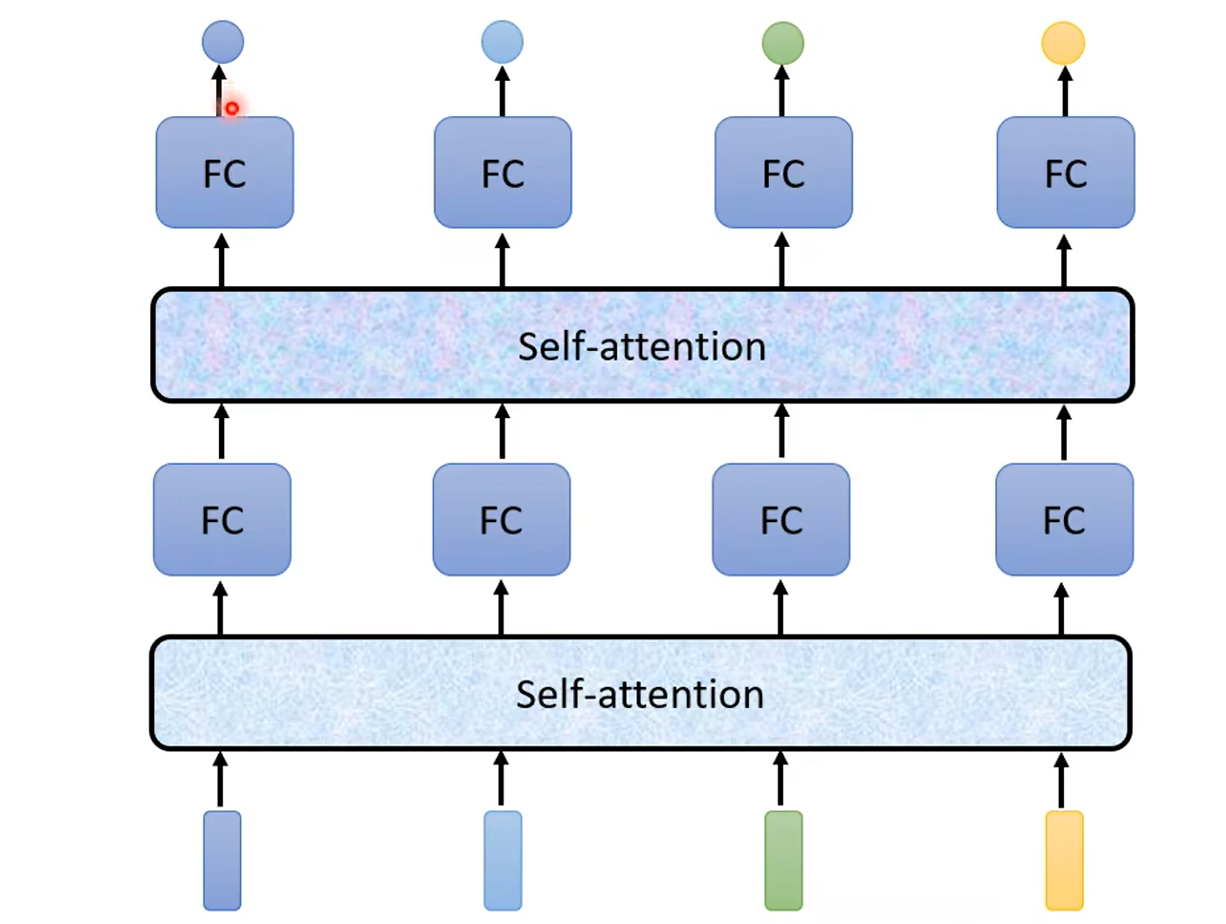
输入整个语句的向量到self-attention中,输出对应单词的向量,再将其结果输入到全连接网络,最后输出标签。以上过程可多次重复,如图所示:
1. 初探“self-attention层”内部机理
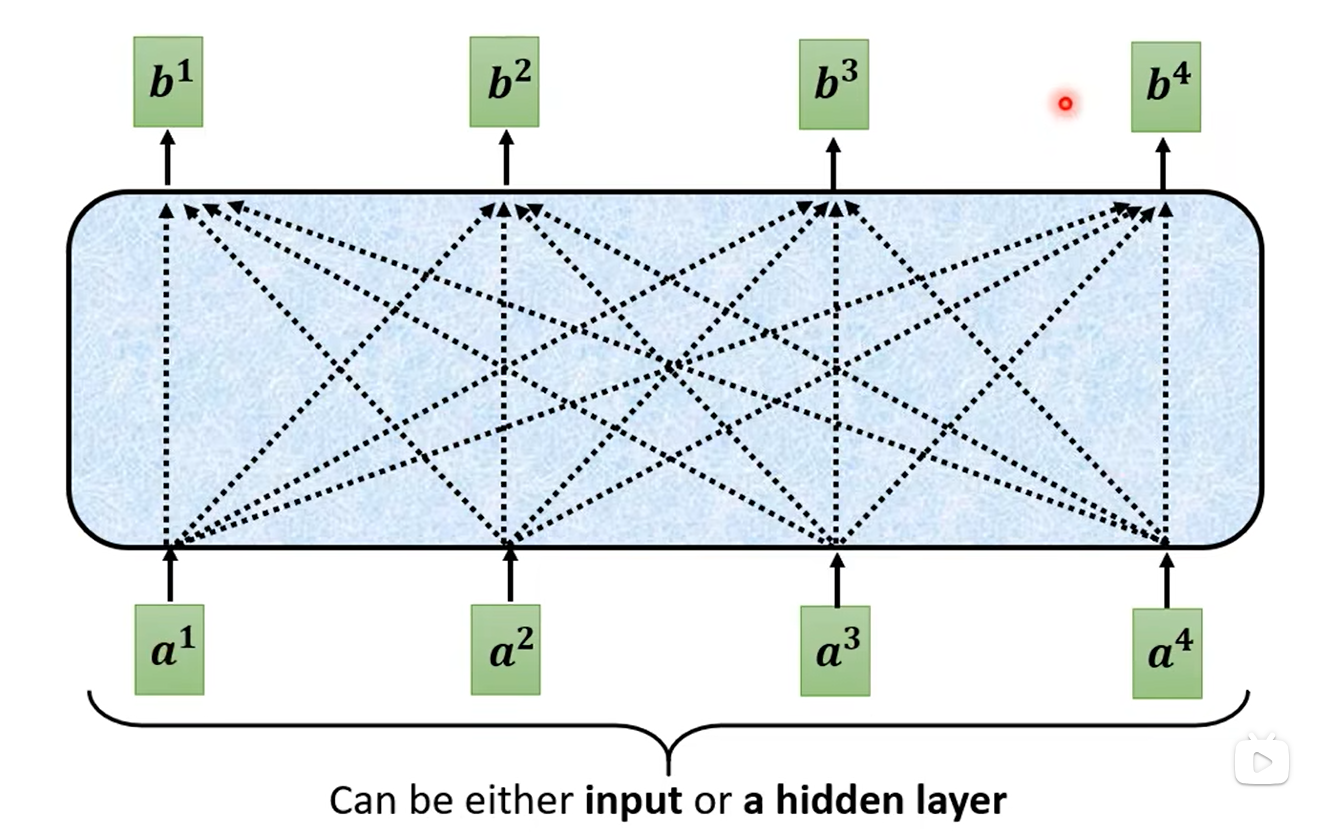
