本文主要是介绍机器学习之特征归一化(normalization),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 引子
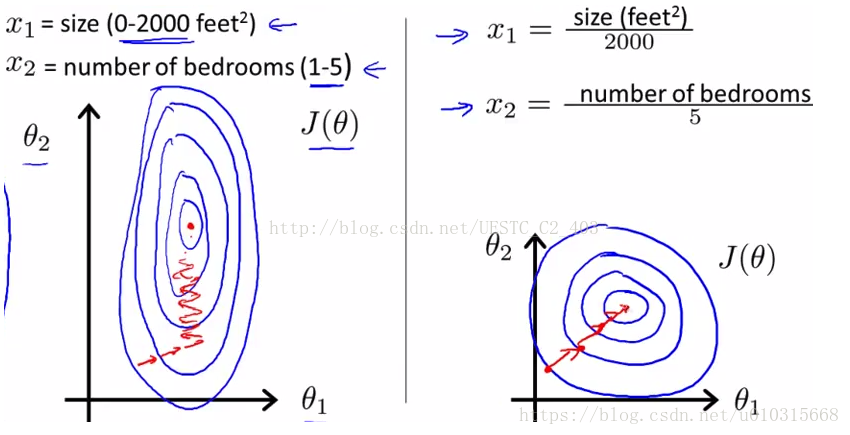
对房屋售价进行预测时,我们的特征仅有房屋面积一项,但是,在实际生活中,卧室数目也一定程度上影响了房屋售价。下面,我们有这样一组训练样本:
| 房屋面积(英尺) | 卧室数量(间) | 售价(美元) |
|---|---|---|
| 2104 | 3 | 399900 |
| 1600 | 3 | 329900 |
| 2400 | 3 | 369000 |
| 1416 | 2 | 232000 |
| 3000 | 4 | 539900 |
| 1985 | 4 | 299900 |
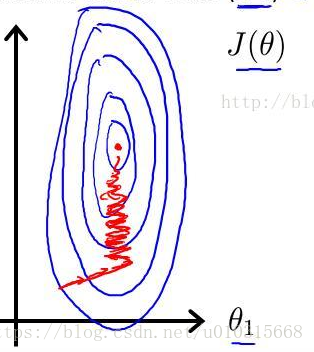
注意到,房屋面积及卧室数量两个特征在数值上差异巨大,如果直接将该样本送入训练,则代价函数的轮廓会是“扁长的”,在找到最优解前,梯度下降的过程不仅是曲折的,也是非常耗时的:
二、机器学习中常用的归一化方法

不同归一化方法分析:
2.1 线性变换和极差法(线性归一化)
将原始数据线性化的方法转换到[0 1]的范围,该方法实现对原始数据的等比例缩放。通过利用变量取值的最大值和最小值(或者最大值)将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级影响,改变变量在分析中的权重来解决不同度量的问题。由于极值化方法在对变量无量纲化过程中仅仅与该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
2.2 标准化方法
即每一变量值与其平均值之差除以该变量的标准差。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异,从而转换后的各变量在聚类分析中的重要性程度是同等看待的。而实际分析中,经常根据各变量在不同单位间取值的差异程度大小来决定其在分析中的重要性程度,差异程度大的其分析权重也相对较大。
2.3 分析
每个维度都是去量纲化的,避免了不同量纲的选取对距离计算产生的巨大影响。在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,第二种方法(Z-score standardization)表现更好。在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
2.4 机器学习中哪些算法可以不做归一化
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。像svm、线性回归之类的最优化问题就需要归一化。决策树属于前者。归一化也是提升算法应用能力的必备能力之一。
2.5归一化对梯度下降的影响
归一化后加快了梯度下降求最优解的速度和有可能提高精度。如下图所示,蓝色的圈圈图代表的是两个特征的等高线。其中左图两个特征X1和X2的区间相差非常大,X1区间是[0,2000],X2区间是[1,5],其所形成的等高线非常尖。当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
三、归一化
该问题的出现是因为我们没有同等程度的看待各个特征,即我们没有将各个特征量化到统一的区间。
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法:
Standardization
Standardization又称为Z-score normalization,量化后的特征将服从标准正态分布:
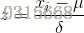
其中,u和delta分别为对应特征的均值和标准差。量化后的特征将分布在[-1, 1]区间。
Min-Max Scaling
Min-Max Scaling又称为Min-Max normalization, 特征量化的公式为:
量化后的特征将分布在区间。
大多数机器学习算法中,会选择Standardization来进行特征缩放,但是,Min-Max Scaling也并非会被弃置一地。在数字图像处理中,像素强度通常就会被量化到[0,1]区间,在一般的神经网络算法中,也会要求特征被量化[0,1]区间。
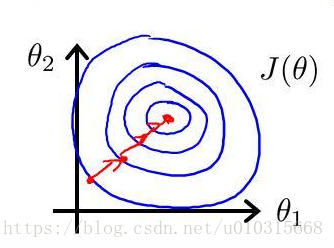
进行了特征缩放以后,代价函数的轮廓会是“偏圆”的,梯度下降过程更加笔直,收敛更快性能因此也得到提升:
# ...
def standardize(X): """特征标准化处理 Args: X: 样本集 Returns: 标准后的样本集 """ m, n = X.shape # 归一化每一个特征 for j in range(n): features = X[:,j] meanVal = features.mean(axis=0) std = features.std(axis=0) if std != 0: X[:, j] = (features-meanVal)/std else X[:, j] = 0 return X def normalize(X): """Min-Max normalization sklearn.preprocess 的MaxMinScalar Args: X: 样本集 Returns: 归一化后的样本集 """ m, n = X.shape # 归一化每一个特征 for j in range(n): features = X[:,j] minVal = features.min(axis=0) maxVal = features.max(axis=0) diff = maxVal - minVal if diff != 0: X[:,j] = (features-minVal)/diff else: X[:,j] = 0 return X
这篇关于机器学习之特征归一化(normalization)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









