本文主要是介绍30%参数达到92%的表现,大模型稀疏化方法显神通,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当我还是一位懵懂少年的时候,总认为“任务难度”,“参数规模”和“准确率”是一个不可兼顾的三角,比如当我想要挑战更难的任务,追求获得更高的准确率,那必然就要在更大的模型参数量上进行妥协。然而,真的是这样吗?
而在千帆阅尽以后,我才终于开始感悟到,
“小孩子才做选择,成年人全部都要”
论文标题
Enabling High-Sparsity Foundational Llama Models With Efficient Pretraining and Deployment
论文链接
https://arxiv.org/pdf/2405.03594.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
到底怎样才能把你变小
过去我们在做工程优化时,常常会出现这样的一段对话:

由于在量化(quantization)过程中,只保留每个参数的4位或8位数值参与运算,因此不可避免地会带来准确度损失。除了量化以外,权重剪枝(weight pruning)也是一个常见的模型压缩办法,它通过让部分参数为0来提高推理速度。然而,权重剪枝同样面临降准确率的问题,尤其是在面临复杂任务的时候。
今天我们介绍的这篇文章,就致力于在压缩模型的同时,做到保证准确率不会明显下降,真正实现“既要,又要”
方法
稀疏预训练
在此之前,SparseGPT已经实现了在Llama-2 7B上50%的稀疏化,而本文则希望更进一步,实现70%的稀疏化。具体来说,作者采用了迭代方法。首先,他们训练一个50%稀疏的模型直到收敛,然后在此基础上进一步剪枝以获得70%的稀疏性。剪枝后的权重被固定,并且在训练过程中强制执行稀疏掩码以保持稀疏性。
稀疏预训练选择了SlimPajama数据集和The Stack数据集中的Python子集的混合,因为这些数据集经过过滤,能够确保高比例的优质token。
稀疏微调