这里的a1-a4可以是输入的向量,也可以是隐藏层的输出,b1-b4都是观察到全局的信息(即a1-a4)才得到的输出,如下所示:
那么这里的b1-b4又是如何产生的呢?b1考虑了a1和这个序列里面哪些是重要的,哪些是次要的。这种重要程度指标通过α表示,即向量之间都有一个相关程度:
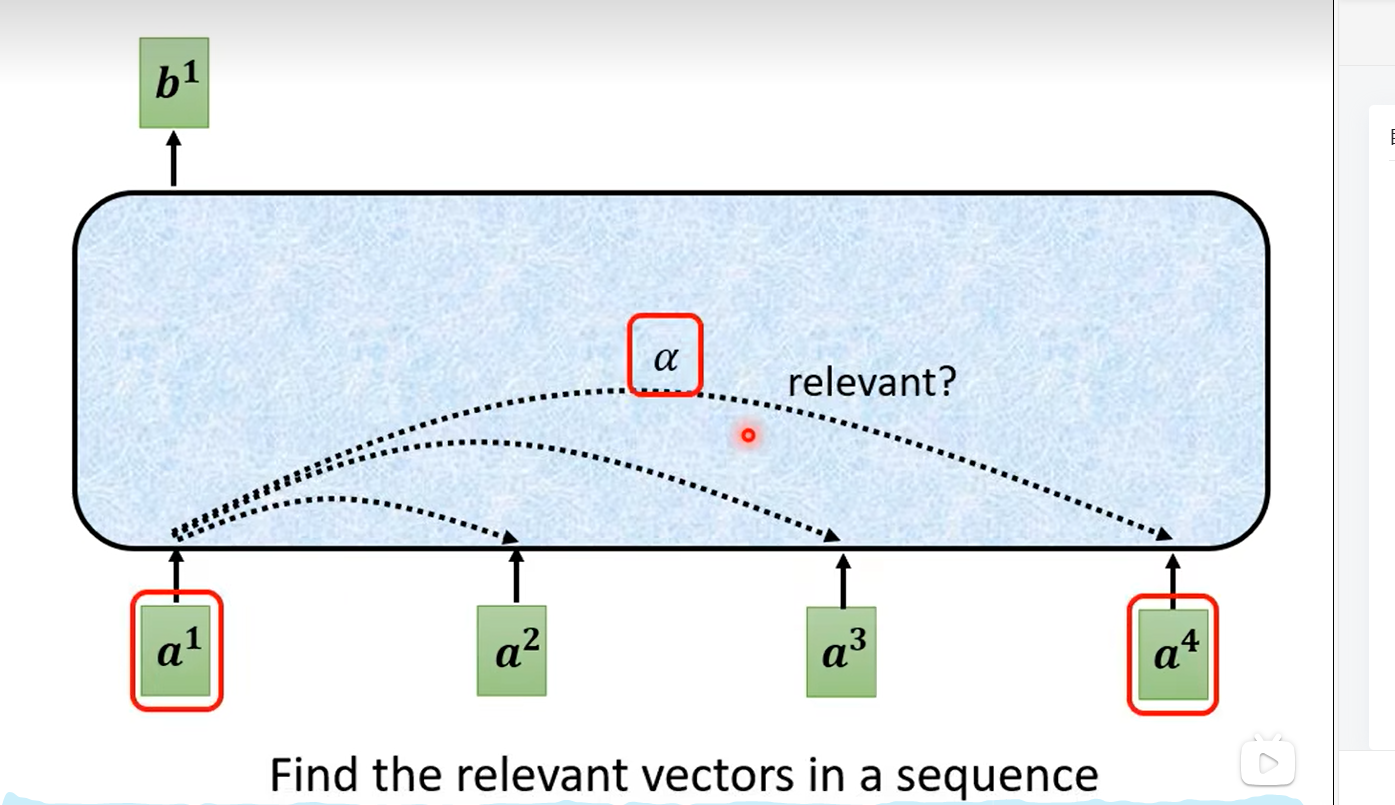
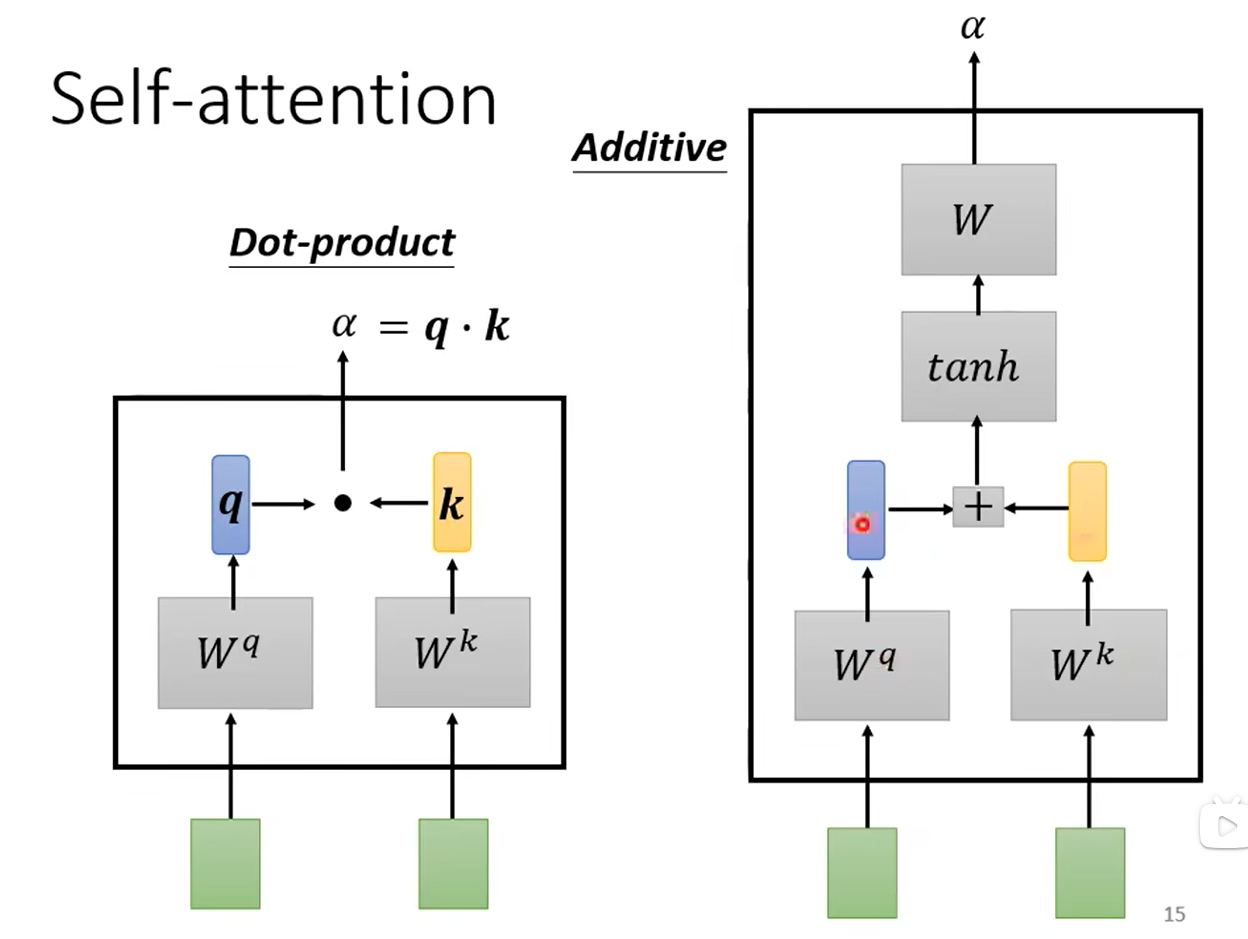
接下来考虑α是如何计算的,下图有两种方法,论文用的是第一种(图左侧),因此着重讲述。继续使用上面的例子,绿色方块代表两个向量a1和a4,我们想计算它们的相关度,将其分别乘上矩阵Wq与Wk(这两个矩阵是通过模型学习学到的)得到向量q与k,再将q与k做内积就得到α了。
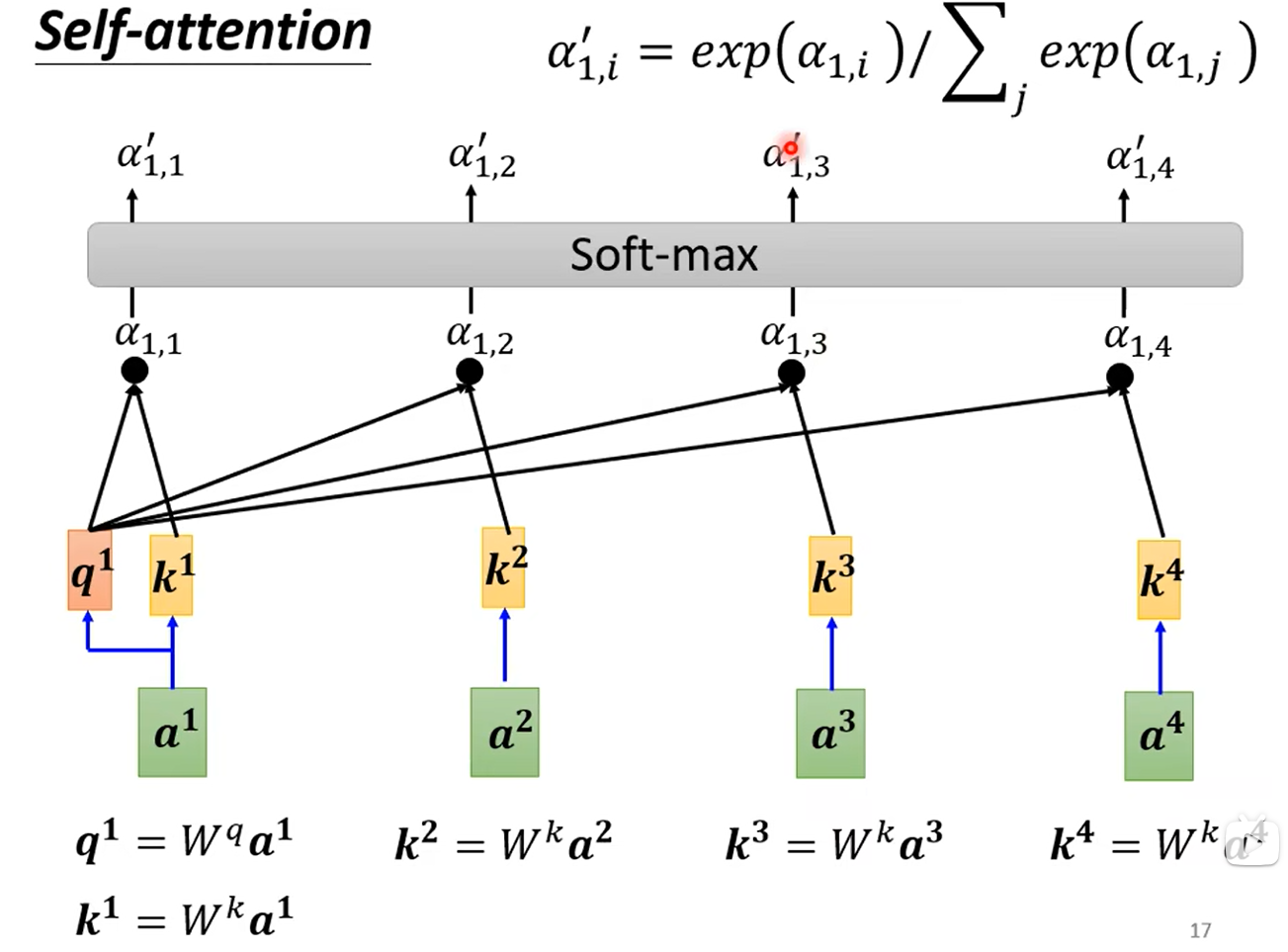