稀疏微调是在稀疏预训练模型的基础上进行的,旨在进一步提高模型在特定任务上的准确性,同时保持稀疏度。本文在预训练稀疏模型的基础上,采用了SquareHead蒸馏方法,旨在实现每一层上的稀疏微调。
本文评估了以下四种稀疏微调方法:
-
密集微调后一次性剪枝(Dense Fine-Tuning with One-Shot Pruning):先对一个密集模型进行微调,然后在微调数据集上进行一次性剪枝。
-
微调期间剪枝(Pruning During Fine-Tuning):在第一种方法的基础上,对模型进行额外的稀疏微调。
-
从一次性剪枝的模型开始稀疏微调(Sparse Fine-Tuning from One-Shot Pruned Models):先对预训练模型进行剪枝,然后对目标数据集进行稀疏微调。
-
从稀疏预训练模型开始稀疏微调(Sparse Fine-Tuning from Sparse Pretrained Models):从稀疏预训练模型开始,在微调数据集上进行稀疏微调。
此外,文章还发现不同任务类别的准确率恢复模式不同,表明任务复杂性与有效的微调策略之间存在相关性。
-
有限上下文任务:对于有限上下文任务(如算术推理、摘要),微调期间的剪枝通常可以完全恢复,这表明微调数据集已经包含了模型适应所需的大部分信息。
-
大上下文任务:对于大上下文任务(如聊天、代码生成、指令跟随),使用标准微调期间的剪枝进行恢复要困难得多,这表明这些任务更多地依赖于预训练数据集的更广泛知识。
文章证实了,与在微调期间的标准“剪枝”方法相比,稀疏预训练及其后续的稀疏微调方法具有以下优势:
-
高稀疏度下的高恢复率:特别是对于具有大上下文窗口的复杂任务,稀疏预训练方法在高达70%的稀疏度下一致地显示出更高的准确性恢复。
-
简化的超参数搜索:稀疏预训练创建了一个更稳健的基础,有效避免了在微调期间进行剪枝的大范围超参数调节
-
减少计算:通过稀疏预训练,模型通常只需要单次微调即可实现收敛。
基于Cerebras CS-3的稀疏预训练加速