这样我们可以分别计算出a2、a3、a4对应的k2、k3、k4(Wk是这些向量所共享的),我们可以分别计算出a1与a2、a3、a4的相关度α1,2、α1,3、α1,4,当然α1,1是和自己的相关度,也可以算。如下所示:
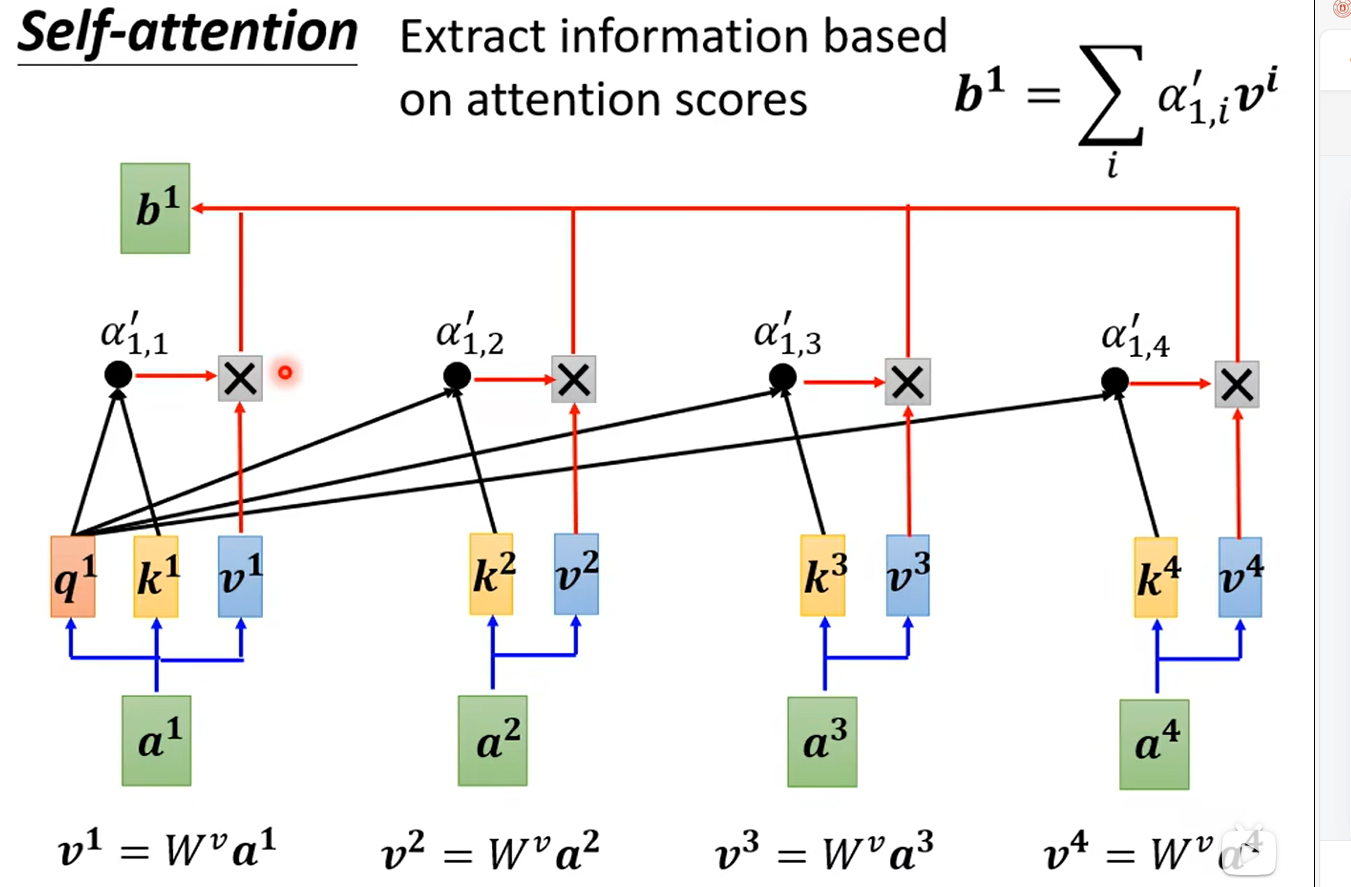
有了α后,我们可以考虑b1-b4的计算了,怎么使用这些α抽取关注的特征呢?我们再引入一个矩阵Wv(同样是学习得到的),分别将a1-a4与Wv相乘得到v1-v4,将v1与α1,1相乘,v2与α1,2相乘...最后相加,即得到了b1。b2、b3、b4是同理的,下图只画出来了b1:
2. 再探“self-attention层”内部机理
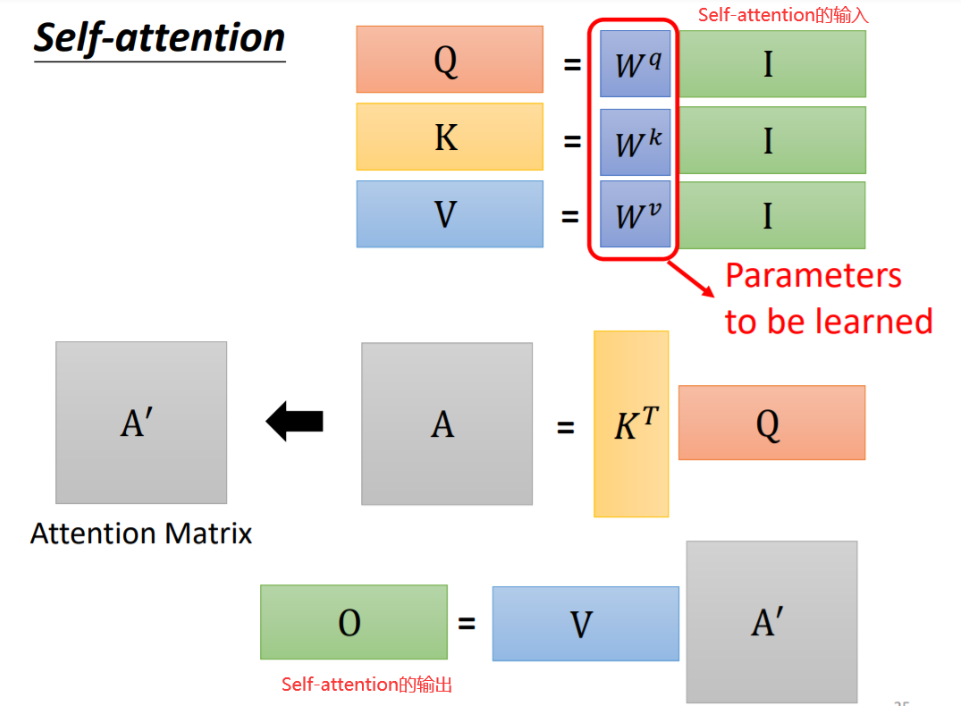
看起来可能复杂,但是实际上涉及的参数只有输入的向量以及Wq、Wk、Wv三个矩阵。运算过程也都是矩阵乘法。