Cerebras CS-3 是专为加速稀疏训练而设计的,它对未结构化稀疏性提供了原生支持。CS-3 的基础是一个完全可编程的处理器,支持通用和专门的张量指令,为不同的工作负载提供了灵活性。同时,与PyTorch的集成也确保了其易用性,允许开发者利用硬件的能力而无需进行大量的代码修改。

由于稀疏矩阵乘法是大模型(LLM)训练的核心操作,CS-3独特的片内存储器(on-chip memory)架构正是为稀疏操作提供了高内存带宽,克服了传统GPU依赖于片外DRAM的限制。CS-3的细粒度数据流执行进一步增强了其稀疏加速能力。在这种范式中,数据本身触发计算。通过过滤掉零值,只有非零数据被处理,带来了功耗节省和性能提升。
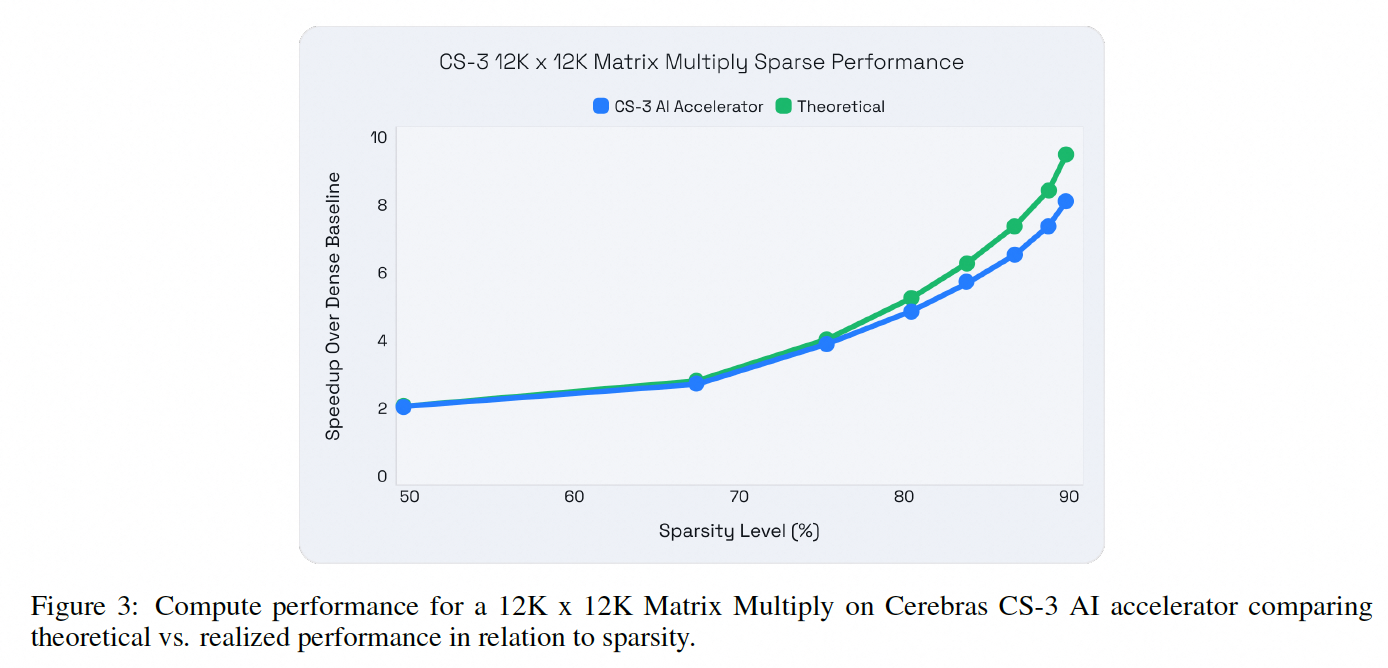
因此理论上基于CS-3的稀疏预训练,会在浮点运算数(FLOPs)显著减少的同时,实现LLM训练性能的显著提升。而实际的性能提升与预期的理论提升非常接近,下图展示了Llama-2在一个示例矩阵乘法上的性能比较。
实验
稀疏预训练实验
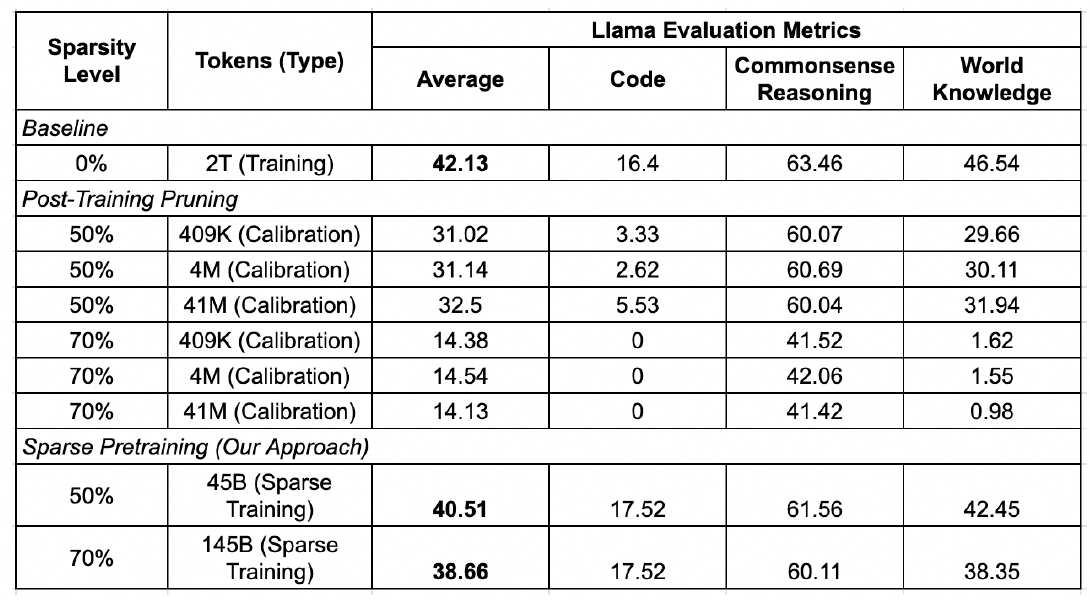
本文在Llama-2 7B上,采用前述稀疏预训练方法进行实验,并度量了模型在“代码生成”,“常识推理”和“世界知识”等通用能力上的效果。与仅进行训练后剪枝(Post-Training Pruning)的方法相比,稀疏预训练方法在50%和70%的稀疏度下都能实现显著更高的准确度恢复,并基本接近基线水平。
有限上下文稀疏微调实验
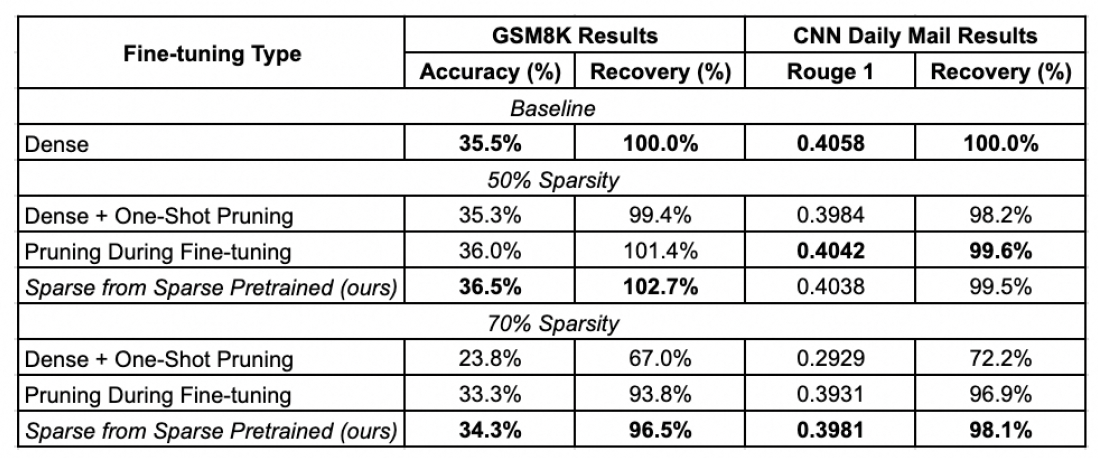
本文选用了GSM8K(计算推理数据集)和CNN Daily Mail(摘要数据集)用于有限上下文场景下稀疏微调效果的测评。在50%和70%的稀疏度下,基于稀疏预训练的稀疏微调方法都实现了接近100%的准确率恢复能力,与当前最先进技术相当甚至更优。
大上下文稀疏微调实验
本文选用了UltraChat200k(聊天数据集),Dolphin和Open Platypus (指令跟随数据集),和Eval Code Alpaca(代码生成数据集)用于大上下文场景下稀疏微调效果的测评。证实了本文方法在高稀疏水平下的效果显著优于其他技术,尤其在70%的稀疏度下超过了所有比较方案。