我们从矩阵乘法的角度重新理解下,如下图所示,我们将输入向量a1-a4拼起来,分别乘Wq、Wk、Wv即得到了q1-a4、k1-k4、v1-v4:
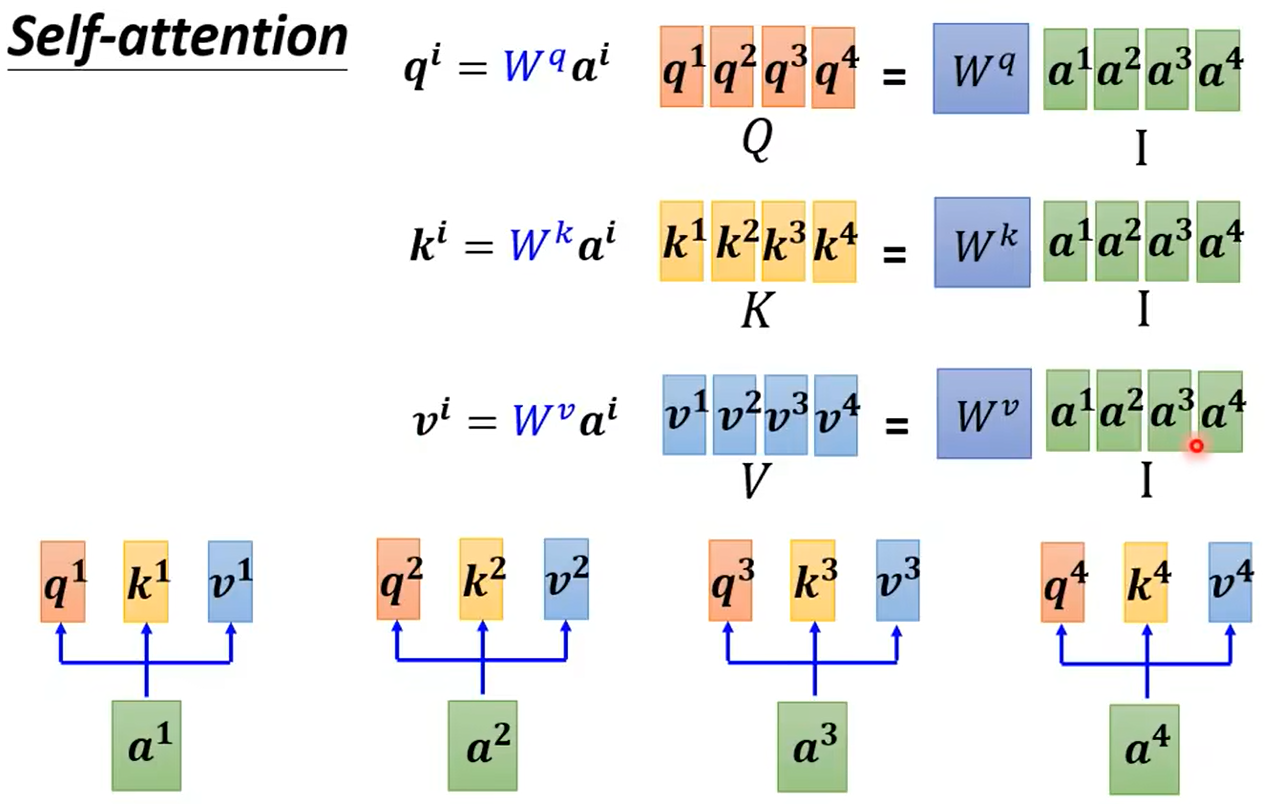
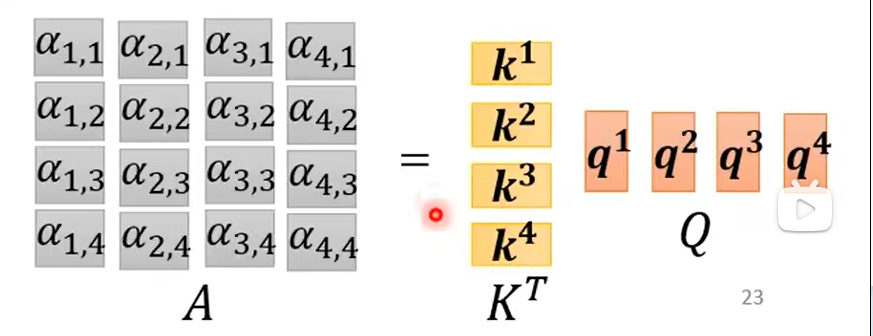
将k1-k4与q1-q4做内积即得到了每个向量与其他三个向量的相关度,如下图所示,例如第