稀疏量化推理性能
在稀疏微调之后,作者应用了量化技术,并通过SmoothQuant算法、GPTQ算法,和针对顶部5层的层跳过技术,以最小化准确度影响。实验发现,量化方法导致在各项任务中的准确度下降可以忽略不计,INT8数据格式的权重和激活对于实现与DeepSparse引擎的最大兼容性和推理性能增益至关重要。
下图直观地展示通过稀疏化和量化相结合所带来的显著性能提升。与采用FP32格式的基线相比,在CPU机器上观察到以下改进:
预填充性能(Prefill Performance):对于标准512长度的生成任务,首token生成时间最高提速3.86倍 解码性能(Decode Performance):每秒解码token数量最高提升8.6倍
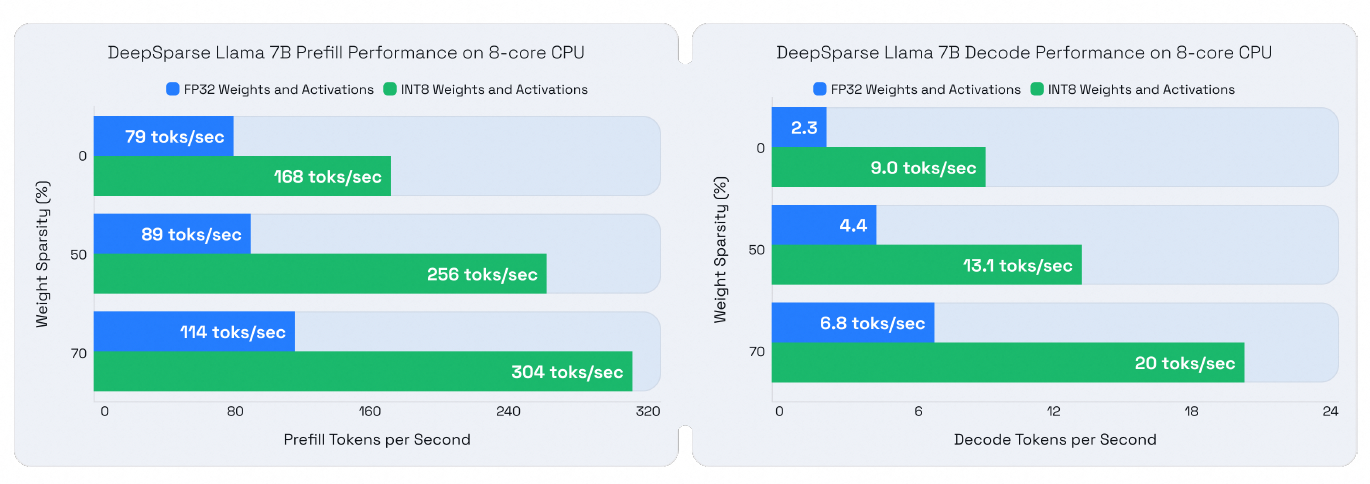
结论与展望
本文提出了一种新的稀疏预训练方法,该方法能够在高达70%的稀疏度下几乎实现微调任务的完全准确度恢复,超越了传统的微调期间剪枝方法。同时利用Cerebras CS-3系统加速了稀疏预训练过程,并通过Neural Magic的软件栈在CPU和GPU上实现了高效的稀疏推理。
在未来,作者将探索使用更大模型的扩展性研究,以验证该方法在更大规模的数据集和模型上依然有效。除了Llama,作者也考虑将稀疏化方法适配到更多新兴的LLM架构中。由于本文验证了稀疏化方法与量化技术结合的有效性,因此作者还将研究更精细的量化技术,如INT4量化,以进一步压缩模型并减少计算需求。此外,如何优化预训练数据集的最佳配比和大小,以提高稀疏模型的性能,也同样是一个值得研究的问题。
结语
嘿嘿,还没有结束,
不知道大家在读这篇文章引言的时候有没有想到一张图,
没错!我当然没有忘掉它!
好了,上图!

最后,祝所有能看到这里的小伙伴,都能在AI探索的道路上,所愿所想即所得。少一些不得已的取舍,多一些经典的那句
“我全都要!!!”


这篇关于30%参数达到92%的表现,大模型稀疏化方法显神通的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