一个向量与其他三个向量的相关度为α1,2、α1,3、α1,4,而α1,1代表和自己的相关度:
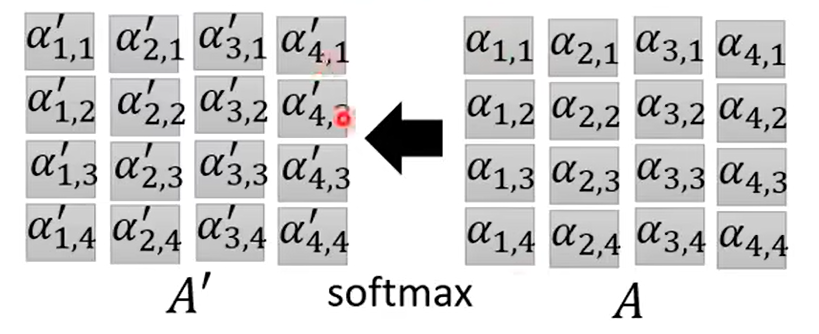
将α组成的矩阵记为A,经过softmax处理一下记为A':
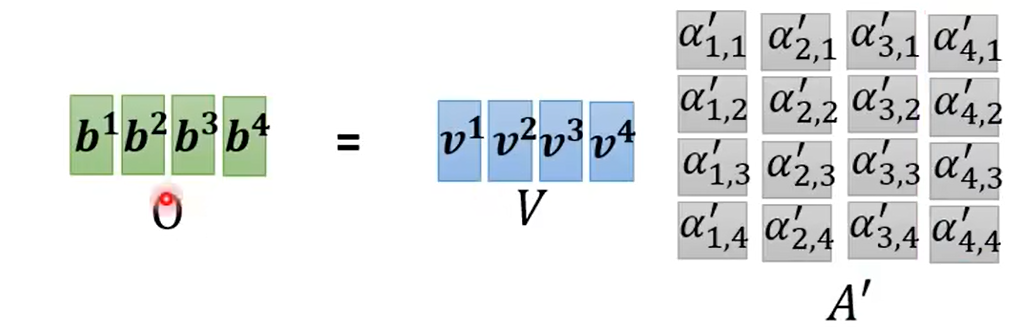
v1-v4组成矩阵V,与A'相乘,根据矩阵乘法,V与A'的第一列相乘再相加的结果即为b1,同理可得b2-b4,b1-b4组成的矩阵就是最终的输出了:
3. 总结
- 阶段1:根据Q和K计算两者的相似性或者相关性
- 阶段2:对第一阶段的原始分值进行归一化处理
- 阶段3:根据权重系数A'对V进行加权求和,得到最终的输出
这篇关于李宏毅-注意力机制详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







